This is the multi-page printable view of this section. Click here to print.
2022
- The Most Ignored Aspect of Quality
- Emotional Testing
- DevOps or SRE?
- The Most Dangerous Metric
- Optimizing Human Resources
- DORA Metrics Tips
- SAFe Isn't
- Flying Cars are Boring
- Agile Deepities
- Business Value Isn't My Job
The Most Ignored Aspect of Quality
 https://www.flickr.com/photos/pdamsten
https://www.flickr.com/photos/pdamsten
I was speaking to a friend recently about a production incident he was involved with. He said he noted several things that could be improved to help the team with their response. I asked if a postmortem was done.
“Yes”, he said. “There was an attempt at a postmortem.”
“An attempt? What was the outcome?”, I asked.
“It wasn’t received well by the area’s Director. The focus was more on the team’s behavior and the fact that the incident had occurred at all rather than lessons learned.”
“That’s unfortunate. That makes us much less safe.”, I responded.
Why is that? If I lack trust; if I think I may be punished for something going wrong, I promise nothing will ever go wrong. We’ll never find code or network vulnerabilities. We’ll never find issues that might expose sensitive data. There will be no defects, just small feature requests that are incorrectly reported as defects until we fix the classification. Everything will be fine.
That, of course, is nonsense. Things will go wrong. However, without a culture of trust where I know we are all trying to continuously improve the system rather than finding people to blame for failure, I will hide any mistake that may blow back on me. We will just cross our fingers and hope it doesn’t impact the organization.
Trust is the first impediment to security and quality. Lack of trust within the organization results in fragile systems that put us all at risk.
Responding to Error
In 1976, NASA established the Aviation Safety Reporting System (ASRS). This system allows pilots to confidentially self-report accidents they are involved in so that NASA can collect data and provide guidance based on the accident reports to the FAA and the airlines. Why would pilots report their errors? If the FAA becomes aware of the accident and then tries to impose civil penalties, the fact that the pilot had submitted the report exempts them from punishment for minor infractions. This allows the rest of the industry to learn from mistakes and to steadily improve the safety of the airways.
The Toyota Production System recognizes that errors occur as well. They also recognize the error is caused by how the production system is designed, not by the people. The famous “Andon cord” is used when someone notices a problem. They stop the line and problem analysis experts descend on the area and use the “Five Whys” to analyze why the issue occurred to find ways to harden the process against re-occurrence. In the end, a report with recommended actions is created and acted upon. There’s no punishment for the person reporting the problem even if it was the result of something they did personally. The goal is to make it harder for people to make mistakes. There is only one way to get punished for a problem, failure to report it.
These two organizations gather problems, learn from them, and make recommendations for systemic changes to make those problems harder to reoccur. This is exactly the way a high-performing organization will treat things like quality and security problems. No excuses, no punishment, just an honest examination of the gaps in the system.
“What modifications could we make to make it harder for that to happen?”
Screwing Trust Up
Here’s a real-life example of management not understanding system thinking, destroying trust, and making things less safe.
A large organization had been struggling with several production changes that went poorly resulting in a significant impact on multiple occasions. In some cases, the causes could be identified with much fewer than five “whys”. However, no postmortems were done. Some people were held individually accountable. The management “fix” was to implement a change approval process with several levels of approval so that the person representing the change could assure at least three layers of management that they had, indeed, checked all of the quality boxes. Just to be sure, all changes must occur after hours to reduce the impact of failure. If a change fails, the person who made the change will be required to train on how to make changes correctly.
What is the impact of this? Simply that nothing was improved. Process overhead was added that injected a minimum of five days of lead time. This caused ongoing delays in delivering business capabilities. The underlying issues that allowed the problems to occur were never addressed. A side effect is that the people who focus on system improvement in their teams, the actual 10x engineers who elevate those around them, are leaving the organization. This makes the company objectively worse and less likely to improve in the future.
Fixing the Problems
Let’s compare those organizations to the incident response my friend was involved in. Trust needs to be rebuilt in that organization to improve safety and security. There should be a postmortem about how the original postmortem was performed followed by action to improve the original postmortem and action to address the underlying system failures that are uncovered. The management and the team should work together to solve the problem and understand that the currently defined processes are the defect, not the people performing them. Working together will help rebuild the trust that has been damaged or lost.
Trust is the first impediment to value delivery. Without trust, everything degrades. Building a culture of psychological safety isn’t some “warm and fuzzy nonsense.” The building of that culture should be a pragmatic response to the desire to improve our outcomes. Building trust is an ongoing effort and when trust is damaged, rebuilding it needs to be a priority. Growing trust is work. All that’s required to destroy it is to do nothing.
Emotional Testing

Recently someone asked me, “Does code have to be tested by code to be considered tested? Who tests the code that tests the code?”
This was in the context of when to write tests. He was asserting that we only want to invest in tests after we deliver a release and confirm the value and that manual testing and delaying proper testing is fine. He is wrong.
“Does code have to be tested by code to be considered tested?”
To be considered tested correctly, yes. The code works the same way every time. People are variable. Tests should be deterministic. QED
“Who tests the code that tests the code?”
That’s a really strange question. Who tests human testing? The implication is that humans can test better than robots. It’s an emotional need I hear from many people, but mostly from people who aren’t responsible for operating in production. Let’s work through this logic.
Manual acceptance testing: Test scenarios are defined before coding starts. Coding is completed and someone sets up data for the test scenarios and executes the tests. After the manual testing is done then the release is shipped.
Automated acceptance testing: Test scenarios are defined before coding starts. Coding and test automation are done concurrently. When done correctly, they are done by the same person. Tests run in the CD pipeline. Tests pass and the release is shipped.
