This is the multi-page printable view of this section. Click here to print.
2020
- Holiday Special
- The Only Metric That Matters
- Testing 101
- When to Resolve Tech Debt
- Organizing for Failure
- Forking, Branching, or Mainline?
- Schrödinger's Pipeline
- You Can't Measure Quality
- Standardizing to Scale
- DevOps Darwinism
Holiday Special

Ah, holiday traditions. Christmas carols, Black Friday, Cyber Monday, fruit cake, egg nog, and change feeze. It’s that time of year again where companies everywhere stop allowing production changes. Let’s chat about this.

Change freeze, if you’re not aware, is the process of only allowing emergency patches to be deployed. This doesn’t mean that work stops on coding features. It means that features being coded are held until after the freeze and then delivered.
Another concept to consider is inventory, one of the main wastes in Lean. In a supply chain, you control your inventory. You want just enough to buffer against demand, but you would really like to have the information to allow Just In Time flow of product with little or no inventory. In software supply chains, we do not create inventory (user stories, code changes) unless there is already demand, so we have the ability to have minimal user story inventory and no code change inventory because we can design a system to flow high-quality changes to production as soon as they are created.
In software, inventory is riskier than in a physical supply chain. No two software changes are ever the same. This means that quality cannot be assured before delivery. We can validate we didn’t break previous changes, but we can only hope the current change is correct. This means we need feedback on every change from the end-user to find out. The larger the changeset, the more risk there is that we have problems.

So, back to change freeze. The teams are still building features, but their quality signal has been terminated. Yes, they are still testing (your team tests, right?) but they can only test for known poor quality. As the code inventory increases, the number of unknown defects also increases. When the freeze lifts, a giant batch inventory is converted to support calls.
So, why follow this tradition do this every year? Lack of confidence. The level of confidence that breaking changes can be prevented is too low. We can either accept this and perform the yearly ritual or try something else to reduce risk. I suggest two solutions.
- This year, spend the holidays looking at your system of delivery. Identify the things that you aren’t confident in and put an improvement process in place to gain confidence. Remove variance caused by manual processes and improve test efficiency and effectiveness. Make. Things. Better.
- If a disciplined improvement process seems like too much work, just give the development teams a paid vacation so that no more defects are generated without the ability to detect them. It’s just less risky.
If you have some other ideas for risk mitigation in software delivery, DM me on LinkedIn. Let’s make things better for everyone.
Written on October 23, 2020 by Bryan Finster.
Originally published on Medium
The Only Metric That Matters

I’ve been a software engineer for a while. When I had the opportunity several years ago to help uncover the core practices needed for continuous delivery, one of the things we needed to know was how to measure the outcomes. There are a bunch of things you CAN measure and some of them are even useful, but I want to propose just one metric to rule them all.
I’m a photographer. I’m also a major fan of fighter aircraft. The engineering required to balance controllability, survivability, maneuverability, etc. Plus, they are just pretty. A few years ago I had the opportunity to visit Nellis AFB in Las Vegas with a friend who’s a retired Lt. Colonel. We were there to visit the Thunderbirds museum and tour some other cool things. I highly recommend the “Petting Zoo” where they keep captured Eastern Bloc hardware. It’s fun sitting in a Constant Peg MiG.

This wasn’t an airshow that was open to the public. This was a Tuesday. Our group of five and a grandfather and his grandson were the only people there not working.

If you’ve not seen the Thunderbirds before, you should. They clearly demonstrate the outcomes of teams focused on missions they believe in.

This is the ground crew. These are the people who get it done. Each of these planes is owned by small teams and all of the teams are here. The airman on the right in a standard uniform is being evaluated. He joined the team to see how it works so he and they can see if he’s a fit. What you’re seeing here is the ground crew cheering the two pilots coming out for a practice mission, the same way they do at airshows. You see, they don’t go to an airshow and do airshow things and then do something else at home. They are always practicing for the mission. They perform the same tasks the same way every day so they can identify and resolve the unexpected quickly and also always know what the rest of the team will do.

This is the Thunderbirds’ commanding officer. Notice the names of the ground crew on the aircraft. That is the team that owns that aircraft. They let him use it.

…and it broke.
When they attempted to deploy TB1, there was an error. They had impressive MTTR. After about 10 minutes of triage, they decided that the required fix would delay things too long, so they spun up the standby aircraft. They know things will break. Failure is a promise. They practice for it. No one was blamed for the failure because failure is a consequence of trying to excel. Because they practice for it instead of trying to prevent it, it took 10 minutes to deploy a fix instead of hours or days of intensive checks to make sure nothing can break. The outcome?

