This is the multi-page printable view of this section. Click here to print.
5-Minute DevOps Blog
- 2022
- The Most Ignored Aspect of Quality
- Emotional Testing
- DevOps or SRE?
- The Most Dangerous Metric
- Optimizing Human Resources
- DORA Metrics Tips
- SAFe Isn't
- Flying Cars are Boring
- Agile Deepities
- Business Value Isn't My Job
- 2021
- 2022 Reading List
- What is a Production Issue?
- Upgrading the Agile Manifesto
- That's Not Continuous Delivery
- Agile Rehab
- Development Pattern TLAs
- Choosing the Right Tools
- Constructive Pessimism
- The Metrics are Lying
- Scrum or Kanban?
- Measuring Goals
- The Thin Red Line
- Metric Mythconceptions
- Storytime
- Chaos Engineering
- Continuous Delivery FAQ
- The Value of Code Coverage
- Measuring to Fail
- 2020
- Holiday Special
- The Only Metric That Matters
- Testing 101
- When to Resolve Tech Debt
- Organizing for Failure
- Forking, Branching, or Mainline?
- Schrödinger's Pipeline
- You Can't Measure Quality
- Standardizing to Scale
- DevOps Darwinism
- 2019
- Liters Are Not a Unit of Distance
- Engineering Culture Change with CI
- Removing Drama from Delivery
- Effective Testing
- GitFlow Best Practices
- Designing Product Teams
- You Don't Need Story Points
- What's a User Story?
- 2018
2022
The Most Ignored Aspect of Quality
 https://www.flickr.com/photos/pdamsten
https://www.flickr.com/photos/pdamsten
I was speaking to a friend recently about a production incident he was involved with. He said he noted several things that could be improved to help the team with their response. I asked if a postmortem was done.
“Yes”, he said. “There was an attempt at a postmortem.”
“An attempt? What was the outcome?”, I asked.
“It wasn’t received well by the area’s Director. The focus was more on the team’s behavior and the fact that the incident had occurred at all rather than lessons learned.”
“That’s unfortunate. That makes us much less safe.”, I responded.
Why is that? If I lack trust; if I think I may be punished for something going wrong, I promise nothing will ever go wrong. We’ll never find code or network vulnerabilities. We’ll never find issues that might expose sensitive data. There will be no defects, just small feature requests that are incorrectly reported as defects until we fix the classification. Everything will be fine.
That, of course, is nonsense. Things will go wrong. However, without a culture of trust where I know we are all trying to continuously improve the system rather than finding people to blame for failure, I will hide any mistake that may blow back on me. We will just cross our fingers and hope it doesn’t impact the organization.
Trust is the first impediment to security and quality. Lack of trust within the organization results in fragile systems that put us all at risk.
Responding to Error
In 1976, NASA established the Aviation Safety Reporting System (ASRS). This system allows pilots to confidentially self-report accidents they are involved in so that NASA can collect data and provide guidance based on the accident reports to the FAA and the airlines. Why would pilots report their errors? If the FAA becomes aware of the accident and then tries to impose civil penalties, the fact that the pilot had submitted the report exempts them from punishment for minor infractions. This allows the rest of the industry to learn from mistakes and to steadily improve the safety of the airways.
The Toyota Production System recognizes that errors occur as well. They also recognize the error is caused by how the production system is designed, not by the people. The famous “Andon cord” is used when someone notices a problem. They stop the line and problem analysis experts descend on the area and use the “Five Whys” to analyze why the issue occurred to find ways to harden the process against re-occurrence. In the end, a report with recommended actions is created and acted upon. There’s no punishment for the person reporting the problem even if it was the result of something they did personally. The goal is to make it harder for people to make mistakes. There is only one way to get punished for a problem, failure to report it.
These two organizations gather problems, learn from them, and make recommendations for systemic changes to make those problems harder to reoccur. This is exactly the way a high-performing organization will treat things like quality and security problems. No excuses, no punishment, just an honest examination of the gaps in the system.
“What modifications could we make to make it harder for that to happen?”
Screwing Trust Up
Here’s a real-life example of management not understanding system thinking, destroying trust, and making things less safe.
A large organization had been struggling with several production changes that went poorly resulting in a significant impact on multiple occasions. In some cases, the causes could be identified with much fewer than five “whys”. However, no postmortems were done. Some people were held individually accountable. The management “fix” was to implement a change approval process with several levels of approval so that the person representing the change could assure at least three layers of management that they had, indeed, checked all of the quality boxes. Just to be sure, all changes must occur after hours to reduce the impact of failure. If a change fails, the person who made the change will be required to train on how to make changes correctly.
What is the impact of this? Simply that nothing was improved. Process overhead was added that injected a minimum of five days of lead time. This caused ongoing delays in delivering business capabilities. The underlying issues that allowed the problems to occur were never addressed. A side effect is that the people who focus on system improvement in their teams, the actual 10x engineers who elevate those around them, are leaving the organization. This makes the company objectively worse and less likely to improve in the future.
Fixing the Problems
Let’s compare those organizations to the incident response my friend was involved in. Trust needs to be rebuilt in that organization to improve safety and security. There should be a postmortem about how the original postmortem was performed followed by action to improve the original postmortem and action to address the underlying system failures that are uncovered. The management and the team should work together to solve the problem and understand that the currently defined processes are the defect, not the people performing them. Working together will help rebuild the trust that has been damaged or lost.
Trust is the first impediment to value delivery. Without trust, everything degrades. Building a culture of psychological safety isn’t some “warm and fuzzy nonsense.” The building of that culture should be a pragmatic response to the desire to improve our outcomes. Building trust is an ongoing effort and when trust is damaged, rebuilding it needs to be a priority. Growing trust is work. All that’s required to destroy it is to do nothing.
Emotional Testing

Recently someone asked me, “Does code have to be tested by code to be considered tested? Who tests the code that tests the code?”
This was in the context of when to write tests. He was asserting that we only want to invest in tests after we deliver a release and confirm the value and that manual testing and delaying proper testing is fine. He is wrong.
“Does code have to be tested by code to be considered tested?”
To be considered tested correctly, yes. The code works the same way every time. People are variable. Tests should be deterministic. QED
“Who tests the code that tests the code?”
That’s a really strange question. Who tests human testing? The implication is that humans can test better than robots. It’s an emotional need I hear from many people, but mostly from people who aren’t responsible for operating in production. Let’s work through this logic.
Manual acceptance testing: Test scenarios are defined before coding starts. Coding is completed and someone sets up data for the test scenarios and executes the tests. After the manual testing is done then the release is shipped.
Automated acceptance testing: Test scenarios are defined before coding starts. Coding and test automation are done concurrently. When done correctly, they are done by the same person. Tests run in the CD pipeline. Tests pass and the release is shipped.
In those two scenarios, where is the process where the manual testing is “better”? In both cases, the test for how well the testing was done is delivering and observing how the end-user responds. Production is the test for any test, no matter how it is done. The problem should be obvious though. If the test was bad, how do we fix it? Well, it depends on why the test was bad.
Misunderstood Requirements
This is a common reason and it impacts both kinds of testing.
With test automation, we modify the test once to correct our understanding of the behavior, and every time we make a code change we verify we have the same understanding.
With manual testing, we modify the test script and re-verify that behavior for the next release.
Similar, but with a key difference. The speed of discovery and error correction will always be slower when a human is doing the work instead of instructing a machine to do it. Some people feel manual testing is faster because they feel busy doing it. An emotional and incorrect response. Another difference is that the automated test, once changed, won’t make a mistake.
Testing Mistakes
While executing the test, an error was created by the person executing the test.
This can happen with both kinds of testing. We could write an automated test with a bug or we could make a mistake executing the test script. However, with automated testing, it can be corrected and will not happen again. With manual testing, it is a risk for every test scenario on every test run. With manual testing, as the scope of testing increases, the likelihood of testing errors increases. This isn’t true with an automated test suite.
Data Configuration Error
With good test data management systems, this can be mitigated somewhat for manual testing but I’ve rarely (never) encountered anyone who said they had a tool that versioned a data set and made that state repeatable on demand. Usually, an unrepeatable set of data is used until it’s used up or a set of data that isn’t representative of a production environment is contrived.
With proper automated testing architecture, we have much better control over the state. In fact, for most test scenarios we can eliminate the state entirely and focus only on the behaviors. We have the ability to minimize and isolate stateful tests to make our tests 100% deterministic, one of the definitions of a good test.
Eliminate All Manual Tests?
For acceptance testing, yes! Is there a place for manual testing? Sure. Exploratory and usability testing are important creative activities. The first is focused on finding scenarios we didn’t think of automating. Then we add these tests. The second is focused on validating how humans feel about using it. That informs future changes. However, there is no place for manual acceptance testing as a gate to delivery.
Manual acceptance testing is slow, non-repeatable, lacks granularity, and lacks determinism. So why do people insist on using it? It’s not a decision based on engineering. It’s an emotional decision based on fear. “I can’t see the testing happening, so it must not be good testing.” People have feared machines since the printing press. We should make decisions based on reality.
If you have manual acceptance tests, everything to the left of testing is made worse. Batch sizes increase, value delivery is delayed, people become more invested in bad features, and customers get lower quality outcomes. Move the emotion to where it belongs, making users desire the outcomes. Improve everyone’s lives by letting people do creative things. Only robots should run scripts.
DevOps or SRE?
A few years ago, one of my friends took a new role and talked about the work we’d been doing on DevOps. His new CTO said, “DevOps is dead! It’s all about SRE now!” Someone is missing the point.

I had dinner recently with Patrick DuBois, who coined “DevOps”, and Andrew Clay Shafer, the “Godfather of DevOps” and we talked about some of the industry challenges, the glacially slow progress toward improvement, and the frequent setbacks we are seeing. There are many reasons for it but much of it comes from people not approaching it with systems thinking. Instead, terms get misused, packaged, and sold. For successful improvement, we need to view the whole system.
I really like Donovan Brown’s definition of DevOps,
“DevOps is the union of people, process, and products to enable continuous delivery of value to our end users”
Simple and direct and makes it clear that we need to address the entire system. In the interest of brevity, let’s look at where some of these pieces fall in the system. The following are some of the major topics. It is in no way exhaustive.
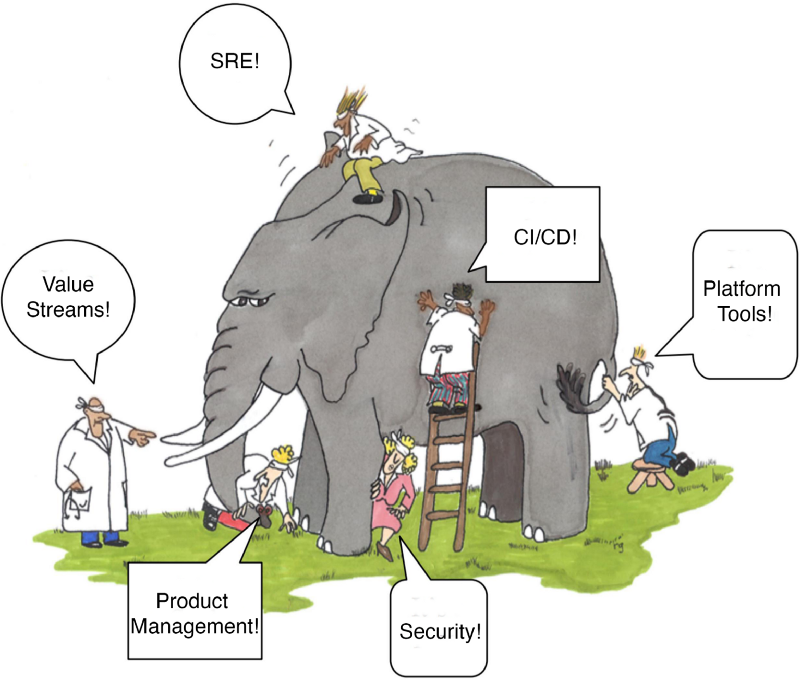 The DevOps Elephant
The DevOps Elephant
Product Management
The whole point is to improve how we deliver products. Product management needs to be on the ball. We cannot assume what we build will be valuable. We need to do our research, make value hypotheses, and find ways to get feedback as quickly as possible on small value experiments. Every delivery is a wager on value vs. wasted effort and larger deliveries are more expensive when we lose the bet. Smaller is always better when trying to invent something new that we hope is valuable.
Value Streams
This is how we organize teams, not just development. Do we have functional silos? How many handoffs or communication paths are required to deliver something? Every handoff adds wait time where work sits idle until it can be picked up by the next person in line. Where are the bottlenecks that are slowing things down? Analyzing those problems and reorganizing things makes it much less costly to deliver value.
Security
“Introducing DevSecOps!”

If we are working to continuously deliver value to the end user, is it valuable if it’s insecure? Security has always been part of DevOps. It’s not a new discipline. We need to be “secure by design” in DevOps instead of the classical Grenade Driven Development approach of building the system and then attempting to secure it with inspection at the end. Security should be a platform that enables secure delivery with tooling and training, not police investigating the “crime of new software.”
Platform and Infrastructure
Our DevOps team is responsible for the configuration of over 300 pipelines!

DevOps isn’t a team or a job. See the above definition. Platform and Infrastructure teams are also enablers of value delivery and should be working to provide self-service solutions that are easy to use so that development teams do not need to know how they work, they just work. Without this, value delivery suffers.
Continuous Delivery
It’s right there in the definition, “continuous delivery of value”. It’s even the very first principle of the Agile Manifesto. CD is not tooling. CD uses tooling to enable a workflow that focuses on a repeatable quality process that can reliably give us feedback on known quality issues before we deliver to the end-user and uncover unforeseen quality issues. This workflow focuses on improving things to enable ever smaller deliveries to accelerate feedback loops from production. It’s not a “throw it over the wall” delivery approach. It’s a quality initiative that enables us to respond quickly to functional, performance, security, or any other quality issue. It also allows the small batch sizes that enable smaller value experiments that reduce the risk and size of lost bets.
SRE
We don’t have DevOps, we have SREs!