In those two scenarios, where is the process where the manual testing is “better”? In both cases, the test for how well the testing was done is delivering and observing how the end-user responds. Production is the test for any test, no matter how it is done. The problem should be obvious though. If the test was bad, how do we fix it? Well, it depends on why the test was bad.
Misunderstood Requirements
This is a common reason and it impacts both kinds of testing.
With test automation, we modify the test once to correct our understanding of the behavior, and every time we make a code change we verify we have the same understanding.
With manual testing, we modify the test script and re-verify that behavior for the next release.
Similar, but with a key difference. The speed of discovery and error correction will always be slower when a human is doing the work instead of instructing a machine to do it. Some people feel manual testing is faster because they feel busy doing it. An emotional and incorrect response. Another difference is that the automated test, once changed, won’t make a mistake.
Testing Mistakes
While executing the test, an error was created by the person executing the test.
This can happen with both kinds of testing. We could write an automated test with a bug or we could make a mistake executing the test script. However, with automated testing, it can be corrected and will not happen again. With manual testing, it is a risk for every test scenario on every test run. With manual testing, as the scope of testing increases, the likelihood of testing errors increases. This isn’t true with an automated test suite.
Data Configuration Error
With good test data management systems, this can be mitigated somewhat for manual testing but I’ve rarely (never) encountered anyone who said they had a tool that versioned a data set and made that state repeatable on demand. Usually, an unrepeatable set of data is used until it’s used up or a set of data that isn’t representative of a production environment is contrived.
With proper automated testing architecture, we have much better control over the state. In fact, for most test scenarios we can eliminate the state entirely and focus only on the behaviors. We have the ability to minimize and isolate stateful tests to make our tests 100% deterministic, one of the definitions of a good test.
Eliminate All Manual Tests?
For acceptance testing, yes! Is there a place for manual testing? Sure. Exploratory and usability testing are important creative activities. The first is focused on finding scenarios we didn’t think of automating. Then we add these tests. The second is focused on validating how humans feel about using it. That informs future changes. However, there is no place for manual acceptance testing as a gate to delivery.
Manual acceptance testing is slow, non-repeatable, lacks granularity, and lacks determinism. So why do people insist on using it? It’s not a decision based on engineering. It’s an emotional decision based on fear. “I can’t see the testing happening, so it must not be good testing.” People have feared machines since the printing press. We should make decisions based on reality.
If you have manual acceptance tests, everything to the left of testing is made worse. Batch sizes increase, value delivery is delayed, people become more invested in bad features, and customers get lower quality outcomes. Move the emotion to where it belongs, making users desire the outcomes. Improve everyone’s lives by letting people do creative things. Only robots should run scripts.
DevOps or SRE?
A few years ago, one of my friends took a new role and talked about the work we’d been doing on DevOps. His new CTO said, “DevOps is dead! It’s all about SRE now!” Someone is missing the point.

I had dinner recently with Patrick DuBois, who coined “DevOps”, and Andrew Clay Shafer, the “Godfather of DevOps” and we talked about some of the industry challenges, the glacially slow progress toward improvement, and the frequent setbacks we are seeing. There are many reasons for it but much of it comes from people not approaching it with systems thinking. Instead, terms get misused, packaged, and sold. For successful improvement, we need to view the whole system.
I really like Donovan Brown’s definition of DevOps,
“DevOps is the union of people, process, and products to enable continuous delivery of value to our end users”
Simple and direct and makes it clear that we need to address the entire system. In the interest of brevity, let’s look at where some of these pieces fall in the system. The following are some of the major topics. It is in no way exhaustive.
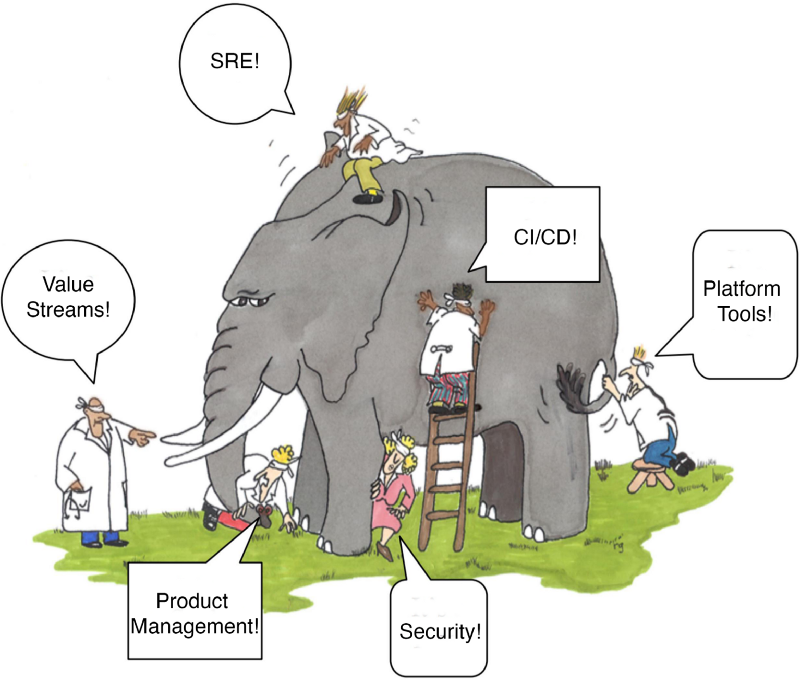 The DevOps Elephant
The DevOps Elephant
Product Management
The whole point is to improve how we deliver products. Product management needs to be on the ball. We cannot assume what we build will be valuable. We need to do our research, make value hypotheses, and find ways to get feedback as quickly as possible on small value experiments. Every delivery is a wager on value vs. wasted effort and larger deliveries are more expensive when we lose the bet. Smaller is always better when trying to invent something new that we hope is valuable.