They deployed him in Thunderbird 6.
So what was my takeaway? How does this relate to measuring high performing software development teams? That ground crew knew the mission. They believed in the mission. They had each others’ backs to perform the mission. The “new guy” was part of the team, not sidelined. They aren’t measured by the number of bolts turned. They are measured by mission readiness. The leading indicator for me of mission readiness is ownership of the mission. Ownership means they have the tools and skills they need to accomplish the mission, the ability to make things better, and responsibility for the outcomes.
For me, there is exactly one measurement that I can look at to get insights into the health of the product and the product team.

Pride
If you want to lead or be part of a team like this, check out my other articles in the “5 Minute DevOps” series. Together we can make every team the team we want to be part of.
Written on October 22, 2020 by Bryan Finster.
Originally published on Medium
Testing 101

Continuous delivery is a way of working to reduce cost and waste, not just build/deploy automation. For CD to be effective, we must identify and fix poor quality as early in the process as possible, never let poor quality flow downstream, and do this efficiently and quickly. Central to this is the discipline of continuous integration. CI requires that you have very high confidence that code is working before it is checked in and that those check-ins are happening at least daily, and tested on the trunk with the CI server. This requires efficient and effective testing as a core activity by everyone on the team. However, getting started can be daunting. There’s so much conflicting information available, much of it bad. People new to testing can get overwhelmed by the amount of information out there and tend to expect it to be complicated. There is also no common language for testing patterns. Ask three people what an “integration test” is and you’ll get four answers.
The reality is that testing isn’t that hard, it’s just code written for a different purpose. All that’s required is to pick some good source material, remember a few guidelines, understand the goals, and practice writing tests.
Good Sources
These are good places to start:
Now that we have some references that don’t suck, let’s hit the high points.
Some terms
- White-box testing: Testing the implementation. Inside out.
- Black-box testing: Testing the behavior. Outside in.
These are relative to what you’re testing, the system under test (SUT). If you’re testing a complicated function to verify it’s working correctly by sending inputs and asserting the output is as expected, then it’s a black-box test. If you are testing a workflow through a service relying only on tests that validate each method, you are white-box testing and have a very brittle test architecture that will make refactoring toilsome.
Goals
- We want to be confident that we can deploy this change without breaking something. This is very much different from 100% certainty. The level of confidence required is based on risk.
- We want most (80% — 90%) of that confidence before we push that change to version control. This means we build tests that can run locally, off-network, and quickly.
Not Goals
- **Code coverage.**Do not make code coverage a goal. Code coverage is an outcome of good practice, not an indicator that good practice exists. High code coverage with crappy tests is worse than low coverage you trust. At least with low coverage, you KNOW what’s not tested. Crappy tests hide that information from you. Use code coverage reports to find what really needs to be tested or to find dead code, but don’t fall for the vanity metric.
- **Comprehensive system tests.**Requiringa full system test for every deploy is an indicator of poor application or test architecture. This isn’t to say that End-to-End tests aren’t useful, but they should be minimal. Creating one of these monsters isn’t an achievement. It’s just money that could have been better spent on more efficient tests.
Good Practices
- Make the test fail before you make it pass. Writing tests that cannot fail is a pretty common error. Don’t suffer from misplaced confidence. This still bites me sometimes. Some would say I’m advocating TDD. Yes, I’m advocating TDD. It reduces rework to make code testable and speeds the next feature. Stop debating religious wars and test first unless you have no need to ever change the application again.
