This is the multi-page printable view of this section. Click here to print.
2019
- Liters Are Not a Unit of Distance
- Engineering Culture Change with CI
- Removing Drama from Delivery
- Effective Testing
- GitFlow Best Practices
- Designing Product Teams
- You Don't Need Story Points
- What's a User Story?
Liters Are Not a Unit of Distance

One of the most common pain points to anyone moving to modern delivery is, “how do we know we are doing it correctly?” I’d suggest setting measurable goals and frequently verifying if what we are doing is approaching those goals. However, people just starting out with too much new to learn will frequently grab metrics they think they understand and use them in ways that details the goals. This is not an exhaustive list, but they come up frequently.
Velocity
Measuring team productivity by the number of story points delivered each sprint.
Velocity doesn’t measure productivity. Velocity is a measure of the average capacity of the team so that the team can give planning guidance. It’s also exceptionally poorly named.
- Story points are an abstraction to attempt to mitigate how poorly humans are at estimating work. Over time, the team finds that “this kind of work is about this big” and story points stabilize. Smaller work, things that take a day or two, can be estimated in time but only with a team that is practiced at doing that work as a team. This is covered in more detail in In You Don’t Need Story Points.
- Velocity is an average of the number of story points the team has completed in past iterations.
“Given we have completed X story points on average and that we have work that is smaller than X * 80% (or so), then we can predict we’ll probably finish this work in the next iteration unless there are unexpected complications.”

If you ask a team to increase their velocity, they will. Story points will inflate. Some misguided leaders will attempt to standardize the size of a story point. That’s not possible. All they do is translate story points to time and create a math problem for everyone to solve for every story. If you want to do this, just use time. The problem is still there though. If we measure velocity as the number of estimated hours or days delivered in an iteration, then estimates get inflated to show improvement over time.
Productivity is measured by how frequently we can delivery stable changes that deliver value to the end-user.
Agile Maturity Scores
Team Agile Maturity Scores aren’t a thing. That’s a fake metric sold by “Agile” money mills. You don’t observe “maturity” and you never mature. You inspect and adapt. The faster you can deliver, the more you can inspect, and the faster you adapt. There are no defined processes in agile development. There are known good practices that teams should be aware of and adopt as they see fit to improve their ability to deliver. Teams should review and compare their practices to the principles of the Manifesto.
Agile Adoption Rate
This can only be measured by outcomes: delivery frequency, lead time to change, mean time to recover, and change fail rate. Those outcomes show how agile you are. There are surveys some “Agile Transformation” companies use to measure this. Based on those survey’s most teams will be industry leaders in Agile in only weeks or a few months. If someone hands you a maturity survey, find a better source.
We should set improvement goals over time and educate everyone on known good practices that help them reach those goals. Those practices only become their own if they choose them. If told how to work, they do will adopt and they have no route to improve. This is why most “agile transformations” fail. The core culture required is not adopted. “Command and control” is incompatible with improvement. Toyota learned this 50 years ago.
Initiative Milestones
This assumes the initiatives will meet the goals. It’s a blind march to “we did what we said we’d do” without considering feedback on if we should be doing it at all. Instead, we should set product value delivery goals and metrics. “We will reduce the time spent doing X by 50% if we deliver this next feature”. Then reward achieving that. Even more important, reward the behavior of recognizing when that isn’t happening and changing course to a better outcome.
Agile Maturity
This is what agile delivery looks like, the continuous delivery of value to the end-user. The faster a product can close this loop, the higher the quality and the lower the total cost of ownership. Helping the team widen their pipeline by removing waste increases their ability to deliver. Planning deliverables for the next year with set milestones makes this ability almost irrelevant. That legacy process removes learning and improving from the plan.
Measuring correctly is key and metrics must be used wisely or even the right metrics can be destructive. Measure in offsetting groups to prevent gaming. One of the exercises I do is look at metrics and use my software testing brain against them. “What can go wrong? How can I break this? How can I game this to look good?” Then I tell people.
Go forth and use meters for distance. Liters are for volume.
Written on August 16, 2019 by Bryan Finster.
Originally published on Medium
Engineering Culture Change with CI
So, you hired an “Agile Transformation” consulting company to advise executive leadership and you’re “Agile” now. Leadership attended a week-long class on “Agile”, and teams took a two-day class about Scrum being The Way. The new methodology with story points, daily standup, and sprints now reigns, but outcomes haven’t changed. Next, you talk about the “agile mindset” while Scrum Masters report monthly on how much “velocity” has increased. At the team level, the labels have changed, but the processes are the same. Possibly there is less design, but you don’t design solutions in “Agile”. They just “emerge”, right?
What went wrong? Marketing and the desire for silver bullets overtook goals and outcomes. You saw a framework that was popular and bought it without understanding the underlying principles. However, frameworks are solutions that worked for someone else in their context, not yours, and no drive-by “transformation” will result in anything except loss of revenue, frustration, and low satisfaction from both customers and employees. For real change to happen, it needs to be ingrained into the culture. Culture and mindset change requires behavior change. At the team level, we do this with constructive constraints and rapid feedback.
“Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.”
That’s our goal: the continuous delivery of valuable software is our highest priority. That’s the outcome we are after, continuous delivery; CI/CD. We can measure that outcome, apply the correct constraints, and move the culture.
Not Buzzwords
Continuous integration and continuous delivery have measurable outcomes, they aren’t buzzwords. I often hear people use “CI/CD” when they mean build tool automation and don’t even get me started on “DevOps”.
“We’ve created a DevOps team to implement CI/CD pipelines and manage the releases. We’re DevOps now!”