Again, DevOps isn’t a job. DevOps is the whole operating model for improving value delivery. Delivery teams need air cover to ensure they are able to focus on their quality process and are not pressured by deadlines to deliver unstable or unusable features. A Site Reliability Organization or similar capability that has the independence to say, “until you are stable, we a returning operational monitoring responsibility to you” is important quality backpressure to prevent things from coming off the rails in the quest for speed. We need smaller, sooner, and more stable. If it’s not stable, it’s not valuable.
Let History Guide Us
If you’d like to learn a bit more about how DevOps started and what the goals are, I suggest looking at what was written by the people who were there at the start. Damon Edwards is one. Check out his recollections.
The Most Dangerous Metric

Measuring humans changes behavior and often not how we’d like. Some metrics are more dangerous than others. The most dangerous metric goal I’ve found so far in software engineering is code coverage.
What’s code coverage? Simply, it’s the measure of the amount of code that is executed by test code. How could this be dangerous at all? Well, things like this happen
“All applications must have a minimum of 80% code coverage!”
A mandate like this is depressingly common in both the public and private sectors. If you ask why in the context of the Department of Defense, you’ll be pointed to NISTIR 8397 which has the following to say about code coverage in the Summary in section 2.0:
“Create code-based (structural) test cases. Add cases as necessary to reach at
least 80 % coverage (2.7).”
That’s pretty specific. It’s also very curious. Code coverage is a side effect of good testing, not a driver of good tests. In fact, it’s been repeatedly demonstrated that imposing this metric as a measure of quality results in dangerously poor “tests”. So, why would NIST recommend this? I can only assume the authors believe people will read past the summary. Spoilers: they don’t.
When you read 3 pages ahead to subsection 2.7, they soften the message from a mandate to a recommendation:
“Most code should be executed during unit testing. We recommend that executing the test suite achieves a minimum of 80 % statement coverage.”
Much later in section 3.3, they touch on it again. First, they misleadingly imply that test coverage measures the quality of the testing:
The percentage of coverage, e.g., 80 % statement coverage, is one measure of the thoroughness of a test suite.
No, it means that 80% of the code is being run by test code. They are only assuming effective tests. However, they finally get to the truth about the metric in the next sentance.
Low coverage indicates inadequate testing, but very high code coverage guarantees little.
Ahhhh. So I can’t just demand a test coverage metric and get good tests? Perhaps that warning should be in the summary to encourage further thought on this?
What does mandating this actually accomplish? It depends on the team. Teams that take their job seriously and have had experience/training in testing will test their code. Depending on the context, it’s very common to see coverage in the mid-80 to mid-90 percentile. They aren’t chasing the metric. It’s only a side effect of their quality process. Those teams do not need a mandated goal. The remaining teams either are not incentivized to care about good testing because they aren’t responsible for fixing things, they are being pushed to deliver fast without concern for quality, or they lack the training required to test well (far too common). Mandating coverage in those cases will result in high coverage of low-quality or zero-quality tests.
So, what does that look like?
Requirement: add two integers. If one or more of the parameters is a whole number, return a null value.
We’ve written our code, now we need to make sure we hit our coverage mandate. Here are tests that provide 100% line, function, and branch test coverage.
These test nothing meaningful about the function but exceeded expectations on our coverage mandate. However, we are working far too hard to meet that mandate. We have a backlog of features to deliver and hard deadlines. Besides, there’s a support team responsible for fixing things in case we make a mistake, so we need to speed up this test coverage thing.
That’s better. We get exactly the same level of code coverage reported without all of the hassles of coming up with assertions to validate the behavior. Next story!
While this is a contrived example, it’s not far from the truth. I’ve witnessed real systems tested in a similar fashion. I’ve seen this in multiple organizations when a mandate was imposed. Others report the same. Dave Farley talks about it in the “Modern Software Engineering” chapter on measuring:
“At one of my clients, they decided that they could improve the quality of their code by increasing the level of test coverage. So, they began a project to institute the measurement, collected the data, and adopted a policy to encourage improved test coverage. They set a target of “80 percent test coverage.” Then they used that measurement to incentivize their development teams, bonuses were tied to hitting targets in test coverage.
Guess what? They achieved their goal!
Some time later, they analyzed the tests that they had and found that more than 25 percent of their tests had no assertions in them at all. So they had paid people on development teams, via their bonuses, to write tests that tested nothing at all."> Modern Software Engineering — David Farley
It’s relatively easy to find tests that have no assertions. However, I’ve personally reviewed many examples of tests with meaningless assertions. Those can only be found by a manual review of the test code and typically only after the application causes a production incident. What value is 80% coverage you do not trust? It’s a lower value than 0% coverage. At least with 0% you know there are no tests.
“But we need to encourage testing!”, you say. No, we don’t. We need to encourage the continuous and sustainable delivery of valuable solutions. We need metrics that create the right balance of conditions to improve our outcomes. Measure production defect creation rates (with budgets), production delivery frequency, and the cycle time from starting work to production delivery. This creates offsetting guardrails where we cannot make all three better without improving our overall quality process, improving how we define the work to be done, and keeping code complexity low. Measuring our ability to deliver small batches while maintaining stability incentivizes upstream quality process improvement and allows us to improve feedback on the actual value delivered. This also acts as a forcing function for our test suites to be both fast and effective. That’s critical when we need to recover quickly from an incident or install a security patch safely.
If you are using high test coverage as an assessment of quality or risk, we should talk.
Optimizing Human Resources

The job of management is to ensure that staff is fully utilized at all times. Resources are being paid for a day’s work, they need to head down working for at least a full day, preferably more. Since we are speaking of DevOps, let’s discuss two real-world examples of management effectively ensuring that all resources are fully utilized in Dev and Ops.
Optimizing Development Resources
The most effective method I’ve seen for this was for a large team of 19 resources. The team was a mixture of experience from barely out of college to 15–20 years as developers. The manager, naturally, wanted to make sure everyone was working and wanted a good way to stack rank resources for their annual review. Jira dashboards were the obvious choice. By dashboarding the number of tasks each person completed during the sprint, the manager could easily discover who the top developers were and who were candidates for “trimming the bottom of the bell curve”. This lightened the manager’s workload, focused the developers on increasing output, and helped the senior engineers by eliminating the needless distraction of helping others who were not as proficient.
Speed to Resolution
With the success of maximizing development output, how do we get the most work out of operations? It's very similar.
A friend explained to me how operations are measured in his organization. Individual metrics are tracked for how many tickets are closed and the average time required to close tickets. These individual metrics are tracked against the team’s average for the week. This allows the team manager to ensure everyone is pulling their weight and that the recurring requests are closed in a timely way. This made management in the area happy because they finally found a way to ensure the remote workforce was earning their pay.
Outcomes
While neither example above included a process to inspect outcomes and compare them to desired results, outcomes were observed.
Development Outcomes
- Staff Engineers focused on the tactical work of closing issues rather than the work of helping set technical direction, growing their replacements, looking for ways to improve overall operability and maintainability of the application, and ensuring general technical excellence on the team.
- Work in progress increased because reviewing someone else’s code didn’t help you make your numbers.
- Answering questions and helping others reflected negatively on your numbers.
Operations Outcomes
- The drive to close tickets disincentivized understanding and correcting root causes.
- Many common support requests for access or system configuration could have been automated and made self-service, but automating them would have taken time away from closing tickets.
- Tickets were closed without full resolutions. Customers could always open another ticket.
- Helping someone close a ticket had a negative impact on the person providing the help. Questions were discouraged.

What to Manage?
Individual metrics applied in a team context will destroy teamwork. If the goal is to make it easier to “find slackers” instead of improving the outcomes, individual metrics are one of the shortest paths to turning a team into just a group of individuals who share a common set of work. Alternately, placing metrics around business goals, value hypotheses, delivered quality, and improving the effectiveness and sustainability of value delivery will improve outcomes for everyone involved. Yes, many organizations have people who do not pull their weight. It’s cutting off your nose to spite your face to use metrics to try to find that. Instead, observe how the team works. Look for the leaders who are helping others. Look for the glue people who help everyone move in the same direction. Look for the idea people who are seeking better ways and helping the team run experiments. None of that can be measured except by what the team delivers. Focus on the outcomes.
For more pro tips on scaling DevOps, check out ScaledAgileDevOps.com
DORA Metrics Tips

Since Accelerate was published in 2018, “DORA metrics” have become increasingly popular for measuring IT performance. More vendors are creating dashboards or integrating these metrics into their existing pipeline tooling. However, the context is getting lost in the race to deliver these features to customers.
First, what are the DORA metrics?
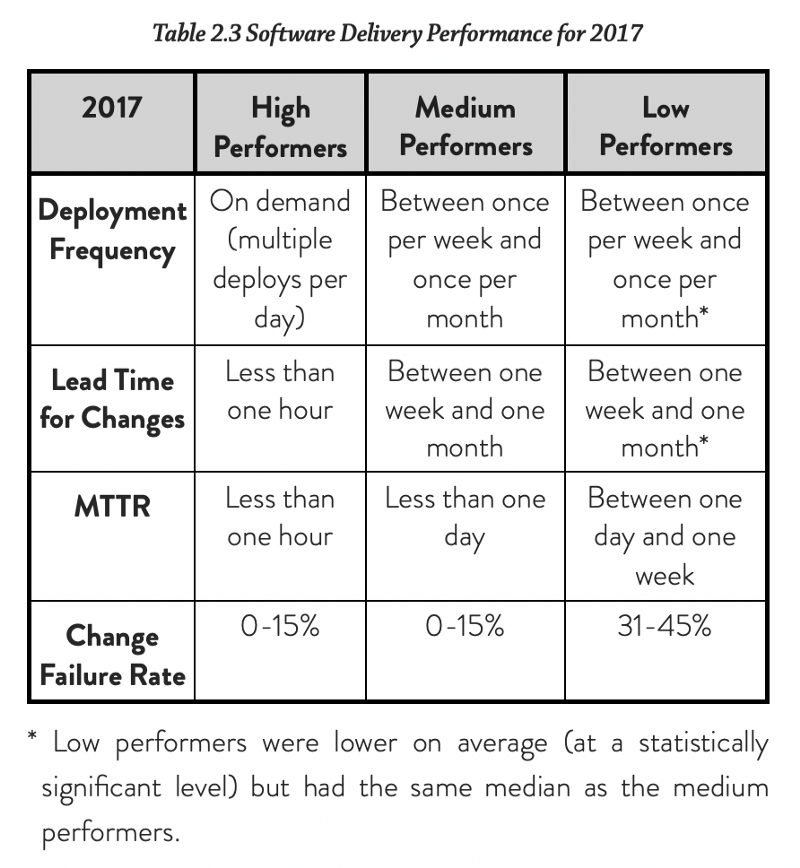 “Accelerate”
“Accelerate”
Nicole Forsgren PhD, Jez Humble & Gene Kim
In 2021 I wrote a paper for IT Revolution where I go into detail on how to misuse and abuse these. Today, let’s cover some high-level tips to consider before attempting to use these.
1. Don’t Use Them
More specifically, don’t naively use them without understanding what they represent and what they do not. Having good DORA metrics does not mean you are a high-performing organization. Delivering very stable, very small batches of useless crap doesn’t make you high performing. However, delivering large batches and/or having an unstable system will definitely cause a negative impact on your business performance. Do not use them to track positive performance. The correct way to use them is as an indicator for things that could be improved so you can investigate “what’ and “how”.
2. Understand the Definitions
I’ve reviewed many vendors’ implementations of DORA metrics and most of them use incorrect definitions.
Most tools define “Change Fail %” as the percentage of changes that cause an outage or otherwise need to be backed out. Nope. Read “Accelerate”.
“…result in degraded service or subsequently require remediation (e.g., lead to service impairment or outage, require a hotfix, a rollback, a fix-forward, or a patch).”
So, a change that results in a defect. Any defect.
Another that is almost always measured incorrectly is “lead time”. This is almost always measured from when the code is checked in until it is delivered, but that’s only the automated portion. In a follow-up response to a critical book review, Jez and Nicole state,
Measuring just the robot portion is much easier for most vendors to automate because it requires less tool integration. However, it tells you almost nothing about where improvement opportunities exist. Most of the issues are upstream of there. Measure the entire development flow.
There are more incorrect definitions that tools use. Read “Accelerate”, understand the intent, and don’t blindly trust the implementation of a tool.
3. Use All or None
“This quarter we’ll focus on improving delivery frequency. next quarter we’ll focus on the next metric.”
Rapid delivery without a disciplined quality process is just dangerous. Speed isn’t the goal. Increased quality feedback is the goal. We need signals for quality and batch size.
4. They are Lagging Indicators
While they can be leading indicators for IT performance, they are lagging indicators for engineering excellence and good product management. Measuring how frequently working code is integrated into the trunk and the wait times for handing off work will help identify things that will improve the DORA outcomes.
5. How to Improve?
The DORA metrics tell us that high-performing organizations focus on the delivery discipline of continuous delivery. Focus on “why can’t we deliver working software daily?” and fix those things.
A lot of context and subtlety are required to identify issues and improve outcomes. The best roadmap for this in Accelerate isn’t the metrics, it’s the list of 24 behaviors in Appendix A. Simply publishing DORA metrics is usually a destructive act. Use them as a tool to inform health, but only as part of a broader strategy that includes organization architecture improvement, mentoring teams, focusing on product management, better incentives, and everything else that is impacting value delivery.
SAFe Isn't

I frequently find myself in conversations about Scaled Agile Framework (SAFe) and its utility or lack thereof. My opinions are based on both direct experiences in an organization that started using it and from comparing notes with colleagues in other large organizations, including many who are SAFe certified. This is my attempt to explain why I hold the opinion I hold and to challenge SAFe apologists to stop hand waving the criticisms away.
Tl; dr: SAFe bad.
My experience with SAFe began after it was inflicted upon my organization as a method of scaling the pockets of agile experiments. The organization was a global enterprise with thousands of developers and multiple divisions and product lines. In an organization like this, moving from waterfall development (we even went through PMI training) to an agile workflow can be a challenge. At the time, I worked in an area that was organized in a way that should have been the sweet spot for SAFe. We had hundreds of developers on several project teams working as feature factories on a shared codebase. We had a large number of SAFe consultants working to “transform” our area as well as other areas of the enterprise.
After a couple of years, our outcomes still were not very agile. we had added several new jobs for ex-project managers to manage the layers of processes for coordinating teams. We also had the two standard SAFe cadences. Every team was required to execute Scrum with 2-week sprints. Every 10 weeks we had a 2-day meeting to plan the next “Production Increment”. There we would plan what features would be delivered in the next 10 weeks and when those features would be delivered. The latter was to ensure that the hard dependencies between teams would align to the right “Release Train.” On the surface, this might sound like success and I’m always curious when people claim they have successfully implemented SAFe if this is their definition of success. However, that outcome was a complete failure. Let’s look at why.
Fake Improvement