Value Streams
This is how we organize teams, not just development. Do we have functional silos? How many handoffs or communication paths are required to deliver something? Every handoff adds wait time where work sits idle until it can be picked up by the next person in line. Where are the bottlenecks that are slowing things down? Analyzing those problems and reorganizing things makes it much less costly to deliver value.
Security
“Introducing DevSecOps!”

If we are working to continuously deliver value to the end user, is it valuable if it’s insecure? Security has always been part of DevOps. It’s not a new discipline. We need to be “secure by design” in DevOps instead of the classical Grenade Driven Development approach of building the system and then attempting to secure it with inspection at the end. Security should be a platform that enables secure delivery with tooling and training, not police investigating the “crime of new software.”
Platform and Infrastructure
Our DevOps team is responsible for the configuration of over 300 pipelines!

DevOps isn’t a team or a job. See the above definition. Platform and Infrastructure teams are also enablers of value delivery and should be working to provide self-service solutions that are easy to use so that development teams do not need to know how they work, they just work. Without this, value delivery suffers.
Continuous Delivery
It’s right there in the definition, “continuous delivery of value”. It’s even the very first principle of the Agile Manifesto. CD is not tooling. CD uses tooling to enable a workflow that focuses on a repeatable quality process that can reliably give us feedback on known quality issues before we deliver to the end-user and uncover unforeseen quality issues. This workflow focuses on improving things to enable ever smaller deliveries to accelerate feedback loops from production. It’s not a “throw it over the wall” delivery approach. It’s a quality initiative that enables us to respond quickly to functional, performance, security, or any other quality issue. It also allows the small batch sizes that enable smaller value experiments that reduce the risk and size of lost bets.
SRE
We don’t have DevOps, we have SREs!

Again, DevOps isn’t a job. DevOps is the whole operating model for improving value delivery. Delivery teams need air cover to ensure they are able to focus on their quality process and are not pressured by deadlines to deliver unstable or unusable features. A Site Reliability Organization or similar capability that has the independence to say, “until you are stable, we a returning operational monitoring responsibility to you” is important quality backpressure to prevent things from coming off the rails in the quest for speed. We need smaller, sooner, and more stable. If it’s not stable, it’s not valuable.
Let History Guide Us
If you’d like to learn a bit more about how DevOps started and what the goals are, I suggest looking at what was written by the people who were there at the start. Damon Edwards is one. Check out his recollections.
The Most Dangerous Metric

Measuring humans changes behavior and often not how we’d like. Some metrics are more dangerous than others. The most dangerous metric goal I’ve found so far in software engineering is code coverage.
What’s code coverage? Simply, it’s the measure of the amount of code that is executed by test code. How could this be dangerous at all? Well, things like this happen
“All applications must have a minimum of 80% code coverage!”
A mandate like this is depressingly common in both the public and private sectors. If you ask why in the context of the Department of Defense, you’ll be pointed to NISTIR 8397 which has the following to say about code coverage in the Summary in section 2.0:
“Create code-based (structural) test cases. Add cases as necessary to reach at
least 80 % coverage (2.7).”
That’s pretty specific. It’s also very curious. Code coverage is a side effect of good testing, not a driver of good tests. In fact, it’s been repeatedly demonstrated that imposing this metric as a measure of quality results in dangerously poor “tests”. So, why would NIST recommend this? I can only assume the authors believe people will read past the summary. Spoilers: they don’t.
When you read 3 pages ahead to subsection 2.7, they soften the message from a mandate to a recommendation:
“Most code should be executed during unit testing. We recommend that executing the test suite achieves a minimum of 80 % statement coverage.”
Much later in section 3.3, they touch on it again. First, they misleadingly imply that test coverage measures the quality of the testing:
The percentage of coverage, e.g., 80 % statement coverage, is one measure of the thoroughness of a test suite.
No, it means that 80% of the code is being run by test code. They are only assuming effective tests. However, they finally get to the truth about the metric in the next sentance.
Low coverage indicates inadequate testing, but very high code coverage guarantees little.
Ahhhh. So I can’t just demand a test coverage metric and get good tests? Perhaps that warning should be in the summary to encourage further thought on this?
What does mandating this actually accomplish? It depends on the team. Teams that take their job seriously and have had experience/training in testing will test their code. Depending on the context, it’s very common to see coverage in the mid-80 to mid-90 percentile. They aren’t chasing the metric. It’s only a side effect of their quality process. Those teams do not need a mandated goal. The remaining teams either are not incentivized to care about good testing because they aren’t responsible for fixing things, they are being pushed to deliver fast without concern for quality, or they lack the training required to test well (far too common). Mandating coverage in those cases will result in high coverage of low-quality or zero-quality tests.
So, what does that look like?
Requirement: add two integers. If one or more of the parameters is a whole number, return a null value.
We’ve written our code, now we need to make sure we hit our coverage mandate. Here are tests that provide 100% line, function, and branch test coverage.
These test nothing meaningful about the function but exceeded expectations on our coverage mandate. However, we are working far too hard to meet that mandate. We have a backlog of features to deliver and hard deadlines. Besides, there’s a support team responsible for fixing things in case we make a mistake, so we need to speed up this test coverage thing.
That’s better. We get exactly the same level of code coverage reported without all of the hassles of coming up with assertions to validate the behavior. Next story!
While this is a contrived example, it’s not far from the truth. I’ve witnessed real systems tested in a similar fashion. I’ve seen this in multiple organizations when a mandate was imposed. Others report the same. Dave Farley talks about it in the “Modern Software Engineering” chapter on measuring:
“At one of my clients, they decided that they could improve the quality of their code by increasing the level of test coverage. So, they began a project to institute the measurement, collected the data, and adopted a policy to encourage improved test coverage. They set a target of “80 percent test coverage.” Then they used that measurement to incentivize their development teams, bonuses were tied to hitting targets in test coverage.