How many of you just cringed?
Continuous integration is behavior, not Jenkins, CircleCI, Travis, or any other tool. CI is how we apply these tools and CI is the key to transforming teams. However, to be effective, we need to be explicit about CI definitions and how we measure our ability to execute.
Ubiquitous Language
Each developer submits tested, backwards compatible changes that are Integrated to the trunk at least once daily.
This definition creates constructive constraints and rapidly uncovers cultural, technical, and process challenges. Asking continuously, “Why can’t we do this?” drives the improvement conversation. The common challenges are basic but take discipline to solve.
- Workflow isn’t managed correctly with too many things in progress, lack of prioritization, and lack of teamwork to drive things to completion.
- Work hasn’t been refined to the detail required to deliver it.
- Testing is manual, requires handoffs to a testing team, or just doesn’t exist.
All of these impact quality and delivery speed. To fix them, we start with some simple improvements.
Establish Policies
Explicit policies are important for keeping everyone aligned. Keep them concise, clear, and always visible. Policies stored on a file share do not exist. Print them and post them.
CI Working Agreement
A working agreement focused on CI highlights the real priority, sustainable delivery of decreasing batch size with high quality and rapid development feedback.
- Fixing a broken build is the team’s highest priority because we cannot fix production with a broken build.
- The team will not go home while the build is broken because it puts production at risk.
- We do not blame team members for broken builds. The team is responsible for hardening the build process against breaks so the team broke the build.
- All branches originate from the trunk and are deleted in less than 24 hours
- All changes must include all relevant tests and may not break existing tests
- Changes are not required to be “feature complete”
- Helping the team complete work in progress is more important than starting new work
- No work may begin before it meets our “definition of ready”
This will not happen on day one. The team should be asking daily, “what’s the main reason we cannot do this?” and apply fixes until they can.
Definition of Ready
For any step, there must be exit criteria to prevent rejection from downstream steps. For refining work, it must be clear enough to prevent questions, guessing about what requirements mean, or gold plating during development.
- Acceptance criteria aligned with the value are agreed to and understood by the team and business
- Dependencies documented and solutions in place to allow delivery without them
- Any required research / training is complete
- Interface contract changes documented
- Component functional tests defined
With these policies in place, the team can begin removing other roadblocks.
Visualize Metrics
Until you know where you are, you cannot chart a path. Metrics are meaningless unless they are always visible. We use Hygieia to monitor CI outcomes, before that, we built Graphana views. No matter what method you choose, current metrics must be kept visible to everyone.
- How frequently are pull requests integrated into the trunk?
- What’s the average branch age?
- How long does it take to fix broken builds?
- How stable is the build?
- Is the build taking too long?
- How many tests are running and is that number increasing?
Track them, gamify them, make them better, and understand the goal is continuous improvement. Metrics are indicators, not goals.
Clear Impediments
Now the real work of changing habits begins. Habits change when previous habits no longer deliver value. When there is no pressure to integrate more frequently, re-refining work in progress doesn’t cause much pain. Integrating code once a week or longer with multi-hour code reviews and regular merge conflicts seems normal and acceptable. With our new drive to deliver code to the trunk daily, things must change.
Improve Refining
Improperly refined work has cascading impacts on quality outcomes. If work isn’t refined to the level of testable acceptance criteria, then there are too many uncertainties, and delivery pressure results in guesswork during development. This impact proper testing since poorly refined work drives developers into a constant “proof of concept” mindset with exploratory coding as the primary flow. It’s very common to see retry loops in a value stream map after development has started where developers are waiting on clarification. This, in turn, incentivizes increased WIP as they pick up new work while they wait and additional delivery delays as they context switch back or just park the original work until the lower priority WIP is completed.
Behavior Driven Development is an important tool for changing the culture and improving outcomes. BDD focuses on collaborating with all stakeholders to uncover the real business needs. Outcomes are owned by all of the stakeholders, not just the developers. We don’t finger point, we problem solve and focus on improvement. We also learn together that we’d rather fail small.
Simplicity — the art of maximizing the amount of work not done — is essential.
BDD gives us declarative, unambiguous acceptance criteria that can be tested. Now we have feature-level functional tests that decompose into component-level functional tests easily identifiable contract changes. We have a much higher level of confidence for what the business wants because they helped us define it and own the outcomes. We also know what NOT to develop since anything we develop beyond what we agreed to is a defect.
With a hard definition of done and clear delivery goals, we can easily swarm the work as a team. Which services will be impacted? Will new services be required? How can we collaborate to deliver those changes as a team?
Improve Testing Process
CI/CD is a quality process, not build automation. In a previous “5 Minute DevOps”, I spoke about the layers of tests required to execute CI/CD correctly. To add to that, two quotes from one of my favorite books.
“It’s interesting to note that having automated tests primarily created and maintained either by QA or an outsourced party is not correlated with IT performance. "
“Automated unit and acceptance tests should be run against every commit to version control to give developers fast feedback on their changes. Developers should be able to run all automated tests on their workstations in order to triage and fix defects.”
Excerpts From: Nicole Forsgren PhD, Jez Humble & Gene Kim. “Accelerate.”
Real CI requires that testing primarily happens before code commit. It also means that manual testing and/or handoffs to a “testing team” now are breaking us. We cannot meet our goals that way. Habits must change.
Since the team defined how the feature will work to a testable level during refining, all that’s required is to implement the tests. Instead of struggling to come up with what to test, developers can spend time designing HOW to most efficiently test against the goal. This results in more downstream improvement.