Management felt they had control over the situation and that things were less chaotic. There were 10 weeks of planned work aligned to deliver dependencies in a coordinated manner and 2-week sprints to track the planned against delivered. Project managers were replaced with “program managers” and “product owners” who still reported to the PMO. It also created the new “Release Train Engineer” role to coordinate the large, multi-team scheduled releases every 10 weeks. Establishing these cadences and these roles prevented any further improvement. Why?
First, the PI cadence gave the PMO what they felt comfortable with; “Agile Transformation” without the risk of disrupting project plans. However, five 2-week sprints with processes to align dependencies is just a waterfall Gantt chart. It fails for the same reason waterfall and all fake agile fail, it assumes things will turn out as planned. Product development is not deterministic and laying out a determinist plan is objectively the wrong path to delivering a successful product. Reality is far more complex and the smart assumption is that things will NOT turn out as planned because proper product development is hypothesis-driven. The outcome was that we still delivered late but now had more process overhead, more management layers, and more meetings. However, the PMO felt better.
Next, the “Release Train Engineers”. These were not engineers. They were responsible for holding teams accountable that all of the required hard dependencies aligned for the next “release train”. The fact that this coordination is needed is an architectural smell, not a feature. If we have hard dependencies between teams (more than one team must deploy at the same time) then those teams can only deliver at the speed of the slowest team. That’s not the worst problem. Operational stability is. No team can fix anything safely without validating with the other teams. During a production incident, this is a major problem. When we try to handle this with process, it hides the real problem and the problem never gets better. If your job is to manage this process, then you have no incentive to point out the problem. Trains are the least agile form of moving freight and are only used for very large batches. Large batches are the antithesis of the goal of product development. Software ain’t coal.
Things SAFe Apologists Say
“I’m sorry you had a bad experience. It sounds like SAFe wasn’t implemented properly in your organization.”
Given the number of people reporting bad outcomes, perhaps the SAFe certification process needs more rigor? Currently, it appears to be structured to generate certification income rather than industry improvement. The versioning scheme is brilliant. “Oh, you’re only SAFe 4.0? We are on 5.0 now! Make sure and pay to upgrade.” A friend told me that he got certified and then invited to spend ~$300 to renew his certification the following year. He declined.
“What you experienced was just ‘shu’, the learning stage. As your organization learns, you are expected to move on to ‘ha’ and then finally to ‘ri’ when you master it and stop using the framework when you find that the framework is too restrictive!”
Except that the starting point creates middle management jobs that aren’t needed when you get to the end and have loosely coupled product teams. Except that the goal is mastering the framework because that’s what people are rewarded for. Therefore, improvement will stagnate as soon as those jobs become entrenched because making things better eliminates the need for those jobs. The starting point also removes ownership from teams that you will find difficult to get back. Teams simply become “accountable.” This disengages motivation. It’s FAR more effective to show people where they are in relation to “good” and help them along the path than to spoon-feed “this is the next step”. The only people who benefit from hand-holding are the people paid to hold hands. We can skip to the end by relentlessly improving the actual problems that prevent us from getting to “good”.
“People bashing SAFe are just trying to get attention because it’s trendy to bash SAFe.”
There are more interesting things to talk about to get attention. ML is much more trendy. If you put your hand in a fire and get burned, is it attention-seeking to warn others so they don’t need to learn the lesson from direct experience? Using the experience of others is less painful. I personally push back on SAFe because of how long it delayed improvement in the organization I worked for and how fast we were able to improve business outcomes and team morale when we focused on solving the problems rather than applying a process framework to band-aid them.
“SAFe is like a recipe book. You just pick the recipes you need!”
SAFe is exactly like a recipe book that contains recipes for coq en vin, beef Wellington, tres leches cake, how to reconstitute powdered eggs for 2000 people, and the correct levels of arsenic to use to avoid killing someone instantly.
“There are some really good things in SAFe”
There sure are and I can point to the original sources for all of those good practices SAFe has cargo-culted. It’s entertaining to be part of driving a good practice and see SAFe adopt, brand, and sell it later. The “value add” that SAFe brings is mixing those good practices with a bunch of bad practices and charging people to get a badge for LinkedIn. It’s a minefield for people to navigate. If you already know how to cook well, then you don’t need the book. If you don’t, then you’ll serve reconstituted eggs with arsenic seasoning.
The goal of SAFe is SAFe, not better value delivery. You can tell by what metrics they value.
“Measuring Competency: Achieving business agility requires a significant degree of expertise across the Seven SAFe Core Competencies. While each competency can deliver value independently, they are also interdependent in that true business agility can be present only when the enterprise achieves a meaningful state of mastery of all. © Scaled Agile, Inc.”
Recovering
How did we fix this nightmare? Instead of calling in more consultants, the area SVP gave us (the senior engineers) a mission, “we need to go to production every 2 weeks instead of every quarter.” If something hurts, do it more often! He gave us free rein to solve the problem and air cover to clear roadblocks. Our solution? “We need to implement continuous delivery and we need to go to production daily.” We re-architected the teams into product teams to mirror the application architecture we wanted. We converted hard dependencies to soft dependencies with a loosely coupled architecture built by teams formed around business domains. We used modern technical practices to handle dependencies in code instead of managing them. Instead of PI planning, we talked to each other and used API contract-driven development. Teams were able to deploy independently in any sequence and deliver against the area roadmap. Over time, the RTEs had to find positions elsewhere. We didn’t need them. Teams chose the method of working that worked best for them and they owned the outcomes of their decisions. Most importantly, we were delivering multiple times per week with higher morale and ownership.
“Ah, but have you tried LeSS?! LeSS will fix it!”
SAFe is the framework I’m most familiar with but I’m highly skeptical of any framework. I’ve enough experience to know that there are no cookie-cutter solutions and that improving flow requires context. Agile scaling frameworks are unlikely to result in agility because they lack context. Focus on improving organization architecture, application architecture, and developer experience and understanding there is no such thing as deterministic product development. We are delivering experiments to verify a value hypothesis. We fail less if we do that faster and smaller. Scaling makes things bigger. Don’t scale. Descale and improve throughput and feedback.
Written on May 6, 2022 by Bryan Finster.
Originally published on Medium
Flying Cars are Boring

Continuous delivery can be a frustrating topic. Those of us who use this workflow will never go back to legacy ways of working. The lack of Fear Driven Development and objectively better results are amazing. We get so much joy from building things that deliver more value with less effort and less waste. On the flip side, those who haven’t worked that way rarely believe and cannot seem to imagine that pain reduction is possible. So instead of spending time on ways to make defect detection ever faster and to make pipelines even more secure, we spend time trying to convince people who are in pain about the basics to help them have less pain. It’s one of the reasons many of us are so passionate about MinimumCD.org as a method to help people get over the hump at the beginning. Yet, we still run into the same conversations ad nauseam
“CD won’t work here. Our developers aren’t skilled enough. CD is too dangerous. Our customers don’t need changes that often.”
All of those are false.
Imagine you have frequent conversations with people about flying cars with people who have never seen humans fly. You start every conversation with “flight is possible” and then spend the next month countering arguments about the hubris of Icarus and how dangerous it is to slip the surly bonds of earth. Now imagine you get the opportunity to visit a place where flying cars aren’t just common but are so ubiquitous and boring that no one talks about them. Then you come back and hear the same tired arguments again. This happened to me recently.
I’ve been an advocate of continuous delivery since my first experience on a team learning how to solve the problem of “why can’t we deliver today’s changes to production today?” Solving all of the related problems of shrinking the batch size of everything, testing better, working as a team better, and getting faster feedback from the end-user removes pain that I had always thought was just part of the job. In 2017, a teammate and I gave a talk at DevOps Enterprise Summit about the impact of CD on teams and said, “it made us love development again!” Since then, I’ve spoken with peers in other organizations who are trying to help roll out CD. The reality is that the vast majority of success stories are not widespread in their organizations. The changes required are mostly people-related and are far larger than rolling out new tools.
Recently, I visited a company with a reputation for modern development practices to learn how they work. For the first time, I was able to witness an example where reputation understated reality. Continuous delivery permeated every thought of everyone I spoke to whether discussing software or manufacturing. Spending time there was both exhilarating and a little frustrating. I kept thinking, “why is it so hard to convince everyone that this is obviously the best way to work?”
The best measure of delivery is outcomes. This company is the industry leader in its field. The problems they have been solving are nothing short of revolutionary. They are on the bleeding edge of what they do and continue to astonish people by delivering things many consider impossible. Their success is directly related to the same things I’ve always found to be important: mission, mindset, and execution.
Mission
If you ask anyone at the company, they will tell you the company’s long-term mission. The scope of that mission is breathtakingly aspirational. Everyone can tell you how their work contributes to the mission and how their team’s work contributes to the larger mission of the company. There is no separation between “business” and “IT” or “manufacturing” and “software”. There is one team, one mission.
Mindset
“We are all engineers solving hard problems.”
Sitting at the coffee bar, I could watch new hardware being built to my left using revolutionary manufacturing processes that enable rapid design change at scale. Operations on my right monitored delivered products and everyone could see the status of critical deliveries. If a new hardware design is sent to manufacturing, the engineers assemble the first examples themselves to ensure they are easy to assemble to prevent increasing the effort of manufacturing. Simplicity drives everything they do. One software engineer told me, “if you aren’t adding something back to the design, you haven’t removed enough yet.” Extreme Programming is corporate culture.
There was a passion for the work in everyone I talked to, hardware, software, and even the baristas at the coffee bar. This shared understanding gives everyone a North Star to compare to their daily work. Everyone has a say in the success of what they do and anyone at any level can “pull the andon” if they see something that appears unsafe. Mistakes could cost lives and everyone takes that seriously.
As I said, mistakes could cost lives. This is serious work they do and they want to be safe while also pushing the envelope. They do this with a CD mindset. One of the frequent arguments against continuous delivery is that it’s too risky. “If we deploy the wrong change to this device it could kill someone. We need to make sure it’s perfect first!” My experience has been that the more you strive for perfection on every delivery, the less perfect it will be. Larger changes are the result and large changes contain large defects. If we put processes in place to optimize for learning, rapid feedback, and automating checks for the things we learned then we are far more likely to find problems early and reduce risk. It also gives us the confidence to rapidly innovate rather than stagnate.
Execution
“Efficient and effective delivery to enable rapid improvement”
I’ve been watching this company for several years as they delivered hardware. I was very skeptical at first about what they claimed they would do. However, I’ve been astonished at the rapid improvements I’ve seen and recognized the workflow they were using. Usually, with complex hardware, there will be years of development time, an assembly line will be built, and then every delivery from the assembly line will be the same. What I’ve witnessed though is that they see every delivered unit as an opportunity to learn and improve. Each one is a prototype with a delivery goal as well as a learning goal. Once they have one feature working as intended, they immediately begin iterating on the next feature. This is how software should be delivered, but to see it done with hardware and at the scale they do it is astounding. Pulling back the covers reveals that the CD mindset permeates all the way to the design of their factory floors. They design everything for rapid change. They know that to meet their goals and to stay ahead of their competition they must continuously improve everything they do, and even their assembly line layout cannot be a constraint.
Naturally, this applies to their software as well. The refreshing thing for me was that continuous delivery isn’t something they talk about. It’s just the underlying assumption in everything. They know that operational stability depends on the ability to correct issues rapidly so they practice delivering constantly. In one example, they have several thousand devices deployed globally that require significant uptime. To ensure this, they update weekly and test in production. If a post-deploy test fails, the device self-heals by reverting the change without human intervention. They act just like well-engineered micro-services. One of the core behaviors of CD is trunk-based development. This branching pattern frequently receives pushback when we talk about it, but it is not possible to execute CD without it. One engineer told me that they do TBD but used to use release branches. They found this to be both process-heavy and error-prone. “We decided we needed to harden our CI process and release from the trunk.” They replaced process overhead with improved quality gates in their pipeline. This saved effort and reduced errors. Again, this isn’t for some tertiary system. This is the process for the core OS of their hardware.
There’s so much more that could be said, but all of it comes from an organization that has a deep understanding that when you are inventing a new solution, this is the best way to do that. Optimize everything for better communication, faster feedback, efficiency, and learning. They have repeatedly demonstrated with real-world outcomes that they are right.
They aren’t special. Nothing about what they are building makes this easier. What they have is a shared mission, a mindset driven by innovation and winning, and disciplined execution. It’s baked into the culture. Flying cars are real and boring there. No one talks about them. They just use them to beat everyone else in their business space.
Written on May 6, 2022 by Bryan Finster.
Originally published on Medium
Agile Deepities

A “deepity” is a statement that sounds profound but isn’t. “To the extent that it’s true, it doesn’t have to matter. To the extent that it has to matter, it isn’t true (if it actually means anything).” <See Deepity
“Agile is a culture!” and “Agile is a mindset!” are deepities. To the extent they are true, they tells us almost nothing useful or actionable. If we are trying to convince people that there are better ways of working, they are counterproductive because they cause frustration.
“Sure, but HOW do we improve? Tell me something I can use! What’s the process?”
“Agile isn’t a process!”
That flawed understanding of “Agile” is why some people claim that documentation and planning aren’t “Agile” either. That’s a good way to fail. “Process” is specifically called out as something that does exist in the Manifesto. It’s just less important than people working together. Let’s eliminate all processes and see how “Agile” we are. Hint: we aren’t.
“Process: a series of actions or steps taken in order to achieve a particular end.”
Is “Agile” the desired end? OMG, no! The desired end is the continuous delivery of value to the end-user.
What are the steps?
- We need to systematically tear down silos and organize communication paths to reduce information loss so that we can…
- Systematically reduce the cost of change so that we can…
- Systematically reduce changeset size so that we can…
- Get faster feedback on the quality of our ideas and adjust to deliver better outcomes.
- We need to use good development practices to reduce production waste.
- We need to use good marketing and user research practices to reduce bad or irrelevant ideas.
We don’t need an “Agile mindset.” We need a mindset of “deliver useful things to the end-user so they want to use our products. Do it at a total cost that allows us to do sustainably and do it better than the competition. If we don’t then we cease to have users.” We need a mindset of “what we are doing is probably wrong. How can we find out quickly and adjust?”
Improving the flow of product delivery isn’t a culture or a mindset. Culture is an outcome of how an organization works. “Mindset” is something people have. A toxic culture will not work as well as a generative culture, but it can still result in better outcomes than a generative culture with the wrong goals or wrong processes to achieve them.
We don’t convince decision-makers with “culture” and “mindset”. We convince design makers with better outcomes and then show industry data on how better processes encourage a culture where improvement can flourish so we can better meet our value delivery goals.
Written on May 3, 2022 by Bryan Finster.
Originally published on Medium
Business Value Isn't My Job