- Prefer black-box testing. Test WHAT is happening, not HOW it’s happening. It may be useful to use white-box tests as temporary scaffolding while you make a change, but refactor them to black-box or you will tightly couple the tests to the implementation. You should be able to freely refactor code without changes to tests. If you can’t, fix your test architecture.
- Prefer testing workflows instead of using lots of unit tests. Fowler calls these “sociable unit tests”. Kent Dodds calls this “integration testing” where you integrate several units into a workflow, but do not cross network interfaces. I recommend this article on it: Write tests. Not too many. Mostly integration. — Kent C. Dodds
- Don’t over-test. If your SUT depends on other components, make sure your test does not test the behavior of the other component. If you have behavior tested at a lower level, don’t retest that behavior with a test with a larger scope. Two tests testing the same thing means both need maintaining and one is probably wrong.
- Don’t under test. Unit tests are not enough. Full system tests used as the primary form of testing cannot fully traverse all of the paths without excessive cost.
- Record/replay testing tools are heroin. They are the Dark Side. Easier, quicker, more seductive. They are good for exactly one use-case, baselining behavior of untested legacy code while you refactor and test correctly. They do not replace proper testing and will become a constraint.
- Use TDD.TDD is a design tool that results in cleaner code and better tests and is the best way to get good at testing quickly. You’ll spend less time in maintenance mode if you learn this discipline. You can rant and rave all you want about religious wars, but you’ll still be spending more effort on the same outcomes if you assume it’s BS.
- Terminate flakiness with extreme prejudice. Flaky tests that randomly fail will corrupt your quality feedback while also costing time and money. Don’t be afraid to deactivate them and write better replacements. Some tests inherently tend to be flaky. Tests that require a database or another external component are an example. Minimize their use and keep the flaky tests out of your CD pipelines.
- Don’t use humans for robot work. There is one use case for manual testing, testing anything not based on rules. Exploratory testing is a prime example. We need evil human brains to think outside the box and explore what might break that we didn’t consider. If humans are using a script to test they are being used as really slow, expensive, and unrepeatable robots.
- Don’t assume the requirements are correct. This is one of the main reasons for CD, to get a small change to the end-user to find out how wrong we are. Therefore, a test written to meet the requirements can still be wrong. Start with defining the requirements with declarative, testable acceptance criteria, then test the tests by getting user feedback for small changes ASAP. The faster you can do this, the less money you will burn being wrong.
This is just the start and really only focused on the basics needed for CI. The book “xUnit Test Patterns” is nearly 900 pages long and doesn’t cover everything. There are many other kinds of tests that might be required: contract, performance, resilience, usability, accessibility, etc. If you’re trying to do CD, dig into testing. If you say you’re doing CD and aren’t focused on efficient and effective detection of poor quality early in the flow, are you sure you’re doing CD?
Written on October 17, 2020 by Bryan Finster.
Originally published on Medium
When to Resolve Tech Debt
If you don’t follow Dave Farley, co-author of Continuous Delivery, you’re missing out. In a recent conversation about the challenges of refactoring legacy code, one of the responses talked about when to resolve tech debt.
The problem isn’t how to schedule tech debt, it’s making it clear what tech debt is. After that, when to resolve it should be obvious
In The Unicorn Project, Gene Kim refers to tech debt as “complexity debt”; things in the software or environment that increase the complexity of operations and/or new changes. Experienced software developers can see tech debt as soon as they look at the code. However, it’s hard to translate what that looks like to others.
This is tech debt:

Now, a quick question: the next item on the backlog is scrambled eggs. The eggs are immediately available. How long will it take you to scramble 2 eggs? This is otherwise a simple task. There are known good practices with very low complexity until you walk into this kitchen to get it done.
The image above is the result of all of the focus being delivering a single meal instead of repeatedly producing meals. It was done in an amateur kitchen by people who do not cook for a living.
This is a professional kitchen:

The team is organized to produce a continuous flow of quality. This includes prepping, cooking, and cleaning in a continuous process to meet the customers’ needs. They never have conversations about waiting to clean the kitchen until after everyone is fed because they know doing that would increase complexity that would first slow, and then stop delivery as the quality degraded to unusable levels. Quality and complexity are tightly coupled.
Professional cooks keep the cooking area clean to enable quality, reduce complexity, and to make the next delivery easy to produce. So do professional developers. If you are a developer who does not clean up after yourself, please start. If you are managing development teams and tell them to leave cleaning up for later instead of making it part of every delivery, ask yourself which kitchen you’d like a meal from.
Written on August 15, 2020 by Bryan Finster.
Originally published on Medium
Organizing for Failure

I recently saw a documentary on the history of the Ford Edsel. There were so many lessons on the UX research, design, manufacturing, and marketing of Ford’s new brand that apply to developing any product. I suggest everyone look into it. Since I only have 5 minutes we’re going to focus on Ford’s quality process for the Edsel.
In 1958, Ford started to manufacture the Edsel. Since this was an entirely new make, they didn’t yet have an assembly line for it. So, they shared the line with other Ford passenger cars. The Edsel wasn’t just new bodywork. It had a new engine and more complicated assembly with many innovative, and complicated, options. To accommodate the expected sales, they modified the line so that every eighth car was an Edsel. This, of course, lead to constant context switching on the assembly line. Also, since the car was named for Henry Ford’s son, the previous chairman for whom the United Auto Workers had no love lost, there were occasional “assembly challenges”. However, Ford had a well defined QA process that would keep the line moving.
Ford’s QA process made sure that dealers got only the best Ford could deliver.
- As each car rolled off the line, it went through road tests and quality inspection and was given a quality score.
- All of the quality scores for the day’s production were averaged and if the average daily quality score met the minimum, the cars were shipped to the dealerships.
Since Edsel’s represented 1/8th of production and their quality scores were averaged in with the other 7/8ths, cars often shipped to dealerships with major issues to be resolved. This process worked fine for Ford until Toyota began disrupting the market.
The Toyota production system was created to reduce costs and increase quality so that they could compete. Core to the TPS is the reduction of waste by minimizing batch size, inspecting quality at every step, and preventing poor quality from moving to the next step. They made quality concurrent with manufacturing. This proved highly effective for increasing market share and allowing them to rapidly pivot to market needs. The Toyota system is something other manufacturers have worked to emulate for more than 50 years.
Ford’s quality process sounded AWFULLY familiar to my experiences in the past delivering software.
- Develop features, often with shifting priorities and pressure to meet deadlines for the scheduled release.
- Throw it over the wall to the testing team who logs defects
- A go/no-go decision is made on the large batch of changes based on the criticality of the defects.
- If the minimum quality is reached to ship, then the release goes to the customers and an operations team fixes the defects based on customer complaints.
This process hasn’t been a viable business model for manufacturing for more than 50 years and yet it’s all too common in software development.
A friend of mine told me that his organization’s QA team had built out a framework to make it easy for developers to fully test every change on their desktop. They were teaching teams TDD and BDD and were moving quality checks as close to the source of defect creation as possible. They were focusing also on the speed of feedback. A developer could get quality feedback from a fully integrated test in less than 3 minutes. They were taking Toyota’s lessons to heart and rapidly improving the teams’ abilities to deliver.
My friend also told me that one of the development managers in his organization is pushing back on the whole idea. “Why are we wasting time on this? Why are we asking developers to test? We have a testing team.” Attitudes like this hurt the bottom line.
Is your organization executing an actual continuous delivery development process with small, tested changes and rapid quality feedback to the developers? If not, when will you finally catch up to where manufacturing disruptors were over 60 years ago? Software is eating the world, but only for those who can move from artisanal development to modern software delivery.
Written on June 22, 2020 by Bryan Finster.
Originally published on Medium
Forking, Branching, or Mainline?

A frequent conversation I have is about branching patterns. Legacy development was all about long-lived branches to develop complete features followed by code freeze and merge hell. With continuous delivery, this changes. CD requires continuous integration and CI requires some form of trunk-based development with either mainline development or short feature branches. Which is the best pattern?
Mainline?
In mainline development, changes are made directly to the trunk. Zero branching. When people first hear of TBD, they frequently envision mainline. Mainline can be an effective process but it requires some things to be safe.