Guess what? They achieved their goal!
Some time later, they analyzed the tests that they had and found that more than 25 percent of their tests had no assertions in them at all. So they had paid people on development teams, via their bonuses, to write tests that tested nothing at all."> Modern Software Engineering — David Farley
It’s relatively easy to find tests that have no assertions. However, I’ve personally reviewed many examples of tests with meaningless assertions. Those can only be found by a manual review of the test code and typically only after the application causes a production incident. What value is 80% coverage you do not trust? It’s a lower value than 0% coverage. At least with 0% you know there are no tests.
“But we need to encourage testing!”, you say. No, we don’t. We need to encourage the continuous and sustainable delivery of valuable solutions. We need metrics that create the right balance of conditions to improve our outcomes. Measure production defect creation rates (with budgets), production delivery frequency, and the cycle time from starting work to production delivery. This creates offsetting guardrails where we cannot make all three better without improving our overall quality process, improving how we define the work to be done, and keeping code complexity low. Measuring our ability to deliver small batches while maintaining stability incentivizes upstream quality process improvement and allows us to improve feedback on the actual value delivered. This also acts as a forcing function for our test suites to be both fast and effective. That’s critical when we need to recover quickly from an incident or install a security patch safely.
If you are using high test coverage as an assessment of quality or risk, we should talk.
Optimizing Human Resources

The job of management is to ensure that staff is fully utilized at all times. Resources are being paid for a day’s work, they need to head down working for at least a full day, preferably more. Since we are speaking of DevOps, let’s discuss two real-world examples of management effectively ensuring that all resources are fully utilized in Dev and Ops.
Optimizing Development Resources
The most effective method I’ve seen for this was for a large team of 19 resources. The team was a mixture of experience from barely out of college to 15–20 years as developers. The manager, naturally, wanted to make sure everyone was working and wanted a good way to stack rank resources for their annual review. Jira dashboards were the obvious choice. By dashboarding the number of tasks each person completed during the sprint, the manager could easily discover who the top developers were and who were candidates for “trimming the bottom of the bell curve”. This lightened the manager’s workload, focused the developers on increasing output, and helped the senior engineers by eliminating the needless distraction of helping others who were not as proficient.
Speed to Resolution
With the success of maximizing development output, how do we get the most work out of operations? It's very similar.
A friend explained to me how operations are measured in his organization. Individual metrics are tracked for how many tickets are closed and the average time required to close tickets. These individual metrics are tracked against the team’s average for the week. This allows the team manager to ensure everyone is pulling their weight and that the recurring requests are closed in a timely way. This made management in the area happy because they finally found a way to ensure the remote workforce was earning their pay.
Outcomes
While neither example above included a process to inspect outcomes and compare them to desired results, outcomes were observed.
Development Outcomes
- Staff Engineers focused on the tactical work of closing issues rather than the work of helping set technical direction, growing their replacements, looking for ways to improve overall operability and maintainability of the application, and ensuring general technical excellence on the team.
- Work in progress increased because reviewing someone else’s code didn’t help you make your numbers.
- Answering questions and helping others reflected negatively on your numbers.
Operations Outcomes
- The drive to close tickets disincentivized understanding and correcting root causes.
- Many common support requests for access or system configuration could have been automated and made self-service, but automating them would have taken time away from closing tickets.
- Tickets were closed without full resolutions. Customers could always open another ticket.
- Helping someone close a ticket had a negative impact on the person providing the help. Questions were discouraged.

What to Manage?
Individual metrics applied in a team context will destroy teamwork. If the goal is to make it easier to “find slackers” instead of improving the outcomes, individual metrics are one of the shortest paths to turning a team into just a group of individuals who share a common set of work. Alternately, placing metrics around business goals, value hypotheses, delivered quality, and improving the effectiveness and sustainability of value delivery will improve outcomes for everyone involved. Yes, many organizations have people who do not pull their weight. It’s cutting off your nose to spite your face to use metrics to try to find that. Instead, observe how the team works. Look for the leaders who are helping others. Look for the glue people who help everyone move in the same direction. Look for the idea people who are seeking better ways and helping the team run experiments. None of that can be measured except by what the team delivers. Focus on the outcomes.
For more pro tips on scaling DevOps, check out ScaledAgileDevOps.com
DORA Metrics Tips

Since Accelerate was published in 2018, “DORA metrics” have become increasingly popular for measuring IT performance. More vendors are creating dashboards or integrating these metrics into their existing pipeline tooling. However, the context is getting lost in the race to deliver these features to customers.
First, what are the DORA metrics?
 “Accelerate”
“Accelerate”
Nicole Forsgren PhD, Jez Humble & Gene Kim
In 2021 I wrote a paper for IT Revolution where I go into detail on how to misuse and abuse these. Today, let’s cover some high-level tips to consider before attempting to use these.
1. Don’t Use Them
More specifically, don’t naively use them without understanding what they represent and what they do not. Having good DORA metrics does not mean you are a high-performing organization. Delivering very stable, very small batches of useless crap doesn’t make you high performing. However, delivering large batches and/or having an unstable system will definitely cause a negative impact on your business performance. Do not use them to track positive performance. The correct way to use them is as an indicator for things that could be improved so you can investigate “what’ and “how”.
2. Understand the Definitions
I’ve reviewed many vendors’ implementations of DORA metrics and most of them use incorrect definitions.
Most tools define “Change Fail %” as the percentage of changes that cause an outage or otherwise need to be backed out. Nope. Read “Accelerate”.
“…result in degraded service or subsequently require remediation (e.g., lead to service impairment or outage, require a hotfix, a rollback, a fix-forward, or a patch).”
So, a change that results in a defect. Any defect.