I was recently in a conversation on social media about the role of a software engineer.
As a SWE, what you bring to the table is knowledge of efficient algorithms and data structures for general computation. If a company needs domain expert they will hire one, this is typically a product owner or business analyst.
Oh, dear.
When I shared that experience, many other software engineers assumed the opinion came from a toxic manager who just wanted code monkeys to shut up and type. It didn’t. It came from another developer. They said that their talents were wasted on understanding the business problem and that if you were trying to be good at two things (computer science and the business domain) you probably weren’t as good a developer as you claimed. When questioned on this, they doubled down.
If the business tanks and you’ve fulfilled your role as efficiently as possible why would you care? The market is begging for good SWEs. If we continue to fill in the gaps in management we’re just being enablers. People need to fail to learn.
Perhaps “Ethics” would be a good addition to the CS core curriculum in universities.
As a software engineer, it’s not our job to drive business value. That’s why management and leadership are being paid and followed. Understanding the mechanics of development is why we study SWE and CS, it’s the entire value prop we bring to the table.
That may be all that you bring. You’ll not go far though and you’ll never work on my team.
Someone else responded,
“But what if some people could be good at two things at once? Seems like some companies might like to pay for that.”
Indeed they would. The only exception I’d take is that it’s not “being good at two things at once.” It’s being good at one thing, software engineering.
It’s time for real talk
If I am a carpenter, I need to know how to use my tools. I need to know how to execute joints that are tight, but not too tight. I need to understand how wood reacts to environmental changes and how to allow for those changes. I also need to understand what I’m building, why I’m building it, and what the goals of that structure are.
I recently had a deck built. The team of two that built it were professionals, not “hammer monkeys.” They didn’t require constant direction from the owner. Not only were their results well-executed, but they knew how to communicate to the customer (me). They understood how to address unexpected challenges that come with modifying an existing house and how to communicate bad news when it was discovered. They knew how to suggest changes that would both be better for the structure and for the final usability of the deck. It is not “trying to be good at two things” to also understand how to read plans, spot mistakes, and correct the mistakes. It’s not “trying to be good at two things” to understand how to communicate and get feedback from the end-user. It’s not “trying to be good at two things” to suggest design improvements. It. Is. The Job.
After sharing this experience, I heard from senior engineers, engineering managers, CTOs, and CEOs about the difficulty they are having hiring competent engineers who want to learn about their business so they can effectively solve problems.
I work as a senior software engineer solving the business problems and one of the problems we have is that too many coders expect to get exactly defined programming work somebody else prioritizes and defines.
I even had some executives offering me a job.
This is a sorry reflection on the state of our profession. We need to do better.
Be a professional
Professional software engineers take a broader view than computer science. We aren’t in academia and this isn’t a hobby. We need to deliver business results. The Apollo flight computer wasn’t programmed by mere coders. Software engineers did that. They understood the problem they were solving. Eagle only landed due to resiliency features the development team added because they understood the problems. No one specified those.
If you accept a job to help a company meet its goals, the ethical position to take is to fulfill your side of that agreement. Taking their money to play, build your resume, or deflect work is unethical. The code is a small fraction of your job. Learn the rest of it or go back to coding as a hobby and pay the bills flipping burgers. You’ll be more valuable to the team that way.
IMO if you’re worried about business value you’re not only devaluing the product team but also making inefficient use of your own experience and education.
Just wow! We are the product team. Level up.
How did we get here?
Mismanagement and bad incentives. Developer interviews vary wildly. I’ve sat in and performed interviews for senior engineers. Strangely, we never talked about how to reverse a binary tree. The conversations were entirely around solving real problems. However, many companies use things like LeetCode problems for interviews. I can only assume they lack any competent software engineers or are too lazy to do actual assessments. The result is they optimize for hiring people who can memorize solutions to kata and annoy people who can solve the problems they actually have. They work hard to attract people who lack the ability or desire to understand the real problems. Then they complain.
It’s time for engineering management to level up too. If you don’t understand product development, how are you competent to make hiring decisions?
Why do I care?
I mean, the more half-trained, lazy, and unethical developers there are in the market, the less competition there is for real professionals, right? No. There are many of us out there fighting to improve our industry and the lives of our colleagues. We are tired of poor quality. We are tired of developers being treated like fungible assets that are as replaceable as LEGOs. Those two problems are tightly coupled. We want everyone, developers, end-users, and everyone else in the value stream to live better lives with better outcomes. We want to work on teams of professionals because it’s just more fun to deliver things that help real people.
I’m not a stonemason. I build cathedrals. I have stories about how things I’ve worked on have not just helped but have transformed people’s lives and the lives of their families. I cannot imagine anything more rewarding. If you are reading this and also internally screaming, let’s all push to fix this. If you think I’m being unreasonable, I think Wendy’s is hiring.
Written on April 12, 2022 by Bryan Finster.
Originally published on Medium
2021
2022 Reading List

I’m frequently asked what resources I’ve found most useful on my learning journey. Here are my recommendations for both technical and non-technical people who want to improve organizational outcomes. These are in no particular order.
Engineering the Digital Transformation: (Everyone) The hardest part of organizational improvement is getting alignment on goals. Gary Gruver’s book and related training are excellent for this. Gary has a no-nonsense style of communicating how to improve the flow delivery and relentlessly improve quality processes in multiple contexts. He manages to do this in ways that everyone, no matter how technical, can understand. This is critical for establishing a baseline understanding so everyone can work towards common goals.
Modern Software Engineering: (Developers) From Dave Farley, one of the authors of Continuous Delivery, comes a concise guide to what it means to be a modern software engineer and how to approach the work with a real scientific and professional mindset. This book is the book I’ve needed for years. Not only does it have some really useful information on how to design systems that are optimized for testability and feedback, but it also focuses on the mindset required to really deliver valuable solutions. It should be required reading for everyone aspiring to call themselves a Software Engineer.
Continuous Delivery on YouTube: (Developers) Just put this on auto-play while you’re working. So much good information for free covering every topic related to development.
Sooner, Safer, Happier: (Leadership) Jonathan Smart points out the patterns and anti-patterns for organizational improvement. With decades of personal experience with success and failure, Jon knows what he’s talking about. This should be required reading for anyone wanting to improve their organization.
Making Work Visible: (Everyone) Dominica DeGrandis explains how to optimize workflow for both yourself and your team. She explains the power of limiting work in progress to drive things to completion. Do you feel overwhelmed, overloaded with work, and yet nothing is really getting done? Read Dominica’s book. More “no” and less WIP!
Team Topologies: (Everyone) In 1967 Melvin Conway stated “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” In Team Topologies, Matt Skelton and Manuel Pais show useful patterns for organizing teams efficiently to improve the flow of information and delivery. I was reading their blog before the book came out and was very excited to meet them at the book signing to thank them for all of their work. This is a must-read before planning your next reorg.
Implementing Domain-Driven Design: (Everyone) Don’t build a single microservice or plan any large organization or architectural refactoring without reading Vern Vaugn’s book. This not only covers tactical, code-level DDD but also discusses the broader strategic organizational implications and design patterns.
Software Engineering at Google: (Everyone) Tones of lessons learned by Google on what works and doesn’t work when delivering value. This is a big, dense book and the valuable insights start immediately.
What books have you found most useful on your journey?
Written on December 30, 2021 by Bryan Finster.
Originally published on Medium
What is a Production Issue?

Continuous Delivery requires an entirely different mindset from classical artisanal delivery. For example, we always prioritize operations over development. If we cannot deploy something to our production environment, then nothing else matters. Therefore, the first feature to deliver is the ability to deploy to production. We deploy a Minimum Viable Deployable “hello world” UI or service to validate we can. Then we keep adding small changes very frequently to keep validating we can and to get operational feedback on those changes.
Another mindset shift is the definition of “Production”. Our primary product on a product team should always be the pipeline. It needs to always be green and it needs to have all of the quality and compliance gates coded into it to ensure our confidence to release. Only the pipeline defines releasable. If we are not releasable, our highest priority is to become so. The implications of this are incredibly important for teams who supply products and services to product teams to understand.

All of the following should be P1 issues from the perspective of platform teams:
- The product teams cannot deploy to production due to a production outage.
- The product teams cannot deploy to production due to instability in the testing/staging environments we manage.
- The product teams cannot deploy to production because our security tool is generating false positives.
- The product teams cannot deploy to production because our CI tool is unstable.
- I cannot deploy to production because my laptop is broken.
All of these are “production impacting issues” because if any of them are true then we cannot safely FIX production when something breaks. We do not downgrade an issue because “that’s only an issue in Staging.” We only downgrade issues that don’t prevent production delivery.
Written on November 1, 2021 by Bryan Finster.
Originally published on Medium
Upgrading the Agile Manifesto

When starting on the journey to agility, the most common path is for an organization to hire a Certified Agile Consultant™ and learn about the Manifesto for Agile Software Development followed by Scrum. Then they spend time catching up to the present 20+ years of learning and hopefully learn that delivery and not the process is the point. Why must everyone start at the beginning? The Manifesto was written over 20 years ago. Some principles have not aged well and most Scrum training reinforces the principles that need upgrading. For example, “we deliver every 2–4 weeks” continues to be a constraint on a majority of teams.
Today, we know that the continuous delivery of value yields better results. We have the ability to get feedback on the quality of our ideas much sooner with less risk and less drama when we learn to solve the problems of “why can’t we deliver value today?”
I Propose a Pull Request…
Code review comments for this post
The Preamble
We are uncovering better ways of developing software by doing it and helping others do it.
Since this was written, we have uncovered practices that are better in every context. Continuous Delivery is one of those practices. We should focus on getting better at that.
We are uncovering better ways of continuously delivering value to the end-user and helping others do it.
1st Principle
Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
If we just reflect on the implications of this, we mostly only need this principle.
2nd Principle
Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
Let’s be more explicit.
Incorrect, misunderstood, or changing requirements are the expectation. We embrace this to design a system of delivery to improve the customer’s competitive advantage.
3rd Principle
Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
This one has aged very poorly. In modern development, we now have the ability to actually achieve the 1st principle by…
Continuously deliver working software, from a couple of hours to a couple of days, with a preference to the shorter timescale.
4th Principle
Business people and developers must work together daily throughout the project.
Projects are not something we should do.
Business people and developers are one product team with birth to death ownership of the outcomes.
5th Principle
Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
I’m never motivated by a project. I like to see and improve my outcomes. I may be motivated to begin working on a product, but if I find myself in an environment of blame, death marches, lack of user feedback, etc. I will become demotivated. Now, if you ask me to help solve real problems and provide continuous delivery of valuable solutions…
Build product teams with understanding and ownership of the mission, ownership of the solutions, and responsibility for the outcomes in an environment that attracts, grows and retains motivated people.
7th Principle
Working software is the primary measure of progress.
Well, nearly…
How often do you find that “working software” is interpreted as “meets the required spec?” Our goal is valuable solutions to business problems.
Valuable outcomes are the measure of progress.
11th Principle
The best architectures, requirements, and designs emerge from self-organizing teams.
This one is often misunderstood. It needs clarification.
The best architectures, requirements, and designs emerge from product teams who have ownership of the problem to be solved, ownership of how to solve it, and responsibility for the outcomes.
12th Principle
At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
I frequently see retros every six months. How can we be more explicit? Why shouldn’t improvement be part of daily work?
The team continuously reflects on things that casue pain, reduce morale, and increase delivery drag on the team, then tunes and adjusts its behavior accordingly using data to validate the changes.
Duena’s 14th Principle
My friend Duena Blomstrom’s response to this post proposes another principle. What we do is mostly about people, not technology. To be effective, we need as many ideas as possible from everyone on the team. Let’s make that policy explicit.
To be sustainable, happy and high-performing, we are to put the human work and psychological safety of the team, first.
Where can I send my PR?
Written on October 17, 2021 by Bryan Finster.
Originally published on Medium
That's Not Continuous Delivery

Continuous delivery is a powerful tool for delivering changes safely, reliably, and more frequently with less toil and burnout. CD is also the best tool for uncovering why we can’t do these. However, this is only true if we are really using CD.
CD Improves Everything
In 2017, the authors of Accelerate stated, “Continuous delivery improves both delivery performance and quality, and also helps improve culture and reduce burnout and deployment pain.”
Many of us have found this to be true. However, achieving these outcomes means really understanding what a CD workflow is. We get some tips from the authors of the book Continuous Delivery who stated these principles:
- Build quality in
- Work in small batches
- Computers perform repetitive tasks, people solve problems
- Relentlessly pursue continuous improvement
- Everyone is responsible
They do an excellent job in their book at explaining the anatomy of a pipeline, how testing should work, and many other important patterns. In 2021 one of the authors, Dave Farley, released a companion book Continuous Delivery Pipelines where he describes patterns for multiple contexts. The problem is that people don’t read books.
Fake CD