- Mature quality gates and team quality process
- Pair programming for instant code review
In regulated environments, this is typically discouraged as it makes code review unverifiable.
Fork or Branch?
The debate I most often hear is branching vs. forking. On teams who are “doing CD” meaning “we have an automated deploy process”, it’s very common for forking to be preferred because “that’s what open source does!” That’s true. untrusted contributors use forks in open source. It’s also very process-intensive, which is why teams actually executing with CD don’t do that.
A fork is a private copy of the source code. The flow is that I make a fork of the code, make changes, and then submit a complete change back to the core team for code review and eventual rejection or approval. While the fork exists, there is no visibility to the work that I’m doing. Open source uses this process because the number of people who start to contribute is much smaller than the number of people who finish a contribution. Since the forks are private, they do not clutter up the source tree of the main project with noise.
A branch is a copy of the code that is visible to the core team. It allows anyone on the core team to see the current changes and the progress of the work.
For CD to function, the team must be executing CI and that requires a high level of team communication. Additionally, a product team is responsible as a team for delivering changes. The individuals on the team do not have sole responsibility. Since forks are private to the individual developer, forks put the entire team at risk of not delivering.
- The team cannot see the progress of change
- The team has no way of finishing the change if the developer is unavailable.
When designing processes, pessimism is a very useful skill. “What can go wrong with this?” I used to joke that forking code within a product team put the team at risk because “what if someone gets hit by a bus?” I don’t joke about this anymore because of a team that had to re-create the work of a teammate who was involved in a fatal accident. The world is uncertain. Plan for it.
So, fork or branch? We should branch for all work the team is expected to deliver. Forks are for experiments or non-critical external contributions that have no priority. Open source is a model for open source problems, not for the problems of product team development and daily delivery.
Written on May 31, 2020 by Bryan Finster.
Originally published on Medium
Schrödinger's Pipeline
In the lifecycle of most applications there comes a time when they will go into maintenance mode where changes become very infrequent. This is even more common for utility services that are simple, but business-critical to multiple products. There is one thing that should never be skipped, a well-constructed delivery pipeline that fully exercises the application to verify it won’t break production. Having this in place means that future developers, even when they are us, have a clear path to deploy new changes with low risk. In fact, that pipeline and the effectiveness and efficiency of the quality gates should be the primary product for any team delivering business-critical applications and that pipeline must always be green or any changes to that code are just undeliverable waste.
When we are developing the application initially, there is a flurry of change. If we are doing CD correctly, those changes are verifying the pipeline is green daily. Later on, fewer changes are required as focus shifts to another domain in the product. What’s the impact of this?
Several years ago, a group of us were exploring the techniques of continuous delivery, we focused on pipeline construction, development practices, testing, and the metrics of delivery to see how we were progressing. We were doing this with a combination of existing legacy applications and greenfield development focused on exposing legacy logic and improving the user experience. This was a multi-team effort with a few of the teams also uncovering CD good practices to share with the broader organization. As the development effort evolved, one of the teams created a NodeJS API to wrap legacy ESQL/C code to expose the 20+-year-old core logic to the application being written by my team. There were many hard-won lessons. We even independently invented service virtualization to bypass the need for a 4-hour process to set up test data for an End-to-End test. After the API was stable, the focus moved elsewhere with no API changes required for several months. However, time passes quickly outside of the pipeline.
One day, a new feature required an API change. It was estimated that the new change would be ready for production in less than 2 days. My team’s application would be ready to use it later that week. Since we had a solid contract change process we were able to work in parallel based on mocks. However, when the API team’s first code change triggered their pipeline, they got a nasty shock. One of their core dependency libraries had been blacklisted for critical security vulnerabilities and the next available version introduced a breaking change. Major refactoring was required to upgrade the library before that simple change could be applied. A 1 to 2-day task stretched for a couple of weeks.
After the changes were finished, we had a CD post mortem. What happened? What can we do to prevent that from disrupting the flow of delivery in the future? The remediation plan we came up with was quite simple. We decided it’s not enough to trigger a build when the trunk changes, so we created scheduled jobs to build every pipeline weekly. There’s very little risk in deploying code that hasn’t changed to verify the pipeline is still green. Risk and uncertainty increase the longer the duration between builds.
Every delivery pipeline is focused on reducing risk. Any uncertainty in the pipeline must be aggressively weeded out. Long dormant pipelines are exactly like Schrödinger’s cat. They might be red and they might be green. Until they run and report the results, they are in the superposition of both red and green (brown?). Exercise them to collapse the function.
Written on May 31, 2020 by Bryan Finster.
Originally published on Medium
You Can't Measure Quality