Another that is almost always measured incorrectly is “lead time”. This is almost always measured from when the code is checked in until it is delivered, but that’s only the automated portion. In a follow-up response to a critical book review, Jez and Nicole state,
Measuring just the robot portion is much easier for most vendors to automate because it requires less tool integration. However, it tells you almost nothing about where improvement opportunities exist. Most of the issues are upstream of there. Measure the entire development flow.
There are more incorrect definitions that tools use. Read “Accelerate”, understand the intent, and don’t blindly trust the implementation of a tool.
3. Use All or None
“This quarter we’ll focus on improving delivery frequency. next quarter we’ll focus on the next metric.”
Rapid delivery without a disciplined quality process is just dangerous. Speed isn’t the goal. Increased quality feedback is the goal. We need signals for quality and batch size.
4. They are Lagging Indicators
While they can be leading indicators for IT performance, they are lagging indicators for engineering excellence and good product management. Measuring how frequently working code is integrated into the trunk and the wait times for handing off work will help identify things that will improve the DORA outcomes.
5. How to Improve?
The DORA metrics tell us that high-performing organizations focus on the delivery discipline of continuous delivery. Focus on “why can’t we deliver working software daily?” and fix those things.
A lot of context and subtlety are required to identify issues and improve outcomes. The best roadmap for this in Accelerate isn’t the metrics, it’s the list of 24 behaviors in Appendix A. Simply publishing DORA metrics is usually a destructive act. Use them as a tool to inform health, but only as part of a broader strategy that includes organization architecture improvement, mentoring teams, focusing on product management, better incentives, and everything else that is impacting value delivery.
SAFe Isn't

I frequently find myself in conversations about Scaled Agile Framework (SAFe) and its utility or lack thereof. My opinions are based on both direct experiences in an organization that started using it and from comparing notes with colleagues in other large organizations, including many who are SAFe certified. This is my attempt to explain why I hold the opinion I hold and to challenge SAFe apologists to stop hand waving the criticisms away.
Tl; dr: SAFe bad.
My experience with SAFe began after it was inflicted upon my organization as a method of scaling the pockets of agile experiments. The organization was a global enterprise with thousands of developers and multiple divisions and product lines. In an organization like this, moving from waterfall development (we even went through PMI training) to an agile workflow can be a challenge. At the time, I worked in an area that was organized in a way that should have been the sweet spot for SAFe. We had hundreds of developers on several project teams working as feature factories on a shared codebase. We had a large number of SAFe consultants working to “transform” our area as well as other areas of the enterprise.
After a couple of years, our outcomes still were not very agile. we had added several new jobs for ex-project managers to manage the layers of processes for coordinating teams. We also had the two standard SAFe cadences. Every team was required to execute Scrum with 2-week sprints. Every 10 weeks we had a 2-day meeting to plan the next “Production Increment”. There we would plan what features would be delivered in the next 10 weeks and when those features would be delivered. The latter was to ensure that the hard dependencies between teams would align to the right “Release Train.” On the surface, this might sound like success and I’m always curious when people claim they have successfully implemented SAFe if this is their definition of success. However, that outcome was a complete failure. Let’s look at why.
Fake Improvement

Management felt they had control over the situation and that things were less chaotic. There were 10 weeks of planned work aligned to deliver dependencies in a coordinated manner and 2-week sprints to track the planned against delivered. Project managers were replaced with “program managers” and “product owners” who still reported to the PMO. It also created the new “Release Train Engineer” role to coordinate the large, multi-team scheduled releases every 10 weeks. Establishing these cadences and these roles prevented any further improvement. Why?
First, the PI cadence gave the PMO what they felt comfortable with; “Agile Transformation” without the risk of disrupting project plans. However, five 2-week sprints with processes to align dependencies is just a waterfall Gantt chart. It fails for the same reason waterfall and all fake agile fail, it assumes things will turn out as planned. Product development is not deterministic and laying out a determinist plan is objectively the wrong path to delivering a successful product. Reality is far more complex and the smart assumption is that things will NOT turn out as planned because proper product development is hypothesis-driven. The outcome was that we still delivered late but now had more process overhead, more management layers, and more meetings. However, the PMO felt better.
Next, the “Release Train Engineers”. These were not engineers. They were responsible for holding teams accountable that all of the required hard dependencies aligned for the next “release train”. The fact that this coordination is needed is an architectural smell, not a feature. If we have hard dependencies between teams (more than one team must deploy at the same time) then those teams can only deliver at the speed of the slowest team. That’s not the worst problem. Operational stability is. No team can fix anything safely without validating with the other teams. During a production incident, this is a major problem. When we try to handle this with process, it hides the real problem and the problem never gets better. If your job is to manage this process, then you have no incentive to point out the problem. Trains are the least agile form of moving freight and are only used for very large batches. Large batches are the antithesis of the goal of product development. Software ain’t coal.
Things SAFe Apologists Say
“I’m sorry you had a bad experience. It sounds like SAFe wasn’t implemented properly in your organization.”
Given the number of people reporting bad outcomes, perhaps the SAFe certification process needs more rigor? Currently, it appears to be structured to generate certification income rather than industry improvement. The versioning scheme is brilliant. “Oh, you’re only SAFe 4.0? We are on 5.0 now! Make sure and pay to upgrade.” A friend told me that he got certified and then invited to spend ~$300 to renew his certification the following year. He declined.
“What you experienced was just ‘shu’, the learning stage. As your organization learns, you are expected to move on to ‘ha’ and then finally to ‘ri’ when you master it and stop using the framework when you find that the framework is too restrictive!”