Fake CD occurs when an organization declares victory by stating “we are doing continuous delivery!” while implementing one or more anti-patterns. This isn’t to say that teams who are working to solve the problems and haven’t reached the minimum definition are doing “fake CD.” They just haven’t gotten there yet. CD is an engineering discipline, not only a set of principles. It is a set of objective practices that enable us to safely release working solutions on-demand without drama. I’ve frequently seen organizations claim to be “doing CD” because they have an automated deployment process. CD isn’t Jenkins, CircleCI, or any other tool. It’s how we use those tools. Recently I’ve had conversations where they were claiming to use CD and no amount of explaining would change their minds.
In one instance they delivered monthly.
“The definition of CD is we can release on demand and our demand is monthly.”
No, one of the practices of CD is that we are always releasable so that we can release on demand. This isn’t about scheduled delivery. We need to accommodate unscheduled delivery in an emergency and do it safely. When challenged to pick up a copy of Continuous Delivery, they scoffed at the idea.
In another instance, they were using a hotfix process. A hotfix process is where we use an exception process to deliver change in an emergency because our normal process is too slow. This generally means skipping quality gates when there is already a dumpster fire. The practices of CD act as a forcing function to improve those gates.
“We are on the path of improvement and that’s CD!”
No, delivering on-demand without doing it safely is not CD.
We Built Yardstick

Using bad definitions of CD harms outcomes, causes organizations to set incorrect goals, and harms continuous delivery as a brand. “Oh, we tried CD but it’s was just too risky.” They did it wrong. Several of us a the 2021 DevOps Enterprise Summit decided we needed to do something to help people aim for the right target. We spent many hours hashing out answers to a question, “what are the absolute minimum practices that apply to every delivery context that define continuous delivery.” To see the benefits of CD, this minimum set of practices must be adhered to. We published the MVP for CD, MinimumCD.org, at the end of the conference. Within days we had a number of people signing on to our effort including the co-author of Continuous Delivery, Dave Farley.
We agree this is the yardstick. “You must be this tall to claim CD.” This isn’t gating or elitism. We know that doing these things improves organizational outcomes and the lives of teams. We know doing less than this will not deliver those outcomes. This is the minimum threshold. Take a look. We welcome contributions. If you agree, submit a PR and add your signature.
Written on October 17, 2021 by Bryan Finster.
Originally published on Medium
Agile Rehab

I’ve been a developer for a while. I’ve delivered using every industry fad that management has bought into. In 2003, the organization I worked for wanted to bring some discipline to our ad hoc processes so they sent senior developers and team managers to PMI training to become certified project managers. We implemented a disciplined SDLC with process gates, learned to calculate the critical path on a Gantt chart, and spent a lot of time pretending that product development was deterministic over large timescales and feature sets. This failed, just as it almost always does.
Later, new management wanted to adopt agile development practices to improve things. Everyone went to the two-day Agile training, tried to translate these new terms to SDLC processes, and learned to create two-week project plans. Water-scrum-fall. This was more effective for finding out when we were trending late but didn’t really improve delivery. We still delivered changes every quarter, it’s just that all of the terms changed and we were “Agile”. In fact, we had Agile Maturity Scores™ to show exactly how agile we were.
Eventually, we had a real, objective goal. We needed to deliver at least bi-weekly instead of quarterly. We needed to solve all of the technical and process problems required for continuous delivery (CD). Our original goal was bi-weekly, but we decided that daily or more was a better goal. There were many good reasons for this, but the most important was that when there is an impacting incident with a direct downtime cost of thousands of dollars a minute and an indirect cost of far more than that, we need to have the ability and confidence to fix things quickly without making things worse. CD enables this if teams practice delivering very frequently. As we dug into CD, we quickly discovered we knew all the Agile terms and ceremonies, but we had no idea how to be agile. We had to fix that to deliver daily. If you are struggling with “Agile”, I hope our learnings help.
Use the Right Definition for “Agile”
There are two common definitions for “agile”:
**ag-ile (adjective):**Able to change directions quickly and easily. Nimble.
This “agile” is an outcome of having the ability to adjust priorities and improve outcomes based on the feedback from the end-user.
**Ag-ile (proper noun):**A product marketed by Agile Industrial Complex certified consultants to pay for their boats.

This “Agile” is focused on selling cookie-cutter solutions and “Agile Transformation”.
The difference between the noun and the adjective is that the adjective is focused on delivery and feedback. The noun is focused on standardized processes, typically by claiming we all need to do Scrum and get better Agile Maturity™ Scores. Nouns and cookie-cutter solutions are easier to sell and implement than results.

I’ve had so many conversations where someone says, “but the Scrum Guide says…” I had one person tell me that using a “definition of ready” before beginning work wasn’t valid because it wasn’t in the Scrum Guide. OK. So? DoR is a good thing. The Scrum Guide also says both that it’s incomplete and that if you aren’t doing everything in it then you aren’t doing Scrum. Our goal isn’t Scrum and the Scrum Guide isn’t the law of agile software development. It’s the opinion of one group of people and..

Stop Using Maturity Models
Maturity models are bunk. They are a list of things someone else developed for their context. Yes, many of these have good ideas in them. Harvest the good ideas. However, no customer cares about our “maturity score” and we aren’t ever “mature”. Instead, we measure indicators for the continuous delivery of value to the end-user.
Have an Agile Mindset

What is the real problem we are trying to solve? Development is complex. It is not merely an assembly line process where we know the end state before we begin. We are doing product development. Every release is a prototype that we hope meets the needs. The reality of software development is that one or more of the following is true:
- The requirements are wrong
- We’ve misunderstood the requirements
- The need will change before we deliver
We are always talking about the “agile mindset”, but what is that really?
“We are probably wrong. We need to optimize our processes for being minimally wrong so we can quickly adjust to become less wrong.”
What we are doing is establishing a pattern of delivery that mitigates this reality. Real agility is using the scientific method to verify or falsify our value hypothesis. We need to deliver very small batches of work very frequently to get rapid feedback from users so we can adjust. We need to reduce the cost of change and improve our quality processes to support our ability to do that.
For Agility, Think Smaller

Start with a simple question, “why can’t we deliver working changes today?” Continuous delivery is the tool for uncovering and fixing the impediments to agility. There will be technical and process challenges to solve. How do we automate CI and delivery while remaining secure, compliant, stable, available, and delivering useful features? How do we make code changes that are evolutionary so we do not need to branch and wait for features to be complete before delivering? How do we break down work so we can deliver working features in less than 2 days? How do we get better information? How do we work as a team better?
As the problems are tackled, we’ll find that many of the things taught in Agile training are useful. Others don’t add value to us. We want the minimum viable process to enable the continuous delivery of value and we want to engineer solutions to keep the process overhead low.
Don’t Keep Starting Over with the Manifesto
The Manifesto for Agile Software Development begins with “We are uncovering better ways of developing software by doing it and helping others do it.” That was written over two decades ago. There is much good there, but many things have been proven since then and do not need to be uncovered. CD is one of those things. If you are trying to become agile, don’t start with the Manifesto. Don’t start with Scrum. Don’t try to follow the rules, because there are none. Focus on the continuous delivery of value to the end-user and ask “why can’t we deliver today?” Use the principles and practices of continuous delivery to uncover waste and pain. Relentlessly improve to remove them. Your customers will be happier. So will the teams.
Written on September 26, 2021 by Bryan Finster.
Originally published on Medium
Development Pattern TLAs

There are many common three-letter acronyms (TLAs) used in the software industry; TDD (Test Driven Development), BDD (Behavior Driven Development), DDD (Domain Driven Design), etc. However, there are a few lesser-known TLAs we should be aware of.

JDD
Jenga Driven Development is the haphazard approach to building systems where no thought is given to sustainable delivery. Eventually, the system becomes so fragile that it’s too dangerous to change. At that point we knock over the tower, “modernize the tech stack”, and hope we get different outcomes.
Credit to Antonio Cangiano for this gem.

RDD
Resume Driven Development is the approach used when the primary goal is to expand the technologies we can claim to have used rather than delivering value. The indication for this is tech stack and architectural complexity.
“What language are you using?”
“With our event-driven, micro-service architecture we aren’t constrained to a single language like less evolved teams. We use C#, Golang, Node, Python, Clojure, and Haskell. Our UI framework allows us to use Angular, React, and Vue. We like the flexibility.”
“Wow! That’s impressive! What does your product do?”
“It’s a recipe organizer.”

CDD
Conference Driven Development is what happens when we (or executives) get excited about the shiny new things seen at the last conference. The outcome of this is that we stop everything we are doing to re-architect our system, move everything to the cloud, rewrite everything using Qlang, or chase any other process/technology shown on stage to replicate their outcomes without regard to our own context or all of the problems the presenters didn’t talk about in 30 minutes of marketing.

PDD
Process Driven Development is when “how” we work is more important than the outcomes. An example of this is any “Agile Framework™” that includes metrics for how well the framework is being executed.

DDD
Deadline Driven Design. Related to JDD, but implemented much more rapidly. Deadline Driven Design is what occurs when we pull out all the stops to have teams meet a fixed (or expanding) scope and date project and pressure them to ignore things like testing, feedback loops, and basic design practices so we can “make the date”. We declare success on delivery and hope we can get a promotion before anyone notices the outcomes. This always ends in tears and often for many years afterward, but only for the teams. Anyone who can get another job will.

GDD
Grenade Driven Development is the pattern we use when we want to ensure we distribute responsibility as widely as possible by creating functional silos.
Requirements are written and lobbed at development. Coding is completed and lobbed at QA. Testing is completed and lobbed at Ops. Finally, the grenade blows up in the face of the end-user and everyone points at everyone else. Success!
FDD
Factory Driven Development is the process where we send requirements to a feature factory coding mill and expect them to be implemented quickly and without question. Programming is just glorified typing, after all.
“Stay in your lane, Code Monkey.”

MDD
Management Driven Design is when we architect our system around the desired management reporting structure. Our system will have no clear domain boundaries and any change will require a lot of multi-team coordination, but at least we made HR’s job easier. Conway be damned.

BDD
Bourbon Driven Development is the process we can use when our quality gates are so robust that we can confidently code while enjoying a nice, aged Kentucky bourbon neat. This should always be the goal.
Written on September 10, 2021 by Bryan Finster.
Originally published on Medium
Choosing the Right Tools

Whenever we want to solve a problem or build something useful, we have decisions to make about the tools we choose. Choosing the right tools requires a good understanding of the problems. Often though, there is a tendency to jump to familiar tools regardless of the problem. “I love the balance of this hammer. It just works well.” The hammer is probably awesome and it may have been used successfully to drive screws for years, but what if we stood back and reflected on why we are choosing a hammer to drive screws?
In 2007, Dave Snowden published “A Leader’s Framework for Decision Making” in the Harvard Business Review. In that article, he introduced the Cynefin framework (**ku-nev-in).**Cynefin is a way to categorize the kind of problem we have so we can apply the right tools. Briefly, there are four kinds of problems.
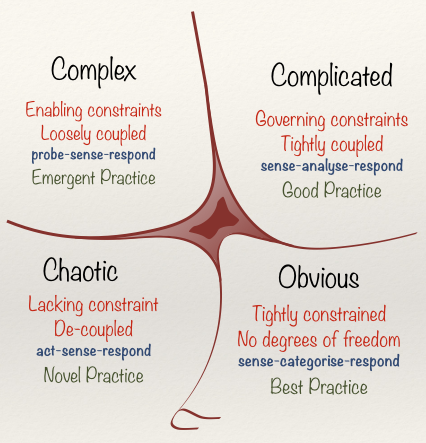
You start by approaching each problem, categorizing the problem, and then applying the right tools to solve it. For example, tying your shoes seems like an obvious problem that requires best practices.
However, when we review the multiple contexts for tying shoes, for everything from dress shoes to hiking boots, it becomes clear that it is contextual, complicated. We need to use good practices.
In software delivery, applying the wrong mental model for the problem space is very common and negatively impacts outcomes throughout the value stream. An example of this is building an effective quality process where using the wrong mental model for software quality causes us to verify the wrong way.
Is Development Complicated?
It is common to categorize software development as “complicated” because we write code that implements the requirements. We can then verify quality by testing that the code matches the requirements. Using this mental model, the rational thing to do is to create a QA department to verify that the development teams are implementing the specifications correctly. We want to deliver relatively small batches to the QA team, but we do not want to deliver to the end-user until QA has ensured quality. This is using the tools from assembly line manufacturing where quality can be easily verified.
Let’s build a car. We establish an assembly line and begin construction. As individual parts are built, they are tested for adherence to spec using test fixtures and then assembled into larger units where other test fixtures run additional tests on the integrated components. Finally, the car is driven to make sure it all works together. So far, we have a model that resembles unit, integration, and end-to-end testing patterns. However, we’ve made a huge mistake. No one wants to buy our car.
We’ve built the wrong thing using the best quality practices we know, and yet it is still poor quality because it doesn’t fit the need.
This happens all of the time in software development because we over-simplify the problem at hand. We are not assembling and delivering code. It only appears that way on the surface. In Cynefin, if you over-simplify the problem, you will fall into the chaotic problem space and will need to react to recover. This feels very familiar.
Development is Complex
What is the right mental model? Using our car example, we skipped right past the most critical part, “what should we build? How should we build it?” The analogy of development as an assembly line is almost entirely wrong. If we have automated build and deploy systems, those are our assembly lines. They have automated the complicated good practices and obvious best practices. However, everything that happens before we submit code to our assembly line is complex and emergent. The correct analogy is the design studio.