“We want our teams to be more efficient and deliver higher quality!”
“We sure do, how will we measure it?”
The typical response is to apply a thin veneer of seemingly appropriate metrics, add a maturity model or two, and hope things get better. Whenever I hear of someone using code coverage to increase quality or using an “Agile maturity model” to improve team efficiency I know they need help. On the bright side, if you focus on the quality and drive down cycle times, then you get efficiency for free
First, let’s define some terms.
- Quality: Something the consumer finds useful.
- Efficiency: The ratio of the useful output in a process to the total resources expended.
- Cycle Time: The total time from the beginning to the end of a process.
Quality isn’t an abstract concept that can be predicted in isolation. Quality is the consumer finding the outcomes to be useful. Cycle time is how long it takes us to find out there are quality issues. By reducing the cycle time to get quality feedback, we reduce waste in the process and get efficiency for free.
You cannot measure quality. You can only measure the fact that poor quality exists. Does the consumer use your work? Are problems reported with your work?

This the 2017 MacBook Pro, Apple’s flagship laptop, until they started listening to their consumers again. I was waiting for this to come out in 2017 because I needed a new personal laptop. After it’s release, I went to the store, tried it out, and bought a refurbished 2016 model because the new one lacked quality. The keyboard lacked tactile feedback, it didn’t have the ESC key that all devs users use constantly, it didn’t have the ports I use when I travel for photography (dongles get lost in camera bags), and the touchpad is too big. I still use a mid-2014 for work and will until it dies or I can be assured I can get the new one with a better keyboard and an ESC key.
One of the basic behaviors required to establish a quality process is to establish a repeatable process to detect quality issues as rapidly as possible. In software, this is done using continuous delivery. Our first priority is to establish and maintain the ability to deliver to the consumer to find out how wrong we were. Our next priority is to deliver a small change and see if it’s we have quality problems and then continuously improve our ability to detect and prevent them in the future. The end-user isn’t the only consumer though. Every step in the process should reject poor quality.
We need to improve our tests
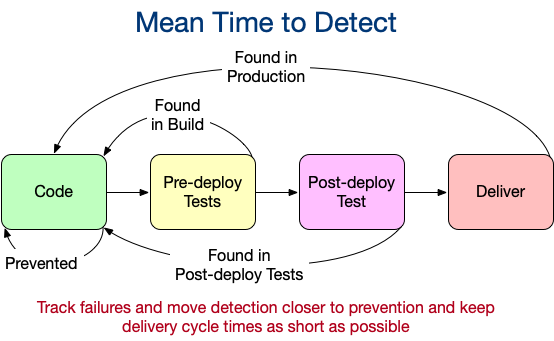
Code coverage is a terrible indicator of test quality. Code coverage reports how much code is exercised by test code while having nothing useful to say about the quality of those tests. We measure test quality by how ineffective the tests are from preventing defects from moving downstream. If we want to improve test quality, then we need to track the cycle time from commit to defect detection, Mean Time To Detect. The worst case is that they are found in production and that we deliver to production at the glacial pace of once a week or longer. The best case is that they are detected as soon as they are created using a mature CI process. So, we fix this by delivering more frequently (to reduce the number of defects per delivery) and we methodically measure and perform root cause analysis on defects to identify where the test suite can be improved to alert the developer much sooner. By methodically reducing the cycle time between defect creation and defect detection, testing quality improves. Tests will never prevent defects from occurring though and it’s critical we keep the cycle time from commit to delivery low to reduce the number and severity of production defects. Doing this reduces costs and improves efficiency.
We need good user stories
When I first had “Agile” inflicted upon me I was told that “Agile maturity” included having user stories with acceptance criteria and fewer than 13 story points. I am reasonably sure I’m not the only one who had “Agile” inflicted upon them by someone who was qualified because they passed a test after a 2-day class. So we created stories and they had bullet-pointed acceptance criteria but somehow things didn’t get better. We had a good “maturity score” though. Agile development isn’t a process, it’s an outcome. We were measuring processes, not the delivery. When I got on a team that was working towards continuous integration (master always deployable, changes integrate to master multiple times a day) we discovered it wasn’t enough to have a bullet-pointed list created by a product owner. “Good” acceptance criteria can’t be measured, but bad is easy to measure. How often is work blocked due to a lack of understanding? How often do developers ask for clarification? How often are code reviews rejected because of disagreements over functionality? Worst, how often are defects found in production and then re-classified as “enhancements” because what was delivered matched the bullet points? To improve this, we must improve the process of delivering acceptance criteria to the consumer of the acceptance criteria; the developer. BDD is an excellent process for this, BTW. We also need to track the cycle time to go from the story (the ask) to acceptance criteria (the goal) that the team fully understands and knows how to test. If I cannot test it, I cannot execute CI, and I can’t deliver with agility. If we reduce the time it takes to do this, then we also reduce the cost.
There are many steps required to go from idea to delivery. Each of those steps must be a quality gate. Each step needs to have entry acceptance criteria that can trigger the rejection of poor quality work from the previous step. Measure the reject rates, how long it took to find the issue, and how much it cost and your quality and efficiency will improve. Quality cannot be known in isolation. It can only be derived from the feedback from the consumer of your service or product. You don’t want to find out after working for a month that you have poor quality because your end-user refuses to use the work.
Written on May 14, 2020 by Bryan Finster.
Originally published on Medium
Standardizing to Scale