Except that the starting point creates middle management jobs that aren’t needed when you get to the end and have loosely coupled product teams. Except that the goal is mastering the framework because that’s what people are rewarded for. Therefore, improvement will stagnate as soon as those jobs become entrenched because making things better eliminates the need for those jobs. The starting point also removes ownership from teams that you will find difficult to get back. Teams simply become “accountable.” This disengages motivation. It’s FAR more effective to show people where they are in relation to “good” and help them along the path than to spoon-feed “this is the next step”. The only people who benefit from hand-holding are the people paid to hold hands. We can skip to the end by relentlessly improving the actual problems that prevent us from getting to “good”.
“People bashing SAFe are just trying to get attention because it’s trendy to bash SAFe.”
There are more interesting things to talk about to get attention. ML is much more trendy. If you put your hand in a fire and get burned, is it attention-seeking to warn others so they don’t need to learn the lesson from direct experience? Using the experience of others is less painful. I personally push back on SAFe because of how long it delayed improvement in the organization I worked for and how fast we were able to improve business outcomes and team morale when we focused on solving the problems rather than applying a process framework to band-aid them.
“SAFe is like a recipe book. You just pick the recipes you need!”
SAFe is exactly like a recipe book that contains recipes for coq en vin, beef Wellington, tres leches cake, how to reconstitute powdered eggs for 2000 people, and the correct levels of arsenic to use to avoid killing someone instantly.
“There are some really good things in SAFe”
There sure are and I can point to the original sources for all of those good practices SAFe has cargo-culted. It’s entertaining to be part of driving a good practice and see SAFe adopt, brand, and sell it later. The “value add” that SAFe brings is mixing those good practices with a bunch of bad practices and charging people to get a badge for LinkedIn. It’s a minefield for people to navigate. If you already know how to cook well, then you don’t need the book. If you don’t, then you’ll serve reconstituted eggs with arsenic seasoning.
The goal of SAFe is SAFe, not better value delivery. You can tell by what metrics they value.
“Measuring Competency: Achieving business agility requires a significant degree of expertise across the Seven SAFe Core Competencies. While each competency can deliver value independently, they are also interdependent in that true business agility can be present only when the enterprise achieves a meaningful state of mastery of all. © Scaled Agile, Inc.”
Recovering
How did we fix this nightmare? Instead of calling in more consultants, the area SVP gave us (the senior engineers) a mission, “we need to go to production every 2 weeks instead of every quarter.” If something hurts, do it more often! He gave us free rein to solve the problem and air cover to clear roadblocks. Our solution? “We need to implement continuous delivery and we need to go to production daily.” We re-architected the teams into product teams to mirror the application architecture we wanted. We converted hard dependencies to soft dependencies with a loosely coupled architecture built by teams formed around business domains. We used modern technical practices to handle dependencies in code instead of managing them. Instead of PI planning, we talked to each other and used API contract-driven development. Teams were able to deploy independently in any sequence and deliver against the area roadmap. Over time, the RTEs had to find positions elsewhere. We didn’t need them. Teams chose the method of working that worked best for them and they owned the outcomes of their decisions. Most importantly, we were delivering multiple times per week with higher morale and ownership.
“Ah, but have you tried LeSS?! LeSS will fix it!”
SAFe is the framework I’m most familiar with but I’m highly skeptical of any framework. I’ve enough experience to know that there are no cookie-cutter solutions and that improving flow requires context. Agile scaling frameworks are unlikely to result in agility because they lack context. Focus on improving organization architecture, application architecture, and developer experience and understanding there is no such thing as deterministic product development. We are delivering experiments to verify a value hypothesis. We fail less if we do that faster and smaller. Scaling makes things bigger. Don’t scale. Descale and improve throughput and feedback.
Written on May 6, 2022 by Bryan Finster.
Originally published on Medium
Flying Cars are Boring

Continuous delivery can be a frustrating topic. Those of us who use this workflow will never go back to legacy ways of working. The lack of Fear Driven Development and objectively better results are amazing. We get so much joy from building things that deliver more value with less effort and less waste. On the flip side, those who haven’t worked that way rarely believe and cannot seem to imagine that pain reduction is possible. So instead of spending time on ways to make defect detection ever faster and to make pipelines even more secure, we spend time trying to convince people who are in pain about the basics to help them have less pain. It’s one of the reasons many of us are so passionate about MinimumCD.org as a method to help people get over the hump at the beginning. Yet, we still run into the same conversations ad nauseam
“CD won’t work here. Our developers aren’t skilled enough. CD is too dangerous. Our customers don’t need changes that often.”
All of those are false.
Imagine you have frequent conversations with people about flying cars with people who have never seen humans fly. You start every conversation with “flight is possible” and then spend the next month countering arguments about the hubris of Icarus and how dangerous it is to slip the surly bonds of earth. Now imagine you get the opportunity to visit a place where flying cars aren’t just common but are so ubiquitous and boring that no one talks about them. Then you come back and hear the same tired arguments again. This happened to me recently.
I’ve been an advocate of continuous delivery since my first experience on a team learning how to solve the problem of “why can’t we deliver today’s changes to production today?” Solving all of the related problems of shrinking the batch size of everything, testing better, working as a team better, and getting faster feedback from the end-user removes pain that I had always thought was just part of the job. In 2017, a teammate and I gave a talk at DevOps Enterprise Summit about the impact of CD on teams and said, “it made us love development again!” Since then, I’ve spoken with peers in other organizations who are trying to help roll out CD. The reality is that the vast majority of success stories are not widespread in their organizations. The changes required are mostly people-related and are far larger than rolling out new tools.
Recently, I visited a company with a reputation for modern development practices to learn how they work. For the first time, I was able to witness an example where reputation understated reality. Continuous delivery permeated every thought of everyone I spoke to whether discussing software or manufacturing. Spending time there was both exhilarating and a little frustrating. I kept thinking, “why is it so hard to convince everyone that this is obviously the best way to work?”