We are not assembling a car from specs. We are developing a new car, getting feedback as we go, iterating towards the specifications we want to build, and designing the most efficient way to build it. We are making decisions about components. Do we need to design new brakes? Can we use off-the-shelf Brembos? What interface changes do we need to make to use those brakes on our new prototype? Etc.
In manufacturing, it is very expensive to change these decisions before we construct our assembly line. So, design precedes construction, we lock in as many decisions as we can after extensive research, and we hope we’ve developed a car people want.
In software, the economic forces are entirely different. The most expensive part isn’t building and running the assembly line. In fact, creating the build and deploy automation is the cheapest thing we do. The cost comes from the R&D work of deciding how to solve the problem and writing code to see if it solves it. To mitigate that cost, we need to design a series of feedback loops to answer several quality questions: is it stable, performant, secure, and fit for purpose?
We can build a quality process that can verify stability, performance, and security before we deliver anything. However, “fit for purpose” is subjective. For that, we need to build a quality process that continuously verifies that with users. We need to do this by delivering the smallest changes we can verify to reduce the cost of being wrong. We need to understand that we are not assembling identical cars. Every single delivery from our assembly line is a prototype that is different from the one before. We cannot use static test fixtures built by another team. In fact, that’s destructive to our quality process because waiting for someone else to build the fixtures means we will build bigger things to test and drive up the cost of being wrong. Our test fixtures can only verify that we are building what we think is needed. We must constantly adjust them as our understanding changes. We are prototyping fixtures and building things to fit the fixtures so that if it is fit for purpose we can replicate success.
Focusing on continuous integration and delivery can make us more efficient at delivering small batches of work. Designing our quality process to optimize for user feedback from ever smaller batches of work will make us more effective at delivering the right thing. To do this well, we need to stop over-simplifying what we do. Software development is complex and if we apply the wrong tools to this problem space…

we will fall into chaos.
Written on August 20, 2021 by Bryan Finster.
Originally published on Medium
Constructive Pessimism

Hope creep is the plague of value delivery. We assume that since something worked in the past it will work again. We forget how much pain we’ve had in the past. “How hard can it be to build that? Looks pretty simple to me!” This is a big-bang, waterfall delivery mindset. We need a mindset that embraces reality. We need to internalize that everything is probably wrong and broken so we can prioritize our actions correctly.
There are many technical and process practices required for executing continuous delivery. It’s not easy, some are counterintuitive, and it requires a high degree of team and organization discipline. However, the rewards for doing it for the customers, the organization, and the individual developers are so great that baffles me that it’s not the standard industry practice. It does require that we modify our priorities though.
Priority 0: Can we get to production or, minimally, a production-like environment? This is feature 0 and should block all other feature work. Nothing we do matters if we can’t deliver.
Priority 1: KEEP THE PIPELINE GREEN! If anything blocks delivery, stop and fix it.
The Reality of Development
I’ve recently joined an organization where security is taken far more seriously than most organizations. Delivery pipelines are secure as we know how to make them and known attack vectors that can be detected with the pipeline will block builds. My first task is to deliver delivery pipeline observability to help any team using our tools find and resolve constraints in the flow of value delivery. This is one of my passions and there aren’t very many options available in the industry today for solving this problem, so it’s very cool.
We are building the application using React and other standard tools because we want to stay as close as we can to patterns we know will pass the pipeline security gates. As an advocate and mentor on CD practices, the first task we needed to accomplish was to deliver the pipeline. Should be simple
npx create-react-app <dashboard-name>
60 seconds later we have something we can build on!

For any new application, feature 0 is “can we deploy the application?” So, now we just need to deploy this to meet that requirement so we can start on feature 1. How hard could it be?
Going through the internal CD platform documentation to deploy a React application yields some simple configurations that are required. So, armed with confidence, I trigger the pipeline and await success. When I go to the newly deployed site, nothing is there. Blank page. But it worked on my desktop? No errors? WTF? Pulling the logs shows Content Security Policy violations. Going back through the docs shows I missed a step. To avoid CSP issues, React needs the INLINE_RUNTIME_CHUNK environment variable set to false. Doing that and rerunning the pipeline resolves the issue and we are off to the races.
We start working on the first story. We need a header, a collapsable navigation menu and to display something the first route. We mob the requirements and a few hours later we are looking good!

This is going to be easy! We have a few things to clean up. We refactor some tests and refactor some code. We only need to deploy the newest change and send it out for people to give feedback. We believe in rapid feedback, so we aren’t going to wait for “done” to show this off.!
After triggering the deployment, all of the tests pass. there is no indication anywhere that we have a problem. However, what appears in production is…

And the hair rending that is software development begins again. Inspecting the logs shows dozens of “Refused to apply inline style because it violates the following Content Security Policy…” errors
We’ve run afoul of CSP again after adding MaterialUI. We have a backlog of critical features that we need to deliver quickly. However, it doesn’t matter. We cannot deliver. Our highest priority is solving the reason we cannot deliver. We begin mobbing the issue…
It Could Be Worse
Imagine for a second we executed the way a majority of teams do.
“Pipelines are for delivery. We aren’t ready for delivery until we get signoff on v1.0 so that’s not the priority. When we finish all of the work we need to do for the first version, then we’ll focus on how to deliver. I mean, it works on our desktops so it’s probably fine. We hope we can deliver! We hope our technical decision will work in our environment! We hope it’s what the end-user actually needs!”
I’ll never again work on a team that works that way. Some people reading this are still working this way. I have empathy for you, but no sympathy. We don’t need to work this way anymore. We shouldn’t pretend we can deliver on time if we don’t know we can deliver at all. We need confidence. We need to assume things are broken until we can prove they are not. We need to assume that the ideas or requirements we have for features are wrong until we prove they are not. Building features on hopes and dreams of delivery and correctness is just a waste of time.
Ship first, verify, and keep shipping as fast as possible to keep confidence high that you can deliver and are delivering the right thing. Be pessimistic. Don’t give in to hope.
Written on April 30, 2021 by Bryan Finster.
Originally published on Medium
The Metrics are Lying

I was talking to a friend the other day about how her management is tracking teams’ “maturity” using “DORA Metrics”, the four measures the correlate with high-performing organizations mentioned by DevOps Research and Assessment in “Accelerate” and the State of DevOps reports.
- Pipeline cycle time (Hard lead time in the book): The time between when a change is committed to version control and when the change delivers to production.
- Delivery frequency: How frequently changes are made to production.
- Change fail %: The percentage of changes that require remediation.
- Mean time to repair (MTTR): The average time required to restore service.
These are becoming very popular in the industry and for good reason; they are good indicators for the health of a delivery process. High-performing teams can deliver changes daily with pipeline cycle times of less than an hour. They have an MTTR measured in minutes and less than 15% of their changes require remediation. So, all we need to do is tell all teams that their goal is to achieve these metrics and evaluate the teams’ “maturity” using these metrics?
We’ve just created another scaling framework silver bullet. Silver bullets have one use case.

Since we are not hunting werewolves on the moors, we need to find tools to solve the problems we have. The trouble is that people hear about the “DORA metrics” and how they correlate to high-performing teams and stop there. Correlation is not causation. Excluding acknowledgments and the index, Accelerate is 229 pages. The metrics are in a table on page 19. Imagine what other useful information the other 228 pages might contain.
Why do high-performing teams have these results?
Ownership
They care about what they are doing, they understand the problem they are trying to solve, they make decisions about how to solve it, they have responsibility for the business outcomes of their decisions, and they have pride in the results.
Practices
They execute a continuous integration development flow with tiny, production-ready changes integrating to the trunk very frequently (no, more frequently than that). When things break in production, they harden their delivery process. When the delivery process takes too long, they make it more efficient.
Organization
They exist in an organization that is optimized for the flow of communication, not for internal kingdoms. Budgets are planned for product lifecycles and value delivery, not annually planned buckets with a “use it or lose it” structure that is optimized to make life easy for accountants.
Culture
Their organization focuses on learning from success and failure. Sharing learning from both is seen as a priority. Why did it succeed? Why did it fail? People are encouraged to speak up when they have an idea, when they think an idea needs improvement, or when they know something is broken.
So, do we throw away the DORA metrics? No, they help us keep an eye on the health of the system. However, they are trailing indicators for poor health, not indicators everything is going well. That’s why “Accelerate” mentions several leading indicators as well (I won’t spoil it for you). We can push teams to improve those metrics and can even get short-term wins that will get people promoted. However, if we are not tracking leading indicators for efficiency and team morale, organizing for the flow of value, and fostering the right organizational culture, then those gains will be lost sooner than later.
Improving outcomes is hard. Read the rest of the book… twice.
Written on March 28, 2021 by Bryan Finster.
Originally published on Medium
Scrum or Kanban?

Should we use Scrum? Kanban? Is Kanban for support and Scrum for development? Is Scrum for newbs and Kanban for elites? Are we mature enough for Kanban?
These questions are a symptom of the Agile Industrial Complex selling certifications and people following the rules to get certified. Scrum or Kanban? The reality is that Scrum is not training wheels and Kanban is not for elites. Scrum is not for product development and Kanban is not for support work. Both are standardized approaches that emphasize small batches of work, feedback loops, limiting WIP, and frequent delivery. Both are done wrong by most teams because they focus on the process instead of the outcomes.
Ultimately it’s irrelevant. Teams who are good at delivery never ask about Scrum or Kanban. Instead, they simply deliver small batches of high-quality work very frequently. This isn’t rocket surgery and they didn’t get there by standardizing on 2-week sprints and reporting their velocity. They got there by focusing on the goals.
What are the goals? We need to have a systematic approach to improving the flow of delivery.
- Automate our delivery process to remove variance.
- Stabilize our quality signal and drive detection as far left as possible. This not only includes getting rapid test results but also includes getting feedback from the user to discover if we are delivering the right value.
- Limit work in progress and finish things before beginning new work.
- Drive down the size of stories to 1–2 days to improve quality and enable us to pivot rapidly to exploit new ideas that prove valuable.
- Small changes need to be flowing into version control, built, tested, and delivered VERY frequently (hours, not days) and without humans touching anything.
- Moderate new work intake to keep lead times low so that ideas do not become worthless while they wait on the backlog.
- Find ways to increase efficiency to improve throughput.
- Strive for transparency and trust in everything. Without good communication, we all fail.
- Measure and improve the things that help our customers.
We need to move fast and fail small and we need to do all of this at a sustainable pace that prevents burnout.
When we focus on Scrum or Kanban, we are focusing on the purity of the process. Our customers don’t care about the purity of our process. Our customers want features to be delivered rapidly and they need those features to be stable, available, secure, and useful. We need to focus on the things that make that happen. Nothing else matters.
Written on March 20, 2021 by Bryan Finster.
Originally published on Medium
Measuring Goals

In my last post, we talked about common metric anti-patterns that are focused on the process instead of value. In this installment, we will cover alternatives that can help us remove waste and improve the flow of value.
Defining Terms
Goal: Something we want to achieve that will improve the performance of our organization. In most businesses, performance can be measured by profitability, sales, etc. If we have goals focused on the business, we’ll probably perform better.
Signal: Something that tells us how we are tracking against our goal. A signal is something that may not be able to be measured directly, but only by inference. For example, quality and value are notoriously difficult to measure, so we must find proxies for those that give us insights.
Metric: An objective measure we can use as a proxy for a signal. More on this later.
Goals
So what are our goals? Some good goals for any enterprise are:
- Value: We want to improve the value of what we do by creating, saving, or protecting money.
- Sooner: We want to realize that value sooner with higher quality, less waste, and shorter lead times.
- More innovation: We want to find even better things to deliver and better ways to deliver them to delight our customers.
- Stability: We want solutions that our customers can depend on and we want engaged teams who own those solutions.
Signals
Looking at our goals, there are some keywords we can pick out for signals:
- Money: It’s difficult to track metrics that directly improve income, but we can track metrics that reduce costs. Income will depend on how good the product ideas are, but if we control our costs by reducing waste then it costs less to run experiments to find better ideas.
- Quality: We want higher delivered quality.
- Lead Time: We need to iterate faster and shorten the time between idea creation and idea validation with the end-user.
- Stability: Our customers should be able to depend on our services when they need them and only teams that have high morale and ownership can provide us the level of stability we need.
None of these signals can be measured directly. Even lead time has too many dependencies to be an objective metric that will show meaningful trends. However, we can measure things that give us insights into these.
Metrics
Money
Money and Waste are tightly coupled. More waste costs more money. So if we reduce waste we reduce costs. Waste is a function of process overhead, handoffs, delays, rework, etc. So if we want to reduce waste, we need to measure things that discourage the creation of waste.
To reduce waste, we need to reduce the batch size of changes, deliver them more quickly and validate that they meet customer expectations. We can track this using delivery frequency and defect rates. Depending on the context, customer NPS may also be a valuable insight.
Quality
To improve quality, we need to focus on effective quality gates that provide a stable signal as early as possible. Ultimate quality is determined by the end-user, not adherence to the development specifications (recall from my last article that they are probably wrong), so our most important quality metrics are delivery frequency and **defect rates.**These are trailing indicators, but there are upstream metrics we can measure that will help predict those outcomes. How frequently is code integrated into the trunk and tested? How long does it take to complete a development task? How long does it take between when a change is made and when it delivers to production? Code integration frequency, development cycle time, and build cycle time can be used to reduce the batch size further. If we are integrating code more frequently, the change-set size is smaller, easier to review the tests, and faster to get feedback. Smaller development tasks have more clarity as to how they should behave and contain fewer useless features. Driving down the time from commit to deploy improves the efficiency and effectiveness of the quality gates which also drives out additional waste and cost. It’s critical though that we keep the delivery frequency and defect rates in mind as the critical metrics. They safeguard quality.
Stability
Measuring the stability of an application is relatively straightforward, but that stability will be short-lived without a stable, high morale team. The same goes for efficiency. We can drive to faster delivery with fewer defects and achieve those goals in the short term while burning out the team. That results in turnover or disengagement that will then cost us all of the gains we’ve made and possibly put us worse off than we started. We should ask the team how they feel. Do they own their solutions? Are they provided with the opportunities to keep the code healthy and provide feedback about the expected value of a requested feature? Are they merely a feature factory that is accountable only to dates? Are people fleeing the team, or worse, the company? They need to be business experts who are invested in the business problem, own the solutions, and feel like valued contributors instead of replaceable cogs.
Lead Time
To reduce the lead time, we reduce the internal cycle times for development, build, and delivery. Delivery cycle time depends on development cycle time which depends on build cycle time, so the priorities should be obvious. Again, driving down the cycle times acts as a forcing function for waste reduction and quality improvement.
Metrics Case Study: Formula 1
F1 racing reams measure and continuously improve. Races are not won by the car that can go the fastest. Races are won by consistent usage of the accelerator, brakes, steering, and transmission to reduce wasted motion and get the most from the available speed. They are also won by the teamwork required to drive down cycle times that impact the goals.
KISS
We don’t’ need dozens of metrics for high-level insights. Yes, there are other things we can instrument to find out “why”, but for getting insights into the “what” that will move us towards our goals, we need to measure in combinations that inform our signals.
- Code integration frequency: Tested changes to trunk per day
- Development cycle time: Duration from “started” to “delivered”
- **Build cycle time:**Duration from “integrated” to “delivered”
- Delivery frequency: Production delivery rate
- Defect rates: Defects created relative to delivery frequency
- Team engagement: Team morale and ownership survey
Quality: code integration frequency, development cycle time, build cycle time, delivery frequency, defect rates, and team engagement.
Waste: code integration frequency, development cycle time, build cycle time, delivery frequency, defect rates, and team engagement.
Lead time: Delivery cycle time, development cycle time, build cycle time, and team engagement.
Stability: Operational stability metrics and team engagement
Metrics are not goals; they give us insights into the goal signals. If you measure something in isolation you will risk degrading something else. Always use offsetting groups. Ask yourself, “If we measure this what other things that we care about could go wrong?” and then measure those concurrently. Resist the urge to come up with a “score” that represents everything. If you over-simplify metrics, you will fall into chaos. Our goal isn’t to control the process. Our goal is observability into the value stream so we can improve it. Remember that product development is done by people and for people. People are not machines. Don’t measure people. Measure the flow and give people the observability to improve it.
Written on February 10, 2021 by Bryan Finster.
Originally published on Medium
The Thin Red Line