- Code reviews improve. There is no need to code review for functionality, that’s what tests are for. Code review can focus on readability and verifying that the tests match what was agreed to as a team. The tests validate the new functionality and protect that behavior on every subsequent build. As we reduce the time between merges, changes are smaller and code review is more effective and can be completed in minutes instead of hours.
- The increased confidence that we can make changes without breaking existing features makes development faster. We sleep better at night because we know we can triage and fix things faster at 3:00 am without risking breaking things even more.
- Test suites are less likely to become spaghetti code because we need our tests to run quickly. Test code is code and requires constant design and refactoring. The need for rapid test results helps this happen. Michael Nygard once told me that he created a test that would fail the test suite if it ran for longer than 15 minutes to force the refactoring of the tests. Brilliant.
Workflow Management
Individuals don’t win in business, teams do.
— Sam Walton
Imagine a football team where everyone was measured only by how often they scored. Everyone will be focused on getting the ball, scoring, and being a hero instead of helping the teammate who has the ball. The same happens on a development team.
Have you seen a team where everyone has assigned tasks instead of pulling work or where individuals are measured based on how many tasks they complete? With everyone focused on their task list or making themselves appear to be heroes, they aren’t focused on helping to deliver the next value item. You’ll see this in long wait times on pull requests, cherry-picking low-priority, easy-to-complete work, or increased work in progress. They look busy, but value delivery is minimal.
The teamwork expectations and time box constraints in the CI working agreement along with leadership understanding how to incentivize better outcomes result in lower lead time and increased throughput. The team only looks less busy.
Only Outcomes Matter
Working software is the primary measure of progress.
The customers only care about how quickly they can see value from the next feature. As development leaders, the goal is to help the teams find better ways to deliver value and to align the process in ways that encourage this. CI is an effective way to do this if the correct policies are in place. It provides easily measurable outcomes that allow rapid feedback for any improvement experiment. Because of the level of teamwork required to execute at a high level, it’s also an effective way for a new team to more quickly evolve from “forming” to “performing”. We’ve witnessed this repeatedly.
One note to this: Teams grow and learn as organisms. Team members are not LEGOs. Adding or removing anyone from a team reduces the team’s effectiveness. Team change should be done carefully and infrequently unless improved outcomes aren’t a goal.
Excuses
Some may assert that CI works quite well using an “integration branch” or GitFlow, that integrating every week or once a sprint is fine, or that only complete work should be integrated, I’ve heard all of those excuses before. I’ve also failed that way. Real CI drives real results. Culture changes because the underlying behaviors change. The reverse is never true. Don’t allow a lack of knowledge, lack of testing, or fear to prevent improvement. Fix the problems.
Written on August 5, 2019, by Bryan Finster.
Originally published on Medium
Removing Drama from Delivery

Has this ever happened to you or have you ever seen a support request like this?
“We’re trying to deploy a K8S cluster to our server, but it can’t reach our vLAN network. We’ve opened an incident with the NOC but we can’t solve this issue. We’d like to solve this problem by end of today. if it can’t we’ll be behind schedule and won’t release our new system as planned.
I’d really appreciate if someone could help us.”

Order of Operations
2 x 5 + 3 = 16…
Doing things in the wrong order leads to the wrong answer.
Large projects fail or are challenged because we focus on things in the wrong sequence and not constantly verifying the results. One of the goals of continuous delivery is to make sure the order of operations is correct.
1. Understand the value to be delivered
Developers cannot deliver quality if we don’t understand the value and goals. Context matters.
2. Build and deploy the first feature, “Hello world”
Deploy first. If you cannot deploy, then you cannot deliver the expected value and anything you cannot deploy is unfinished work waste. Even if what you build is entirely correct, if no one can use it or it’s delivered late, it’s still wrong. My first deliverable for any new UI or service is a health-check endpoint returning a simple object or a single line of HTML. Typically, lyrics from “Still Alive”.
3. Build and deploy the next Minimum Viable Feature
In a recent discussion, I explained that services should be deployed to production as soon as any non-breaking changes were available. The challenge back was that “the customer can’t use it yet”. That’s true, but we now have more confidence that it’s not going to immediately break anything when it’s complete enough to use.
Our focus is always stability and hardening the pipeline. We use new features to do that, but we need to keep those features as minimal as possible. Not only does this limit our blast radius when it fails, but it minimizes waste. If the customer asks for something and we deliver towards that goal in small pieces, there comes a point where the customer may be delighted with less than they thought they needed originally or they discover that was the wrong thing to ask for in the first place. In either case, we discover that with the least cost possible.
4. Adjust
It’ll be wrong. We make mistakes in what we ask for, how we define it, and how we implement it. So, we should aim to be minimally wrong. Deploy to production, check against the expected value, and do it again. The faster and smaller we can do this, the more confidence we have in the results.
5. GOTO 3
Picking up the Pieces Sucks
It’s too late to help someone when they’ve already driven off the cliff and are now desperate to find a way to get their months of hard work delivered. All we can do is pick up the pieces and help them understand what went wrong. Keep reminding people about the order of operations, because they may race to the deadline and get 16, but 30 delivers value.
Written on July 5, 2019 by Bryan Finster.
Originally published on Medium
Effective Testing

Protecting the Business
Developer-driven software testing is not new. Studies show that high-performing organizations depend on tests written by developers instead of handing off to external teams of “Test Automators”. Many vendors sell The One Test Tool to Rule Them All and promise to take the thought out of testing. I’ve seen repeated demos of tools with slick UIs designed to dazzle those with budget control that promise to make testing so easy that even external contractors with no context can do it. I’ve been told that only unit tests are the responsibility of the development team. I have even heard that for developer productivity testing should be given to testing teams because, “developers have better things to do and aren’t qualified to test anyway”. Wow!