Scaling improvement is the siren song of every enterprise. Once we have a team that is able to deliver the outcomes we are looking for, the obvious next step is to define those best practices for the rest of the teams. Then scaling is just a shake and bake exercise.
All we need to do now is to make all other teams work the way the successful team works:
- All teams will have the same sprint cadence
- All teams will have the same size story points (note: if using days for points, call them days. Points aren’t a measure of time.)
- All teams will use the same tech stack
- All teams will use the same quality process
- etc.
Success!
There are some problems with this approach though. It assumes all teams are solving the same problem with the same architecture and have the same skill levels. It also does some very destructive things:
- Leadership is responsible for quality instead of the teams
- Teams must ask permission to improve quality.
- All teams are constrained to the outcomes of the lowest-performing team.
That isn’t a good thing because leadership is usually the last to know about poor quality and usually because of customer feedback. If a team needs to ask permission to improve quality, they probably won’t. The teams with people who know better ways to deliver will have more turnover as those developers find less frustrating places of employment where they are respected as engineers. None of these are good for the bottom line.
Now what?
We still need all of the teams to improve and improvement isn’t just some random thing that accidentally happens. There must be a methodology to it. Instead of dictating the process, we need to use balanced metrics and ownership.
Metrics
- How frequently is code integrating into the trunk? This is a KPI for clear requirements and small coding tasks that are well understood by the team. This reduces guessing and defects.
- What is the build cycle time between code commit and code deployed to production? This is a KPI for the efficiency of the testing process. A test suite has two primary goals: notify the developer of any defect as soon as possible and allow the developer to quickly locate and fix the defect. This gives the best opportunity for the developer to learn how to not create that defect in the future. Prevention is much cheaper than detection and repair. Long cycle times here indicate poor test architecture that will reduce the team’s ability to improve development.
- Where are defects found in the build? Are most defects found in environments closer to production or, worse, in production? This is a KPI for the effectiveness of the test suite. Tests should be optimized to quickly detect defects as close to the source as possible.
Ownership
One of the practices people always talk about at conferences is “self-organized teams”. The thing people tend to leave out is that those self-organized teams become chaos without clearly defined goals and expectations. Self-organized teams have total ownership of their product. They are responsible for how it is built and feel the consequences of building it the wrong way. They eat their own dog food. Ownership can be destroyed by either telling them how to work or by outsourcing production support to another team. If they lack full ownership, the quality will always suffer.
Next Steps
Scaling quality comes from disciplined development, ownership, and practice. When we work with teams, we focus on the discipline of continuous integration. Each developer integrates fully tested, backward compatible code to the trunk at least once a day. If we can’t, why can’t we? Solve that problem and the next and the next. We make them responsible for the outcomes, and we reduce the batch size of everything so that things happen more frequently. We integrate rapidly because it improves the feedback loop. Give teams the freedom to find better ways that align with the goals, demand excellence, and get out of their way. They will deliver.
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on. Feedback is always welcome.
Written on March 9, 2020 by Bryan Finster.
Originally published on Medium
DevOps Darwinism
As organizations attempt to transform, they often focus on tooling or hiring “transformation consultants” as a silver bullet. However, tools are a small fraction of the problem and training teams to Scrum usually results in small, low-quality, waterfall projects. Organizations tend to struggle for some very common, simple, and difficult to fix reasons. If you are not getting the outcomes you wanted or expected, look around. Are you seeing these?
Tl; dr
Delivering value better to the end-user is not a problem that can be solved by hiring “smarter” developers or having teams use a new methodology. Improving value delivery requires the entire system to change.
Things aren’t improving because your organization isn’t configured for the improvement you want. What will you fix first?
Issues that Impact Team Evolution
The teams in the organization are organisms that have evolved to survive in the current working environment. The issues you see are not team failures; they are the behaviors that the teams have found that give them the best chance to thrive in your organization, even as the organization falls behind. Consider this while designing an improvement plan.
Poor Quality
Quality never comes from “just do it right the first time”. Quality is the outcome of having a clean quality signal that identifies poor quality as early as possible and by continuously improving every area where quality issues can occur. In software development, the main quality signals come form quality checks in the delivery process and customer feedback. The main quality issues come from humans modifying code. Since quality is the key enabler to availability and speed to market, we need to change our environment to improve the quality signal.
For decades, organizations have tried force quality at the end by assigning test teams to manually test or create test automation to inspect completed work. In fact, most universities don’t even include testing as part of any degree that includes software development. Testing is often seen as a lower-level position for failed developers. Would you buy a car where the only quality check was to drive it around the parking lot after assembly to make sure it didn’t instantly fall apart? How would that company identify the source of the inevitable issues? To resolve this, the team delivering the solution needs to put building a stable quality signal as their highest priority. We automate delivery to remove variation in the process. We build out tests to verify we have not broken working features. We relentlessly eliminate random test failures. We design every test with the idea of getting rapid notification of the failure as close to the source of the failure as possible.
Another issue is organizations offloading product support to support teams. This adds another filter to the quality signal that hides the pain of poor quality from the source of poor quality. Quality doesn’t come from trying harder. Quality comes from ownership of the solution and by feeling the consequences of poor quality.
Change the incentives. Teams must be given quality ownership. This does not mean punishing people for defects. This means making sure that engineers get rapid feedback on quality issues, have the authority to make the quality better, and are responsible for the consequences of poor quality by having direct support responsibility. This will require training and a focus on test design by everyone. Invest in the teams and they will deliver.