I was speaking at a DevOps meetup in Finland recently and was asked, “what does DevOps mean to you?” I love that they started the conversation that way. DevOps no longer means Development and Infrastructure teams cooperating and it has never truly been a job or a team. We are not solving a technical problem. We are trying to solve a business problem. How do we more effectively deliver value to our customers?
Note: If someone works for our company, they only become a customer when they buy something from our company.
DevOps is the way we work to improve the continuous flow of value to the end-user. Since our goal is to improve value delivery, we must measure how we deliver value, identify the constraints, and continuously improve the constraints. Everything we do and how we do it must be examined for the value it delivers and be removed if it is not delivering value. This is a long-term process that takes strategy, change management, and constant focus. The reason so many improvement efforts fail is that executives are rarely rewarded for long term improvement. Splashy “Transformation!™” efforts make analysts happy, make good presentations at conferences, and result in job offers. Real improvement requires more than the 2–3 year tenure of many IT executives.
In Star Trek gold is the color of command, blue is the color of science and medicine, and red is operations. Red Shirts are engineers, communications, security, and everything else required to keep the ship running. They are also the first to die when things get tense.
Every organization contains people who, when given the chance, will drive improvement. They care about where they work and the people they work with. They want to make their lives, their co-workers’ lives, and the lives of their customers better. In Gene Kim’s “The Unicorn Project”, the Red Shirts are the cast of engineers and engineering managers who want to make things better. They know where things are broken and decide the best thing to do is to fix things instead of seeking greener pastures. They are passionate, at times subversive, change agents who conspire to improve things that result in larger improvements and better lives for everyone. These characters are based on real stories Gene collected from the DevOps community. In the book, there aren’t very many of them. All of them can comfortably sit at the bar after hours and discuss the next things they will try to fix. It’s a fragile rebellion that could fail if only 2–3 key players left. This is the reality of most grass-roots efforts.
I had a conversation with Gene Kim in 2018 discussing the work of pushing from the grassroots. I’ll never forget what he told me, “This work requires a certain level of not caring about the consequences”. That’s true. It’s risky to challenge the status quo; to “swim upstream”. It requires courage even when you believe that a senior executive approves of the work. It requires challenging people who are not used to being challenged; pushing just hard enough to not get “promoted to customer”. Because of this, there are not very many people willing to do it. However, when change is starting, those are the people who will passionately drive the day to day improvements needed to achieve the mission. If an executive talks about making things better, the Red Shirts are the people who execute. In some cases, they are even the people selling the value to the CIO or CTO. They are the people who will infect others with the mission and expand the effort. That infection doesn’t come from meetings, OKRs, and directives filtering down the leadership chain. It comes from the Red Shirts understanding the goals, seeing the problems, and coming up with solutions.
This work is hard, it’s stressful, and the number of people driven to do it is a tiny fraction of any organization. I’ve spoken to many Fortune 100 companies who need real change to happen to stay competitive. You could literally count their Red Shirts on your fingers. If you want lasting change, you’ll need to find a way to expand the Thin Red Line. Make improvement a valued activity in the culture and recognize those who try.
Written on February 8, 2021 by Bryan Finster.
Originally published on Medium
Metric Mythconceptions

As we try to improve the flow of value to the end-user, the first item that usually gains focus is the productivity of development teams and how to measure it. I’d like to propose that productivity is measured by customer value delivery, not team output. However, that reality is often lost as we rush to find easy numbers to get a handle on measuring teams. Misusing metrics undermines the goals of improvement efforts and playing Whack-a-Mole with metrics anti-patterns is tedious. Hopefully, the anti-patterns cheat sheet will help.
Story points
**Myth:**How long it will take to complete a story
**Reality:**Story points are an abstraction of how complicated, how uncertain, and how big something is expressed by an arbitrary number that is only meaningful to the team, kinda. It’s mostly a holdover from Waterfall estimation and there are better ways to get this done.
**If you measure me by it:**If you want more story points, I’ll increase the number of points by creating more stories or increasing the number of points per story. Agile: where the stories are made up and the points don’t matter. Ron Jeffries said, “I like to say that I may have invented story points, and if I did, I’m sorry now.” The original intent of story points was to create an estimation abstraction instead of explaining to stakeholders, “yes, I said 3 days but that’s three days where I only need to develop and everything goes correctly”. Listen to Ron and split stories to a day or less and stop estimating.
Velocity/Throughput
**Myth:**Higher velocity/throughput means we are more productive!
Reality: Velocity or throughput give us an average of how many things of “about this size” we have completed during a time box so we can plan in the future.
If you measure me by it: If you want more completed in the same amount of time, I’ll create more tasks or increase the number of story points per task. “OK, I’ll just standardize the size of those!”, you say. Sorry, you can’t. You can make story points mean days, but that just means you’re faking agile delivery. If you want day estimates, then use days. Just be aware that estimation is wasteful. That time is better spent delivering and establishing a reliable history of delivery that makes us predictable. Also, consider that every change we make is new work that has never been done before. We aren’t building manufactured housing where each is the same. We are architecting something bespoke. We only have general ideas on time.
Code Coverage %
**Myth:**Code coverage means we are testing more, so we should have minimum code coverage standards.
Reality: Code coverage indicates the percentage of code that is being executed by test code. Test code has two important functions.
- It executes the code we want to test.
- It asserts some expectation about the results of that code.
Code coverage reporters measure the first activity. The second cannot be measured by robots because the efficacy of an assertion is knowledge work.
**If you measure me by it:**I’ll make sure more code is covered. That’s good, right? Maybe, but maybe not. It costs money to write and maintain test code, so we should eliminate tests that are not providing value. One example of meaningless code coverage is testing anemic publicgetter and setter methods that contain no business logic. Why these are bad is too deep a subject for this topic, but the result is we have methods that do nothing but access data. Testing them means we are only testing the underlying language. We cannot fix the language so we should not test it. Another example is just as wasteful but far more dangerous.
/*
The following is a simple example of real outcomes from mandating code coverage
minimums instead of measuring delivered quality with deploy frequency and defect rates.
This test will result in 100% code coverage but tests nothing.
If you find tests like these, DELETE THEM IMMEDIATLY. They provide less value than
not having a test. It's better to know that this wasn't tested.
*/
@Test
public void testMultiply() {
/*
First we execute the multuply method from the myMath class. This will run the method and
report to coverage reporters that the method is "covered"
*/
Integer result = myMath.multiply(5,10);
/*
Next we create the assertion to tell us if the test passed.
The assertTrue method in jUnit will return success if the input results in a true response
*/
assertTrue(true); //Assert something meaningless
/*
In this example, we directly pass 'true' so the assertion will always report success and the test
will never fail.
*/
}
This test increases code coverage and hides the fact that the code is not tested. It’s safer to delete this test than to leave it in place.
Committed vs. Completed
Myth: If we measure teams by how much they completed vs. what they committed to, they will work hard to meet the commitments and we’ll deliver more!
Reality: No battle plan ever survives contact with the enemy. The reason we are not using Waterfall anymore is that the industry has come to terms with the fact that life is uncertain and we cannot make hard plans for the next month, much less the next quarter or longer. One or more of the following is always true:
- The requirements are wrong
- We will misunderstand them
- They will change before we deliver
**If you measure me by it:**There are two actions I will take to ensure I meet this goal. First, I will commit to less work. This might be good because we tend to over-commit in the first place. It won’t make me work faster though. The other thing that I will do is to stick to the plan, no matter what. Defects will be deferred. If higher priority work is discovered, I’ll defer that too. Adherence to a plan ignores value delivery, but measuring me this way means you care more about the plan than the value. I care about the same things you care about if you’re paying me.
Lines of Code
Myth: If I am typing more lines of code per day, I’m more productive, so we need to measure lines of code or the number of commits per day for each developer.
Reality: Development is mostly not a physical activity. A top developer does more thinking than typing. The code is only the documentation of the proposed solution in a format that a computer can understand. The work is coming up with the solution and writing it in a way that is clearly understandable by future developers. I’ve delivered small enhancements before that resulted in the deletion of over 5,000 lines of code.
**If you measure me by it:**I’ll certainly make sure more code is added. I’ll have no real incentive to make the code easy to read or avoid re-use. Copying and pasting code is much easier than spending the time to develop a well-designed business solution.
Number of Defects Fixed
Myth: If we measure the number of defects fixed, there will be fewer defects
Reality: Defect reduction comes from working to improve delivered outcomes, not by focusing on the number of defect tickets we’ve closed.
**If you measure me by it:**Worst case is you pay me a bonus for defects fixed. Adding minor defects that I know where to find and fix is pretty simple. The next worst case is I’ll prioritize minor defects over critical feature work. I’ll also be scheduling meetings to argue if a defect is really a feature because moving it from “defect” to “enhancement” counts as defect reduction as well.
What should we measure?
We need to measure things that improve reduce waste and improve the flow of value. In the next installment, we will discuss some better metrics.
Written on February 8, 2021 by Bryan Finster.
Originally published on Medium
Storytime
The following is fantasy. Any resemblance to persons living or dead is coincidental. However, too many people live this.

ScrummerFall
Jackie is a buyer who needs better tools for forecasting demand so she can make better-informed decisions. She has a list of high value features she needs, so she contacts Dana, the product owner for the forecasting application, to request changes.
Dana discusses the features with Jackie and writes user stories for each feature with acceptance criteria for each story and adds them to the backlog. Since Q1 is half over, Dana schedules the new request to be discussed in the planning meeting for next quarter’s goals. There are lower value features prioritized for Q1, but it is important to prevent negatively impacting Leadership reporting on “committed vs completed”.
As the new quarter begins, Dana schedules time with the development team to discuss the upcoming features she committed to delivering and prioritizes the stories to be delivered on the first monthly release. The development team begins working on the first 2-week sprint while the testing team begins to build the test automation based on the stories.
At the end of the first sprint, the team submits their changes to the testing team for the testing sprint. However, on the second day of the next sprint, several defects are reported from the testing team, and effort on both teams shifts from development to triage and defect resolution. During the triage process, it’s discovered that the testing and development teams understood the acceptance criteria slightly differently on several stories. Dana schedules a meeting with Jackie to get clarification on how those stories should behave. In the meantime, the development team continues working with the testing team to resolve the defects in the remaining stories.
As the end of the second sprint nears, several of the stories are still impacted by defects and by the pending meeting between the product owner and business user. However, the team begins the process of preparing their change request for the stories that have passed testing for review by the change board and prepares their deploy documentation for the release management team.
After the Change Management Board reviews and approves the release and backout plan, the Release Management team schedules a time on Saturday for the development team to monitor the change after the release team deploys it. During the release, several issues occurred with the release plan that required the development team to make emergency changes to stay within the release window. This turned a scheduled 1-hour process into a 36-hour marathon to patch things so they would be ready by Monday morning.
On Monday morning, Jackie comes to work to try out the new features and is a bit confused. Many things she expected to be delivered have not been. In fact, the stories that have been delivered do not work the way she thought they would. Jackie begins creating defects and eventually emails Dana to request a meeting to find out why so little working software was delivered 2 months after her initial request.
After meeting with Jackie, Dana contacts the development team to find out why the plan failed. Brent, a new developer on the team, suggests that the most effective approach to discovering where things went wrong was to have a postmortem of the last two sprints that included representation from Jackie, Dana, the development team, the testing team, the release management team, and change management to have a holistic view of the entire delivery flow.
Identifying Causes
At the postmortem, Brent facilitates the discussion to find the pain points in the current process. He focuses the attention on “what” and “when” instead of “who”. This result took a team effort by all stakeholders after all.
- There were several handoffs of information between Jackie, Dana, the development team, and the testing team. Each of those resulted in a loss of context.
- Even though this work was a higher priority than several items on the previous quarter’s plan, it was scheduled for the next quarter to prevent poor reporting on the “committed vs completed” tracker.
- The first chance Jackie had to give feedback was after delivery to production.
- Testing was seen as the responsibility of the testing team. Quality feedback to the development team was delayed until at least a week after development had completed. In addition, each team had an alternative understanding of some of the features.
- The delivery process was manual and never verified.
- Because the manual change process required so much time, the team raced to complete work to make the cutoff date without sufficient quality feedback and created more issues as a result.
To begin resolving these issues, they focus on the biggest problems: an unreliable method to deliver changes and poor communication. They decide to make the following changes:
- They decide that Jackie and Dana will collaborate on reviewing the backlog frequently and will adjust roadmap priorities as needed rather than strictly adhering to a quarterly plan.
- Brent suggests that everyone will have more success if the communication paths are shortened. They decide that Jackie and Dana will meet frequently with the development team and some of the testers to refine work together as a group. They will work together to ensure that there are comprehensive testable acceptance criteria defined for each story and that no work will start on a story unless all stakeholders agree.
- The development team will schedule small demos twice a week with the product owner and once per week with Jackie to get more rapid feedback. In addition, effort will be given to improving the testing process over time with the goal that all tests are maintained by the development team. This will prevent two unneeded handoffs, two different misunderstandings of the stories, and the delayed quality feedback from waiting on another team.
- Development effort will be diverted to automate the release process and to ensure tests are executed as part of that process. Also, a representative from Change Management will work with the team as they build the delivery automation to ensure it contains the checks they are looking for in CAB and to certify their delivery process can be exempt from manual review.
Iterating to Better
After a couple of sprints of dedicated improvement efforts, things have improved greatly. There is still much work to be done on improving the testing process, but work is better understood and fewer defects are occurring. Jackie has transparency into how work is progressing and can make adjustments to stories as she sees her ideas come to fruition and decides additional changes may be needed to achieve the value she expects. She can also look at the backlog and remove things that are no longer valuable. The development team also has a deeper insight into the business goals Jackie has and begins suggesting improvements to her as well. Dana has a much clearer picture of what the priorities are. As the test and delivery automation improves, she can spend more time on product strategy instead of fighting fires and managing business user expectations. Best of all, the team has an improvement plan that will allow them to begin delivering changes during the working day safely.
Written on January 27, 2021 by Bryan Finster.
Originally published on Medium
Chaos Engineering