These misguided beliefs put the business at risk. Customers do not care about anything but outcomes and the data is on the side of better outcomes coming from DevOps principles and the practices of CI/CD. Tools don’t solve that. Skilled, professional developers using effective tools do.
CI/CD == Test
For anyone wishing to master CI/CD, there are few areas of study more important than the effective use of metrics and testing.
The entire point of a CD pipeline is to safely deliver value continuously to our end users. Code must prove to the pipeline that it is worthy of delivery and the pipeline’s job is to prevent that delivery unless worth is proved and as fast as possible. To enable this, a product team should have the following priorities:
- Build and harden the CD pipeline.
- Keep the pipeline green. If there is a broken build, drop everything and fix it. If you cannot ship, nothing else you are working on matters anyway. Make sure that change can be delivered on demand to protect the ability to fix production without heroics.
- When (not if) a defect penetrates, harden the pipeline further by designing additional efficient tests for that defect.
- Write features and ship them daily to continuously test our ability to fix production with minimal MTTR.
- Get feedback about the status of the changes as fast as possible.
CI/CD is not tools. It’s how we USE the tools. If you are claiming to execute a CD process, then the following are true.
- All tests for any code change are implemented and verified before code is committed in version control. Test Driven Development is a good idea. Test DURING Development is a non-negotiable.
- There is only a single path to production for any code change, no matter how critical. We always use our emergency process and we always test the same way.
- Tests version with the code.
- Test may not be deactivated for an emergency.
- While there may be a button to push to deliver to production, there are no other manual stage gates, human intervention, or handoffs to external teams once code has passed code review.
If the above are not true, it doesn’t matter how well you can script Jenkins or how much you pay a testing team. You will never attain sustainable quality and you will be risking the business during every change, especially during an emergency.
The secret to CD is the right mindset: it’s always an emergency. We architect the pipeline to standardize work and remove manual touch points because at 3:00am when a dumpster fire is raging in production, VP’s are breathing down are necks, and we are operating on coffee and terror, we don’t want to forget steps in our “hotfix process”. We only use our standard process. It’s already a nightmare, so let’s not make it worse by cowboying changes in, ok?
All of the above have implications to how we architect our test plan.
Building a Resilient Test Plan
Your test suite needs to be hardened against the realities of the chaotic world. In a fantasy testing world, networks never have latency, external dependencies are always up and always stable, and the teams who own those dependencies never deploy breaking API changes without versioning. It’s fine to assume everything will work perfectly, until it’s an emergency and your assumptions are sadly mistaken. You MUST trust your tests. You must not accept random failures in your tests. Your critical path pipeline tests must work even when everything around you is falling apart.
The Table Stakes: Solid Unit Tests
Unit tests are absolutely the foundation. They are also where most developers stop. While unit tests are crucial, they need to be used for the correct purpose; black box testing of complicated, isolated units of code. Typically, we are talking about classes, methods, or functions at this level. For architecting a Continuous Delivery test suite, we want it to be fast and efficient. We want to target testing at risky behaviors. 100% code coverage is neither reasonable nor efficient. There’s no purpose in testing things like getter and setter methods unless they are doing something interesting. Testing Java’s ability to assign data to a variable isn’t useful unless we are developing the JVM. There are libraries full of good information on patterns and anti-patterns for unit testing. A favorite is xUnit Test Patterns. It’s a massive tome on proper testing and common anti-patterns that I highly recommend.
Meeting the Business Goals: Functional Tests
Unit testing will give a good view of how individual units will perform, but most applications are implementing some business flow. Testing that core business domain logic is critical and unit tests are ineffective at that. Many teams will jump immediately to End-to-End testing to solve this, but those are unstable (flakey test anti-pattern) and cannot effectively test all of the logic branches.
A better approach is using functional tests that independently test each business feature.
“Given I have £20 in the bank When I ask the cash machine for £20 Then it should give me £20 And debit my account.”
Excerpt From:Liz Keogh. “Behaviour-Driven Development.”
Here we have a single business feature that can be implemented by an account service. This takes no special tools to implement, only the thought process of “I need to test this flow”. Just like a good unit test, each functional test should be focused, be able to run in parallel, and should not directly integrate ouside the scope of the test.
Being a Good API Citizen: API Contract Tests
Communication interfaces are where most defects occur. It’s obvious then that we should prioritize testing those interfaces even before implementing the behavior behind them. This is where contract testing and contact driven development become important.
There are many poor ways of documenting API contracts, but only one correct way: contract tests and contract mocks documented and tested by the provider. A contract test in its basic form is a simple unit test of the shape of the contract.
Here’s a simple example:
404: Not Found
Playing Well With Others: Integration Tests
Contract tests give you a level of confidence during CI builds that you’ve not broken a contract or broken how you consume one but since they are mocked, they require another layer of test to validate the mocks.
Many people will use “Integration Test” to refer to the activity of testing business flows through several components, and End-to-End tests. Others use it to refer to the functional test I mentioned above. In the references I mention below, they will refer to integration testing as the act of verifying communication paths between components; a shallow test where the consumer asks, “Can I understand the response from my dependency?” The test should not attempt to test the behavior of the dependency, only that the response is understandable.
Integration tests have a weakness that architects of CD pipelines need to understand: they are flakey. You cannot promise that the dependency will be available when the CD flow executes. If that dependency is not available, it’s still your team’s responsibility to deliver. Remember the rules of CD above. You are not allowed to bypass tests to deliver. So, we have a conflict. How do we design a solution?