The best measure of delivery is outcomes. This company is the industry leader in its field. The problems they have been solving are nothing short of revolutionary. They are on the bleeding edge of what they do and continue to astonish people by delivering things many consider impossible. Their success is directly related to the same things I’ve always found to be important: mission, mindset, and execution.
Mission
If you ask anyone at the company, they will tell you the company’s long-term mission. The scope of that mission is breathtakingly aspirational. Everyone can tell you how their work contributes to the mission and how their team’s work contributes to the larger mission of the company. There is no separation between “business” and “IT” or “manufacturing” and “software”. There is one team, one mission.
Mindset
“We are all engineers solving hard problems.”
Sitting at the coffee bar, I could watch new hardware being built to my left using revolutionary manufacturing processes that enable rapid design change at scale. Operations on my right monitored delivered products and everyone could see the status of critical deliveries. If a new hardware design is sent to manufacturing, the engineers assemble the first examples themselves to ensure they are easy to assemble to prevent increasing the effort of manufacturing. Simplicity drives everything they do. One software engineer told me, “if you aren’t adding something back to the design, you haven’t removed enough yet.” Extreme Programming is corporate culture.
There was a passion for the work in everyone I talked to, hardware, software, and even the baristas at the coffee bar. This shared understanding gives everyone a North Star to compare to their daily work. Everyone has a say in the success of what they do and anyone at any level can “pull the andon” if they see something that appears unsafe. Mistakes could cost lives and everyone takes that seriously.
As I said, mistakes could cost lives. This is serious work they do and they want to be safe while also pushing the envelope. They do this with a CD mindset. One of the frequent arguments against continuous delivery is that it’s too risky. “If we deploy the wrong change to this device it could kill someone. We need to make sure it’s perfect first!” My experience has been that the more you strive for perfection on every delivery, the less perfect it will be. Larger changes are the result and large changes contain large defects. If we put processes in place to optimize for learning, rapid feedback, and automating checks for the things we learned then we are far more likely to find problems early and reduce risk. It also gives us the confidence to rapidly innovate rather than stagnate.
Execution
“Efficient and effective delivery to enable rapid improvement”
I’ve been watching this company for several years as they delivered hardware. I was very skeptical at first about what they claimed they would do. However, I’ve been astonished at the rapid improvements I’ve seen and recognized the workflow they were using. Usually, with complex hardware, there will be years of development time, an assembly line will be built, and then every delivery from the assembly line will be the same. What I’ve witnessed though is that they see every delivered unit as an opportunity to learn and improve. Each one is a prototype with a delivery goal as well as a learning goal. Once they have one feature working as intended, they immediately begin iterating on the next feature. This is how software should be delivered, but to see it done with hardware and at the scale they do it is astounding. Pulling back the covers reveals that the CD mindset permeates all the way to the design of their factory floors. They design everything for rapid change. They know that to meet their goals and to stay ahead of their competition they must continuously improve everything they do, and even their assembly line layout cannot be a constraint.
Naturally, this applies to their software as well. The refreshing thing for me was that continuous delivery isn’t something they talk about. It’s just the underlying assumption in everything. They know that operational stability depends on the ability to correct issues rapidly so they practice delivering constantly. In one example, they have several thousand devices deployed globally that require significant uptime. To ensure this, they update weekly and test in production. If a post-deploy test fails, the device self-heals by reverting the change without human intervention. They act just like well-engineered micro-services. One of the core behaviors of CD is trunk-based development. This branching pattern frequently receives pushback when we talk about it, but it is not possible to execute CD without it. One engineer told me that they do TBD but used to use release branches. They found this to be both process-heavy and error-prone. “We decided we needed to harden our CI process and release from the trunk.” They replaced process overhead with improved quality gates in their pipeline. This saved effort and reduced errors. Again, this isn’t for some tertiary system. This is the process for the core OS of their hardware.
There’s so much more that could be said, but all of it comes from an organization that has a deep understanding that when you are inventing a new solution, this is the best way to do that. Optimize everything for better communication, faster feedback, efficiency, and learning. They have repeatedly demonstrated with real-world outcomes that they are right.
They aren’t special. Nothing about what they are building makes this easier. What they have is a shared mission, a mindset driven by innovation and winning, and disciplined execution. It’s baked into the culture. Flying cars are real and boring there. No one talks about them. They just use them to beat everyone else in their business space.
Written on May 6, 2022 by Bryan Finster.
Originally published on Medium
Agile Deepities

A “deepity” is a statement that sounds profound but isn’t. “To the extent that it’s true, it doesn’t have to matter. To the extent that it has to matter, it isn’t true (if it actually means anything).” <See Deepity
“Agile is a culture!” and “Agile is a mindset!” are deepities. To the extent they are true, they tells us almost nothing useful or actionable. If we are trying to convince people that there are better ways of working, they are counterproductive because they cause frustration.
“Sure, but HOW do we improve? Tell me something I can use! What’s the process?”
“Agile isn’t a process!”
That flawed understanding of “Agile” is why some people claim that documentation and planning aren’t “Agile” either. That’s a good way to fail. “Process” is specifically called out as something that does exist in the Manifesto. It’s just less important than people working together. Let’s eliminate all processes and see how “Agile” we are. Hint: we aren’t.
“Process: a series of actions or steps taken in order to achieve a particular end.”
Is “Agile” the desired end? OMG, no! The desired end is the continuous delivery of value to the end-user.
What are the steps?
- We need to systematically tear down silos and organize communication paths to reduce information loss so that we can…
- Systematically reduce the cost of change so that we can…
- Systematically reduce changeset size so that we can…
- Get faster feedback on the quality of our ideas and adjust to deliver better outcomes.
- We need to use good development practices to reduce production waste.