Knowing What to Build
Software delivery is a system. Coding is a small portion of that system. Knowing what to code, and what not to, is a critical activity that many teams skip because it “takes too much time”. It’s common to see “Agile” execution of the waterfall process of someone writing down requirements and handing them to developers to code. Water-scrum-fall. When the organization believes that we must “optimize for developer productivity” by making sure developers are coding as much as possible, then quality suffers. Breaking down work to the detail required for an effective quality process needs the whole team. This is the first chance the team has to implement its quality process:
- Do we understand how to measure the success of this feature?
- Do we know everything we need to know about how it’s expected to behave?
- Do we understand and have a plan for all dependencies, met or not?
- Is this the right thing to build into our product?
- Have we finalized the exact behaviors to prevent gold plating?
- Do we know how to verify the behaviors with tests?
All of these answers must be affirmative before work can start and only the team can answer these questions. If someone pushes the team to start work before these checks pass, who is at fault for the poor outcomes?
If teams are incentivized by tasks completed instead of value delivered, then the quality will suffer. To change the behavior from order taking to quality ownership, the team must be rewarded for outcomes, not output.
Large Batch Sizes
Large changes are risky, slow to deliver value, and delay quality signal. Most organizations unintentionally encourage large changes by having heavy approval processes, multiple handoffs, or project planning habits that think in terms of “done” instead of the next delivery of value. Teams react to these by batching up changes.
It is better to deliver many small things than one big explosion. How small is small enough? Any work that cannot be broken down into units that a single developer can deliver in a couple of days will not meet the standard for “small enough”. There will be hidden unknowns and assumptions that will reduce quality. Yes, it is an additional upfront effort. However, the entire system of delivery is improved. Everyone understands the work, everyone can help deliver it, and if any single team member becomes unavailable for any reason the work is only slightly impacted. Also, small changes begin to flow to the end-user rapidly enough to answer the most critical questions as cheaply as possible: Are we building the right thing? Can we verify quality?
The problem with small changes are they require an organizational shift in thinking. The entire system of delivery needs to be reviewed to remove cost and waste that incentivize large changes. Are there feedback delays from external team handoffs? Are we handling dependency management with code or with added process? Also, the developers need to understand that no feature is ever complete, so waiting to deliver complete features is wasteful.
Fixing the problems takes planning. Make sure you understand your delivery pipeline. Measure how long it takes to go from commit to production. Make sure you have a solid quality signal and then begin reducing the time between when work begins and when value is delivered. As you set the next improvement targets on this cycle time, you’ll uncover additional hidden waste either in the delivery pipeline, the development process, or upstream in how requirements are refined. Execute an improvement plan to fix the issues and change the environment to an expectation of continuous integration and small units of work.
Misaligned Incentives
A common anti-pattern is to attempt to measure a person’s productivity by the number of features they finish. Developers are problem solvers. If you give them the problem of “how can I make my productivity metric look good?”, they will do that at the expense of helping the team deliver value. Of course, since the delivered value is not being measured, it’s not important. Sure, the product is poor quality and the organization is failing, but I’m a rock star because of my output. I probably have a support team handling the defects anyway because support “reduces developer productivity”. My survival instinct tells me to avoid any work not related to my task so the new team members are on their own and I’ll avoid code review or just give it a passing glance. Those things make me “less productive”.
Quality comes from discussing issues and ideas. Value is delivered faster by teams collaborating. The team should be rewarded for the outcomes of their product and have the ability to improve those outcomes without being told to do so or asking permission. If I finish coding a task and submit it for code review, new work should be the last thing on my mind. There are probably other code reviews that need to be done; we are doing continuous integration after all. Someone on the team may be scratching their head or deep in thought about their work, how can I help them? What about that doubt I had about our tests? I should go try to break things in the application to see if I’m right. Continuous exploration to find new defects before the user discovers them helps to keep me sleeping at night. Nothing else to do? What‘s the next priority?
This working agreement leads to less code written and better outcomes. It’s our product. We are proud of it. We want it to be good. We want the user to embrace it. We build quality and deliver value, as a team, rapidly.
Culture Challenges
Team culture is incredibly important. Teams of heroes who are competing against each other for promotion deliver solutions that require heroism. Team members who fear obsolescence will hoard knowledge to become “indispensable”. Senior developers who desire respect over outcomes will demand to be the arbiter of good code and final reviewer of all change. None of these behaviors protect business goals.
A team is a group of individuals who all share a common goal, respect each other, and support each other to reach those goals. Team members elevate and help each other, they do not compete. However, it’s very common to see HR or leadership behaviors that are unintentionally designed to destroy this culture. Heroes awarded for handing the major outage. Comparing team members based on tasks completed. Some even use lines of code as a measure of productivity. This deep misunderstanding of teamwork is frankly shocking. If you recognize these anti-patterns, the environment must be changed,
Leadership Should Lead

“All of you need to change!” The problem is that the entire organization, including leadership, must change to support the outcomes. When change is focused only on the teams then the best case will be minor local optimization of a few interested teams who happen to be organized correctly. If your goal is to improve the ability of your organization to deliver, it’s not enough to say buzz-words and ask why nothing improves. You must study what is required to help the teams achieve those goals. You need to understand what current issues in the environment of your organization are causing the teams to work the way they are. You need to systematically change that environment to get the outcomes you want. This takes work. Get out in front. Dig in. Lead the change.
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on Feedback is always welcome.
Written on March 4, 2020 by Bryan Finster.
Originally published on Medium