Step 1: Service Virtualization. Using Wiremock, Mountebank, or other related tools we can virtually integrate. These tools can act as proxies for actual dependencies and the better ones can replicate latency and handle more than just HTTP. In addition, they reduce the need for the test data management that is required for all but the simplest integration tests. Data is the hardest thing to handle in a test, so avoid it.
Step 2: Scheduled integration tests. When direct integration testing is needed, run it on a schedule outside the standard flow. Build alerts to tell you when it breaks and follow up on the causes for the breaks. If the dependency is unstable, keep track of how so you can rapidly detect when it’s their instability vs. a breaking change they made or a problem with your virtual integration tests that needs addressing.
Using this method, you can reduce much of the flakiness of typical integration testing as well as repeatedly and quickly test for complex scenarios that cannot effectively be tested with less refined methods.
Verifying User Journeys: End-to-End Test
End-to-End testing tests for a flow of information and behavior across multiple components. Beware of vendors selling record and replay testing tools that purport to take the load off of the developer by simply testing the entire system this way. However…
The main problem with Recorded Tests is the level of granularity they record. Most commercial tools record actions at the user interface (UI) element level, which results in Fragile Tests
Excerpt From: Gerard Meszaros. “xUnit Test Patterns: Refactoring Test Code**
End-to-End tests are not a substitution for properly layered tests. They lack the granularity and data control required for effective testing. A proper E2E test will be focused on a few happy path flows to verify a user journey through the application. Expanding the scope of an E2E into the domains better covered by other test layers results in the slow and unreliable tests. This is made worse if the responsibility is handed off to an external test team.
What Didn’t We Test?
Exploratory testing is needed to discover the things that we didn’t think of to test. We’ll never think of everything, so it’s important to have people on the team who are skilled at breaking things and continuously trying to break things so that tests for those breaks can be added. Yes, this is manual exploration but it’s not acceptance testing. If you use a checklist, you’re doing it wrong.
Will it Really Operate?
Load testing and performance testing shouldn’t be things left to the end. You should be standing those up and executing them continuously. There’s nothing worse than believing everything is fine and then failing when someone tries to use it. Operational stability is your first feature, not an afterthought.
Entropy Happens
- What if that critical dependency isn’t available?
- What happens if it sends you garbage?
- Cloud provider reboots for an upgrade or has an outage?
- Excessive latency?
- Coronal Mass Ejection?
The world is a messy place. Resiliency testing verifies that you can handle the mess in the best way possible. Design for graceful degradation of service and then test for it.
Testing Ain’t Easy
Proper testing takes the right mindset and at least as much design as production code. It takes a curious, sometimes evil, mind and the ability to ponder “what if?” Proper test engineers don’t test code for you; they help you test better. Tests should be fast, efficient, and should fully document the behavior of your application because tests are the only reliable documentation. If you aren’t confident in your ability to test every layer, study it. It’s not an added extra that delays delivery. It’s the job.
If you’re a professional developer and student of your craft, here’s more references for deeper learning:
- Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations
- Continuous Delivery
- Practical Test Pyramid
- xUnit Test Patterns
- Charting a path to software resiliency
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on Feedback is always welcome.
Written on June 18, 2019 by Bryan Finster.
Originally published on Medium
GitFlow Best Practices
I was asked recently about the best practice for using GitFlow with continuous integration. For those who do not know, this is GitFlow:
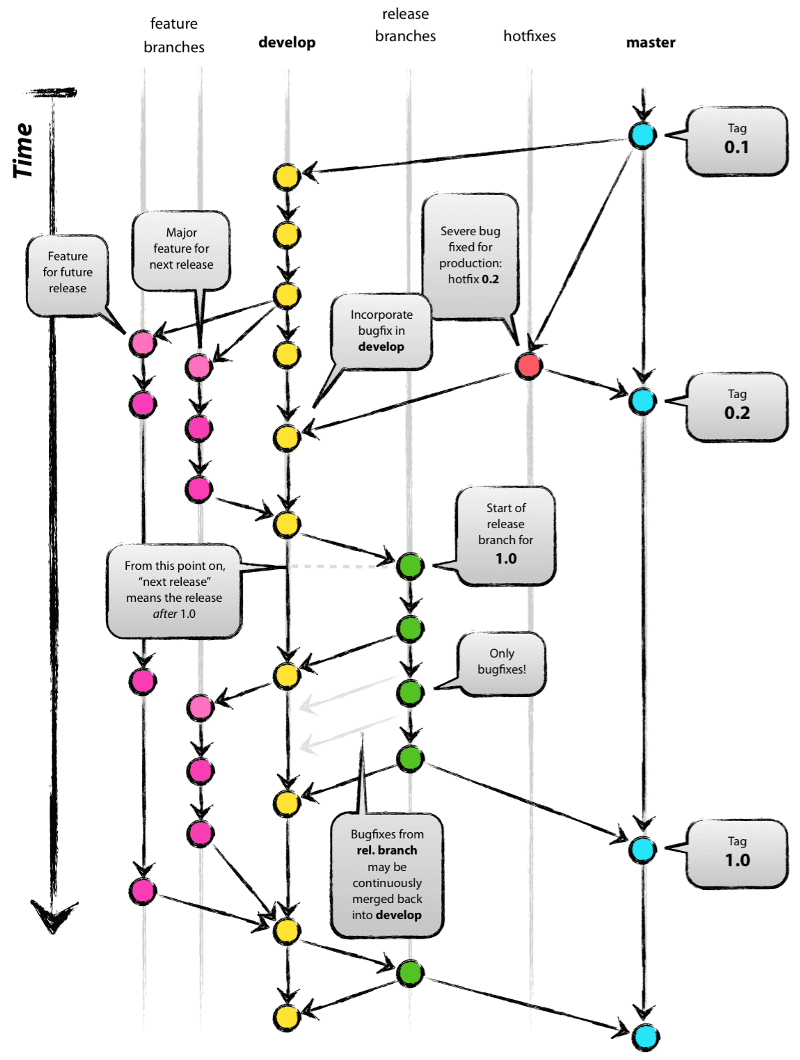
There is no CI good practice that includes GitFlow. For continuous integration to meet the definition, these are the good practices:
- Developers must implement all tests before they commit code. This is a non-negotiable and I will not work with developers who refuse to test. Professionals deliver working, tested code. Script kiddies don’t test.