- We need to use good marketing and user research practices to reduce bad or irrelevant ideas.
We don’t need an “Agile mindset.” We need a mindset of “deliver useful things to the end-user so they want to use our products. Do it at a total cost that allows us to do sustainably and do it better than the competition. If we don’t then we cease to have users.” We need a mindset of “what we are doing is probably wrong. How can we find out quickly and adjust?”
Improving the flow of product delivery isn’t a culture or a mindset. Culture is an outcome of how an organization works. “Mindset” is something people have. A toxic culture will not work as well as a generative culture, but it can still result in better outcomes than a generative culture with the wrong goals or wrong processes to achieve them.
We don’t convince decision-makers with “culture” and “mindset”. We convince design makers with better outcomes and then show industry data on how better processes encourage a culture where improvement can flourish so we can better meet our value delivery goals.
Written on May 3, 2022 by Bryan Finster.
Originally published on Medium
Business Value Isn't My Job

I was recently in a conversation on social media about the role of a software engineer.
As a SWE, what you bring to the table is knowledge of efficient algorithms and data structures for general computation. If a company needs domain expert they will hire one, this is typically a product owner or business analyst.
Oh, dear.
When I shared that experience, many other software engineers assumed the opinion came from a toxic manager who just wanted code monkeys to shut up and type. It didn’t. It came from another developer. They said that their talents were wasted on understanding the business problem and that if you were trying to be good at two things (computer science and the business domain) you probably weren’t as good a developer as you claimed. When questioned on this, they doubled down.
If the business tanks and you’ve fulfilled your role as efficiently as possible why would you care? The market is begging for good SWEs. If we continue to fill in the gaps in management we’re just being enablers. People need to fail to learn.
Perhaps “Ethics” would be a good addition to the CS core curriculum in universities.
As a software engineer, it’s not our job to drive business value. That’s why management and leadership are being paid and followed. Understanding the mechanics of development is why we study SWE and CS, it’s the entire value prop we bring to the table.
That may be all that you bring. You’ll not go far though and you’ll never work on my team.
Someone else responded,
“But what if some people could be good at two things at once? Seems like some companies might like to pay for that.”
Indeed they would. The only exception I’d take is that it’s not “being good at two things at once.” It’s being good at one thing, software engineering.
It’s time for real talk
If I am a carpenter, I need to know how to use my tools. I need to know how to execute joints that are tight, but not too tight. I need to understand how wood reacts to environmental changes and how to allow for those changes. I also need to understand what I’m building, why I’m building it, and what the goals of that structure are.
I recently had a deck built. The team of two that built it were professionals, not “hammer monkeys.” They didn’t require constant direction from the owner. Not only were their results well-executed, but they knew how to communicate to the customer (me). They understood how to address unexpected challenges that come with modifying an existing house and how to communicate bad news when it was discovered. They knew how to suggest changes that would both be better for the structure and for the final usability of the deck. It is not “trying to be good at two things” to also understand how to read plans, spot mistakes, and correct the mistakes. It’s not “trying to be good at two things” to understand how to communicate and get feedback from the end-user. It’s not “trying to be good at two things” to suggest design improvements. It. Is. The Job.
After sharing this experience, I heard from senior engineers, engineering managers, CTOs, and CEOs about the difficulty they are having hiring competent engineers who want to learn about their business so they can effectively solve problems.
I work as a senior software engineer solving the business problems and one of the problems we have is that too many coders expect to get exactly defined programming work somebody else prioritizes and defines.
I even had some executives offering me a job.
This is a sorry reflection on the state of our profession. We need to do better.
Be a professional
Professional software engineers take a broader view than computer science. We aren’t in academia and this isn’t a hobby. We need to deliver business results. The Apollo flight computer wasn’t programmed by mere coders. Software engineers did that. They understood the problem they were solving. Eagle only landed due to resiliency features the development team added because they understood the problems. No one specified those.
If you accept a job to help a company meet its goals, the ethical position to take is to fulfill your side of that agreement. Taking their money to play, build your resume, or deflect work is unethical. The code is a small fraction of your job. Learn the rest of it or go back to coding as a hobby and pay the bills flipping burgers. You’ll be more valuable to the team that way.
IMO if you’re worried about business value you’re not only devaluing the product team but also making inefficient use of your own experience and education.
Just wow! We are the product team. Level up.
How did we get here?
Mismanagement and bad incentives. Developer interviews vary wildly. I’ve sat in and performed interviews for senior engineers. Strangely, we never talked about how to reverse a binary tree. The conversations were entirely around solving real problems. However, many companies use things like LeetCode problems for interviews. I can only assume they lack any competent software engineers or are too lazy to do actual assessments. The result is they optimize for hiring people who can memorize solutions to kata and annoy people who can solve the problems they actually have. They work hard to attract people who lack the ability or desire to understand the real problems. Then they complain.
It’s time for engineering management to level up too. If you don’t understand product development, how are you competent to make hiring decisions?
Why do I care?
I mean, the more half-trained, lazy, and unethical developers there are in the market, the less competition there is for real professionals, right? No. There are many of us out there fighting to improve our industry and the lives of our colleagues. We are tired of poor quality. We are tired of developers being treated like fungible assets that are as replaceable as LEGOs. Those two problems are tightly coupled. We want everyone, developers, end-users, and everyone else in the value stream to live better lives with better outcomes. We want to work on teams of professionals because it’s just more fun to deliver things that help real people.
I’m not a stonemason. I build cathedrals. I have stories about how things I’ve worked on have not just helped but have transformed people’s lives and the lives of their families. I cannot imagine anything more rewarding. If you are reading this and also internally screaming, let’s all push to fix this. If you think I’m being unreasonable, I think Wendy’s is hiring.
Written on April 12, 2022 by Bryan Finster.
Originally published on Medium