- Stand up CI automation and trigger builds for every pull request so that bad changes can be rejected.
- Ensure that all tests are executed and linting and static code analysis is done for every PR.
- Implement CI practices. All developers branch from the trunk, make changes, and submit PRs back to the trunk. The branches are removed in less than 24 hours.
You’re now doing Trunk Based Development. Welcome to your CI/CD journey!
The complexity of the CI automation will depend on how poorly the application is architected and the size of the development team. Monoliths with poor sub-domain boundaries will require much more complicated test design and test execution will take much longer. Evolve The architecture into independent, loosely coupled sub-domains to improve delivery speed, reduce testing overhead, and improve stability, resilience, and scalability.
GitFlow does not increase quality or value delivery. It delays quality signal feedback to the developers, incentivizes manual processes, and is incredibly wasteful of time and resources. No modern development uses it.
Some developers have a religion built around GitFlow because it reduces typing (no feature flags needed, no branch by abstraction cleanup, etc.) and they don’t track their levels of re-work, lost changes, or conflict resolution. In 2010, GitFlow felt good. We could keep Master “clean”. That was almost a decade ago. Testing was still mostly manual. We were still on Java 6. NodeJS was barely a thing. Time to modernize. We don’t keep Master clean with added process. We keep it clean with automation.
Other examples:
Update March 2020: I asked the author of GitFlow if he could clarify the use cases to stop the GitFlow whack-a-mole and he very helpfully did so, Please thank him.
**Update September 2021:**A friend recently joined Atlassian and I asked if he could get them to update their GitFlow docs. They did.
Written on April 6, 2019 by Bryan Finster.
Originally published on Medium
Designing Product Teams
What does a product team really looks like? You’ll hear lots of DevOps-y buzz words: “T-shaped people”, “cross-functional”, or “Two Pizza Team”. So, what is a viable product team and what are some common team anti-patterns?
First, a personal irritant of mine.
<rant>
Please stop saying "DevOps team." DevOps isn't a job. If you have a "DevOps team" doing release management or support
for you, spend time educating people on flow, feedback, and learning.
</rant>
Now that we’ve cleared that up, a product team has a few recognizable traits:
Cross-functional:
The team contains the skills and tools to allow them to build, deploy, monitor, and operate their portion of a product until the day when it is turned off. Team members have no individual responsibility for components, instead they pull work from the backlog in priority sequence. The team is not dependent on any outside dependencies, either technical, informational, or process, to deploy their product. If there are hand-offs then quality is reduced, MTTR will be too high, and the team will not feel the pride in ownership required for quality outcomes.
Anti-pattern: Release management team
Having another team responsible for deploying code prevents the product team from committing to deliverables and increases MTTR. It also makes release challenges opaque and prevents the team from improving their delivery flow effectively.
Anti-pattern: External QA
Outsourcing testing reduces quality and delays delivery. QA should be inherent in the team and should assist developers with test suite design to enable feedback from CI builds in less than 10 minutes.
Sole Source Ownership
The team has sole ownership and commit access to their repositories. This does not imply that the repositories should be private. Repositories should be openly readable unless there is a security risk. Teams need veto power over any change made by an outside contributor to make sure those changes meet the team’s standard of quality. Quality is owned by the team. Larger products should be divided among teams in a way that allows each team to have sole quality responsibility.
Anti-pattern: Shared source repositories
Everyone who has the ability to modify a repository directly is the de-factoteam. If that team is broken up into smaller “teams”, then process and communication drag will impact quality and the ability to deliver with agility. CI will not function and quality standards will be impossible to enforce. Delivery is delayed as process overhead increases in a failed attempt to overcome this structural problem.
Co-located in Time
The team works a schedule that enables them to effectively collaborate. They need not be co-located physically, but they must have enough overlap in working hours to allow a sustainable continuous integration process. Paul Hammant has an excellent article on evaluating your CI process. As the amount of overlapping working hours decreases, the communications lag between team members effectively silos the team. Team members will naturally divide into sub-teams who can collaborate together to deliver. Remote teams should be in frequent contact to avoid this fragmentation. The team needs to stabilize around working hours that support CI and protect value delivery.
Anti-pattern: Teams siloed in time
CI is the core of continuous delivery and requires a high degree of collaboration. The feedback loops needed to move value from idea to production must be as rapid as possible. If a team is divided in time in a way that they cannot effectively communicate instantly for a majority of their day, they become de-facto separate teams. These “teams” do not have sole quality ownership and delivery times will be extended as the “teams” adjust by adding process overhead that allows both “teams” to review the code. Over time, the sub-team cultures evolve independently and impact code review cycle time. Innersourcing processes can mitigate the quality issues by making only one of the teams a contributor instead of owners, but there is an increase in process overhead.
Responsible
The team has primary support responsibility. There are only two groups related to any product who care about the quality of that product, the end users and the product team who wakes up when things break. A high performing product team will ensure that their application has the resiliency, instrumentation, and alerting required to detect pending failure before the end user detects it.
Anti-pattern: Grenade Driven Development
Project teams require support teams to hand the project off to. Project teams are ephemeral. This type of development practice where code is developed and “thrown over the wall” for another team to support is destructive to the product and to the morale of the victim team. Product teams, by definition, have operational responsibility. They may not be the first people called, but only they can approve changes to their code. It’s up to them to make sure Operations has the information needed to alert the team effectively.
If the above principles are not true, it’s not a product team. It’s merely a “Pandemonium of Developers”.
Other considerations
Having a cross-functional, co-located, responsible team with ownership is a good start, but it’s only part of the problem. To keep deliverables fast, cheap, and high quality, it’s important to minimize inter-team dependencies. Teams need to deliver independently in any sequence. This takes planning before we form a team. What is our desired architecture? Which functional domain will each team be responsible for? Things become more complicated here because, like many other things in application design, “it depends”. It also requires technical skills from the team with a focus on API management, Contract Driven Development, and an understanding of effective feature toggles.
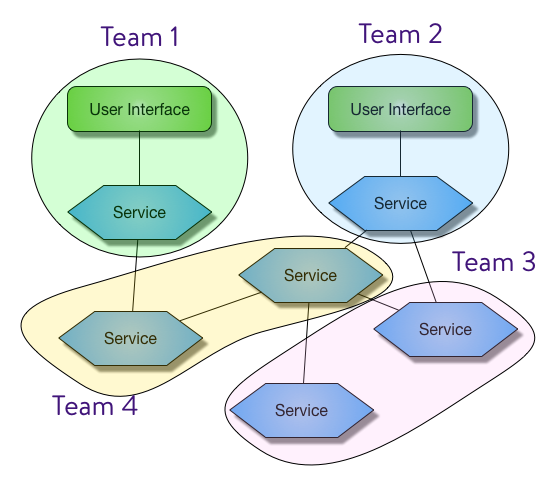
Functional Domain
Domain Driven Design isn’t just a good idea, it’s an excellent way to align teams. As we decompose a product into sub-domains or as more functional domains emerge, we should be deliberate about assigning those capabilities. Things that should be tightly coupled should be assigned to the same team. Things that should be loosely coupled should be separated. If I’m using a back end for front end pattern, the UI and the service should absolutely be on the same team. Otherwise, the dependency drag for implementing any change will result in glacial delivery. If I also need the capability of tracking account transactions, I can easily assign that to another team and allow them to develop that solution independently. In that case, we assign the capability based on capacity planning.
Desired Architecture
The impact of placing two capabilities on one team is that they will tend to become entangled. That can be as simple as becoming a single deployable or as complicated as functionality drifting across interface boundaries. If the capabilities are closely related, this can be an advantage. Combining them into fewer deployable artifacts can result in less operational overhead. Microservices aren’t always the answer (avoid Conference Driven Development). However, if the capabilities are unrelated and things start to merge, you’ll need to invest in marinara before you tackle refactoring the resulting spaghetti.
Vertical or Horizontal?
“Do we create a UI team and one or more service teams? Do we divide the UI across teams?”
Take a look at your wireframes. Are there discrete functional domains represented in the UI? A component for showing stock prices, one for showing account balances, and another for scheduling bill payments? Those can easily be developed in functional pillars and developed and deployed independently. Aligning teams to a business domain instead of the tech stack removes hard dependencies to feature delivery and allows the teams to become truly full-stack. Not only do the know the full technical stack, but they also own the entire problem they are solving. They know the business stack.
This isn’t always possible and it does sometimes make sense to have a UI team, but that should be a fallback position. Better outcomes come from a team who is expert in their business domain.
Is it really a team?
Product teams deliver quality. They care about their team, their product, and their ability to meet the needs of the customer. Random assemblages of developers taking orders do not. It falls to technical leaders to know the difference and to optimize teams for delivering business value. Grow your product teams. They are a strategic business asset that are required to compete in the current market. Happy developers with tight collaboration who are experts in their problem space can work miracles. “Development resources” do not.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author! ⬇
Written on February 7, 2019 by Bryan Finster.
Originally published on Medium
You Don't Need Story Points
In my last 5 Minute DevOps, I attempted to define user stories in a testable way. Real developers should test, after all. Now that we have a story, how do we communicate when it can ship?
We have a long history of attempting to communicate the uncertainty of outcomes to non-technical stakeholders. We speak in delivery probabilities, not certainty. It can be frustrating to those who don’t understand, but software development is not cookie cutter and managing expectations is key when uncertainty is high.
T-shirt sizing, ideal days, and story points have all been used in an attempt to communicate how complicated or complex something is and our certainty of the date range we can deliver on. However, the issue they all share is that they leave much to interpretation. This in turn leads to hope creep as stakeholders start planning optimistic dates.
Story points are particularly troublesome. Teams just starting out will equate story points to hours or days. External stakeholders will do the same. Managers will try to “normalize” story points to compare teams’ relative productivity with their velocity, a staggeringly poor metric. In the end, no one sees any real value.
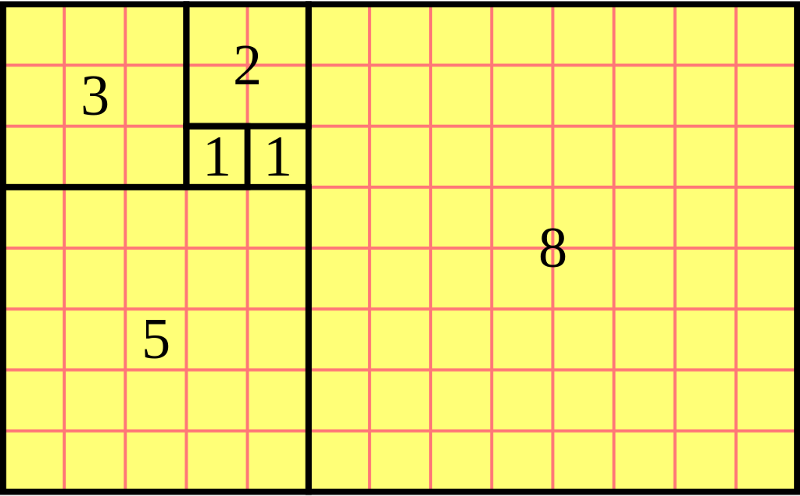
So, what is a story point really? It’s a statement of relative size and complexity compared to a task the team understands and can estimate. You cannot “normalize” them because no two teams have the same knowledge or experience. The bigger the story point size, the less certain and more complex. Uncertainty also isn’t linear. We use the Fibonacci sequence because it increases with the square of the number.
That clear? Good. Now forget it because no value is delivered by continuously improving how we “point” or by spending time in meetings voting on how many story points something is. Time is much better spent in extracting the real requirements by decomposing the work into tasks that can be delivered tomorrow.
One of the key practices of DevOps is decreasing batch size. Not only does this accelerate value delivery, but also reduces the blast radius when we get things wrong. Small change == small risk.
Paul Hammant argues that most stories should be sliced to one day. If you cannot, then you have the wrong people, wrong tech stack, wrong architecture, or just poor story slicing skills. In my experience, all stories can be sliced to less than three days. Any estimate becomes shaky after two. The benefits to clarity of purpose, speed to market, and predictable delivery demand that we aim for small stories.
We’ve seen good results following this process. Small stories make requirements clear, deliver predictably, and resist gold plating, scope creep, and sunk cost fallacy. If we agree that a story can be delivered in two days, on day three we know there’s a problem we need to swarm. If a story is 5 “story points” it’s probably at least a week’s work and we’ll find out in the middle of week two that it’s late, if we are lucky.
Forget story points.
A skilled team can slice stories so that everything is a “1” or a “2”. At that point, all we need do is agree as a team a story can be done in that time range and track the throughput of cards. Anything else is focused on ceremony instead delivery.
If you are using story points, you need to focus less on getting better at “pointing” and focus more on what really delivers value. Decompose work and ship it.
Next time: Are You a Professional Developer?
Written on January 31, 2019 by Bryan Finster.
Originally published on Medium
What's a User Story?
What is Pragmatic DevOps? It’s just a catchy way of saying we deliver with Minimum Viable Process using lean techniques to drive waste out of the system. If it helps us deliver and support our product, it’s good. If not, we remove it.
One of the bigger problems we’ve seen in many companies moving to agile development is the fact that the people leading the change are typically not currently developers. Many took classes on “Agile” to become “Certified”, but the real world examples people need to translate their current processes to delivering with more agility rarely come from books. How many of the signatories of the Manifesto for Agile Software Development are certified?
Have you heard variations of discussions like this? I have.
Dev: “What’s a user story”
Certified Agile Coach: “It meets INVEST, obviously. Also, it has a persona and a value statement.”
Dev: “Invest?”
CAC: “Independent, Negotiable, Valuable, Estimable, Small, and Testable”
Dev: “OK, so the business won’t use anything until it’s all done, so the entire application is a user story?”
CAC: “Well, no. It’s smaller than that, obviously!'
Dev: “Well, I can’t negotiate anything smaller and it has no value otherwise so..”
And so on, until the contract runs out and the Certified Coach collects their fee and starts their next contract. Right after that comes the “story point” conversation.
The outcome of this is teams sitting in meetings parsing words and coming up with “As a developer, I want a database, so that the application can store data” and then arguing how to estimate it.

As a practitioner of Pragmatic DevOps, testable definitions are required to effectively onboard developers who are new to continuous delivery. To meet the goals of CI/CD and to deliver predictably, we need to deliver tiny batches of work that we can demonstrate and get feedback on. It’s also very important that we are able to effectively communicate using ubiquitous language that all stakeholders understand. In that vein, we use the following definitions when helping teams and external stakeholders understand Features, Stories, and Tasks.
Feature: A complete behavior that implements a new business process and consists of one or more user stories. If your feature is too big, then you risk delaying a change that could add value immediately, so keep the features as small as makes sense.
User Story: The smallest change that will result in behavior change observable by the user and consists of one or more tasks. If the change is not observable, it cannot be demonstrated. If it cannot be demonstrated, there’s no feedback loop and you cannot adjust with agility.
Task: The smallest independently deployable change. Examples: configuration change, new test, new tested function, table change, etc. A task may or may not implement observable change, but it is always independent of other changes. If a task cannot be deployed without another task, then change priorities or learn how to use feature flags.
Keeping the language simple and minimizing the ways definitions can be interpreted is key to effective skills training. We recommend starting a glossary and testing the definitions. If they create confusion, refactor them.
Coming next: You Don’t Need Story Points!
Written on January 11, 2019 by Bryan Finster.
Originally published on Medium