Delivering value to the end-users means we need systems that are useful, secure, and resistant to the shark-filled acid bath of the cloud environment. Engineering for chaos is crucial.
There are many resources that discuss the architectural concerns of resiliency engineering. Circuit breakers to gracefully handle the instability of our dependencies. Incrementally reducing feature abilities if dependencies are offline. Switching loads seamlessly between regions if one goes down or SLOs are exceeded. Redundant data persistence, idempotent messages, and etc. While we may be able to predict many failures and make them part of the initial design, we won’t predict for every failure. It requires a resilient product team to deliver resilient solutions.
What is a resilient team? It is a team that can continue to deliver value while dealing with the chaos of the real world. One of the principle practices of DevOps is that the team contains all of the capabilities required to deliver and operate their product. However, it’s possible to assemble a cross-functional team that’s brittle and will fall apart as soon as anything unexpected happens. Here are a few team anti-patterns that will put your ability to meet business goals at risk.
Individual Ownership
This anti-pattern is where a developer is the primary owner of some part of the system. This could be caused by a manager looking for ways to highlight someone for a promotion, someone joining the team who brings a new component with them, someone having expertise in a particular framework, or many other reasons. It’s tempting to do this. If we have a person who is an expert at something and we have deadlines, the obvious solution is to assign work based on expertise. This creates several large problems.
- What is the quality process? If only a small subset of the team understands something, how will the rest of the team review for quality?
- Things deliver slowly because no one else really understands the code or the business problem it solves. Therefore, no one on the team can help without onboarding.
- When the “owner” goes on vacation, has a family emergency, or wins the lottery, how will development continue in their absence?
Tactical decisions based on best-case scenarios and hope can succeed as long as nothing goes wrong. Business strategy requires embracing reality. Terminate knowledge silos with extreme prejudice.
The Change Agent
Improvement rarely starts as an overall team effort. However, improvement of daily work is a business deliverable. If we are not continuously improving, we are continuously degrading. There is no steady-state position. If we have a person on the team who is passionate about improving things, we cannot depend on that passion long-term as the driver of improvement.
- Passion burns out if there is no motion or active support.
- As in the “single owner” anti-pattern, the improvement will depend on the presence of that contributor. What happens when they seek greener pastures.
Leverage the passion for improvement to infect the team, but embed it into the team’s culture by incentivizing it as we would any other value delivery. Grow more change agents.
Assigned roles
Assigned roles and titles awesome for HR, but do not add value to the business. Product teams have one role; deliver business value and continuously improve how we do that.
- Assigning functional roles on the team leads to “not my job” and extended wait times while hand-offs occur within the team.
- If a link in the chain is broken due to the chaos of the real world, then value stops.
- If the flow of work overwhelms the capacity of one of the assigned roles, then lead times extend, and value is lost due to delay.
It’s fine to assemble a group of specialists to develop an MVP, but the complexity debt in the application and in the team will steadily increase if things remain specialized. Over the long term, that structure will drive you into a ditch. Optimize for sustainable value delivery and impact to the bottom line, not HR concerns.
These are all common issues on teams that are not deliberately architected to deliver resilient applications. When short term deliverables have more focus than long term strategy, we’ll miss our goals. Plan for chaos and architect teams for reality.
Written on January 25, 2021 by Bryan Finster.
Originally published on Medium
Continuous Delivery FAQ

There are many misconceptions about CD. There are also many things about CD that are not obvious on the surface. If you are “CD curious”, perhaps this will help.
“CI/CD or CD?”
It’s just “CD”. Just as DevOps encompasses security, business, compliance, user experience, etc., CD encompasses the entire development process.
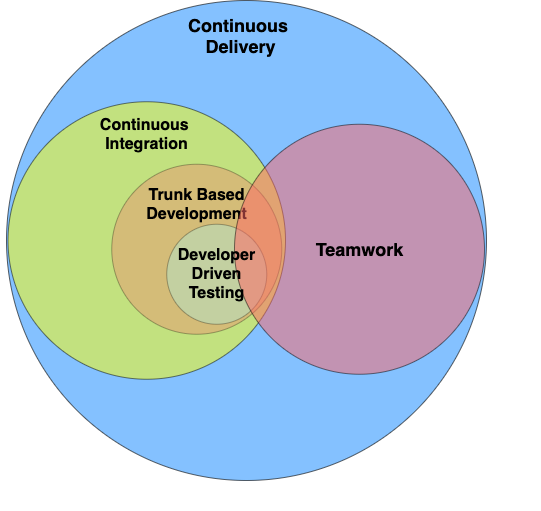
“There is no objective definition for CI”
There is an objective definition. Some may believe that pulling updates from the trunk daily but only integrating changes after several days of work to make sure the change is “feature complete” is CI. People believe all sorts of things that aren’t true. Believing really hard doesn’t make it more true. The point of CI is team communication. The code integrates very frequently and is tested together. This allows everyone to see everyone else’s changes. It reduces the problems with dependency between changes, code conflicts, etc. Smaller is better.
- CI Definition on Wikipedia
- CI practice and tips on MinimumCD.org
- Martin Fowler on CI
- Trunk Based Development patterns
“We automated the build. Are we doing CD?”
Build and deploy automation are important. Test automation is even more important. It takes people, process, and automation to execute CD. Automation is about 10% of the CD problem though.
Continuous delivery is continuous product development and continuous quality feedback. The robots enable us to standardize and accelerate delivery to reduce the cost and improve the safety of change. This makes it viable for us to deliver very small changes to get feedback on quality immediately. People frequently underestimate the definition of “small”. We aren’t talking epics, features, or even stories. We are talking hours or minutes worth of work, not days or weeks. A CD pipeline includes the robots, but it starts with the value proposition and ends when we get feedback from production on the actual value delivered so that we can make decisions about future value propositions. This takes teamwork from everyone aligned to the product flow and unrelenting discipline for maintaining and improving quality feedback loops.
“CD is just for unicorn startups?”
CD is a quality process, not an edge case used by dotComs iterating quickly on MVPs. Many startups will grind to a halt and fail because they don’t include “how will we reliably deliver future changes?” in their business plans. Hopefully, they get enough funding to clear the massive tech debt before that occurs.
The reasons for delivering very frequently are:
- Ensure that we can deliver patches quickly and safely in an emergency.
- Establish an efficient and effective quality signal to reduce mean time to detect.
- Reduce the size of changes to reduce the size of the defects in each change.
- Reduce the cost of change to enable more freedom to try new ideas.
CD, when used to drive down batch size and learn from production, acts as a forcing function for stability, efficiency, effective value delivery, and improved quality of life.
“We will focus on CD after we deliver these features”
There’s really no point in building a feature if you cannot reliably test and deliver the feature to validate the value. Also, you have no idea if your tests are valid until you deliver and find out.
- The requirements are probably wrong
- We probably misunderstood them
- They will probably change before we deliver
How much investment do you want to make in development before you find out how many of the above are true?
The correct order of operations is:
- Pipeline to production
- Production delivery of “hello world” to validate the pipeline
- Next change.
1 & 2 should occur on day 1.
“We’ll need to hire smarter people”
No, CD is the tool that grows better engineers and better teams. Solving the problem of “why can’t we deliver this change safely to production today?” in your context is an engineering problem that takes teamwork and disciplined development. If this is the primary focus then skills such as effective use of feature flagging, continuous integration, developer-driven testing, & etc. will grow rapidly. It also improves morale due to the reduced stress of repetitive toil and Fear Driven Development.
“Our users don’t want changes that often”
I assure you that when you have an impacting incident that your users want changes that often. There’s a big difference between generally exposing new features daily and delivering changes daily to verify they do not break. Again, this is a quality process, not a feature delivery process. We need quality feedback from continuous testing in production instead of hoping our next big release doesn’t break anything. Your next big release will break something. See point 3 above.
“We don’t believe these wild claims about CD”
That’s pretty common. Most people don’t understand how applying discipline to the development process and focusing on shrinking change-set sizes can make such a dramatic improvement to business outcomes and quality of life. Those of us who live that are trying daily to show that to you. Most of us aren’t paid consultants, tool vendors, or service vendors. We are telling you this because we want your lives to be better too and we want to maintain our quality of life if we join your organization.
“How hard is it to start?”
That very much depends on how teams are structured and how applications are structured. I recommend learning about Conway’s Law, Domain-Driven Design, and reading “Team Topologies”. For a team already organized to be small and product-focused, it will take a few months, given the right support and a knowledgeable person or two. For larger, legacy systems it will take the same broader organizational changes your competitors are working on today. The best time to plant a tree is 20 years ago. The second best time is today.
“What happens to teams who are prevented from improving CD?”
Once developers discover that their life is getting better, they will not want to stop. If you are in a management role for a team that is focusing on CD and then decide to send the team on a death march that prevents them from sustainably improving or decide to impose processes that prevent CD, the good ones will resist you by voting with their feet. You’ll be left with the below-average developers who didn’t fully embrace improvement. Good luck with your goals.
I will continue adding to this list as I think about other common questions. Feel free to check back or to comment with questions, challenges, or arguments you have where CD isn’t a valid process.
Changelog
- Jan 23 2021: Initial commit
- Mar 28 2021: Added “We automated the build. We are doing CD.”
Written on January 23, 2021 by Bryan Finster.
Originally published on Medium
The Value of Code Coverage

Code coverage is the measure of the amount of code being executed by tests. It’s an easy number to measure and a minimum value is frequently set as a goal. What is the actual value of code coverage?
True story, I was once in an organization where management told us that one of our annual goals was to ensure all applications had 90% code coverage. See, we were just starting to push testing in the area and they wanted to track our progress to make sure testing was happening. It was an interesting social experiment that I frequently see repeated in the industry. I learned a bit about people and measuring goals from that.
What was the outcome? Test coverage went up, naturally.
Let’s try this out. I’ve been given the task to write a function that will add two whole numbers. I have requirements that it should return the sum of two whole numbers but if a decimal value or a non-number is passed, then I need to return the JavaScript value for “Not a Number”. Should be easy.
<!DOCTYPE html>
<html lang="en" data-color-mode="auto" data-light-theme="light" data-dark-theme="dark" data-a11y-animated-images="system">
<head>
<meta charset="utf-8">
<link rel="dns-prefetch" href="https://github.githubassets.com">
<link rel="dns-prefetch" href="https://avatars.githubusercontent.com">
<link rel="dns-prefetch" href="https://github-cloud.s3.amazonaws.com">
<link rel="dns-prefetch" href="https://user-images.githubusercontent.com/">
<link rel="preconnect" href="https://github.githubassets.com" crossorigin>
<link rel="preconnect" href="https://avatars.githubusercontent.com">
<link crossorigin="anonymous" media="all" integrity="sha512-ksfTgQOOnE+FFXf+yNfVjKSlEckJAdufFIYGK7ZjRhWcZgzAGcmZqqArTgMLpu90FwthqcCX4ldDgKXbmVMeuQ==" rel="stylesheet" href="https://github.githubassets.com/assets/light-92c7d381038e.css" /><link crossorigin="anonymous" media="all" integrity="sha512-1KkMNn8M/al/dtzBLupRwkIOgnA9MWkm8oxS+solP87jByEvY/g4BmoxLihRogKcX1obPnf4Yp7dI0ZTWO+ljg==" rel="stylesheet" href="https://github.githubassets.com/assets/dark-d4a90c367f0c.css" /><link data-color-theme="dark_dimmed" crossorigin="anonymous" media="all" integrity="sha512-cZa7DZqvMBwD236uzEunO/G1dvw8/QftyT2UtLWKQFEy0z0eq0R5WPwqVME+3NSZG1YaLJAaIqtU+m0zWf/6SQ==" rel="stylesheet" data-href="https://github.githubassets.com/assets/dark_dimmed-7196bb0d9aaf.css" /><link data-color-theme="dark_high_contrast" crossorigin="anonymous" media="all" integrity="sha512-WVoKqJ4y1nLsdNH4RkRT5qrM9+n9RFe1RHSiTnQkBf5TSZkJEc9GpLpTIS7T15EQaUQBJ8BwmKvwFPVqfpTEIQ==" rel="stylesheet" data-href="https://github.githubassets.com/assets/dark_high_contrast-595a0aa89e32.css" /><link data-color-theme="dark_colorblind" crossorigin="anonymous" media="all" integrity="sha512-XpAMBMSRZ6RTXgepS8LjKiOeNK3BilRbv8qEiA/M3m+Q4GoqxtHedOI5BAZRikCzfBL4KWYvVzYZSZ8Gp/UnUg==" rel="stylesheet" data-href="https://github.githubassets.com/assets/dark_colorblind-5e900c04c491.css" /><link data-color-theme="light_colorblind" crossorigin="anonymous" media="all" integrity="sha512-3HF2HZ4LgEIQm77yOzoeR20CX1n2cUQlcywscqF4s+5iplolajiHV7E5ranBwkX65jN9TNciHEVSYebQ+8xxEw==" rel="stylesheet" data-href="https://github.githubassets.com/assets/light_colorblind-dc71761d9e0b.css" /><link data-color-theme="light_high_contrast" crossorigin="anonymous" media="all" integrity="sha512-+J8j3T0kbK9/sL3zbkCfPtgYcRD4qQfRbT6xnfOrOTjvz4zhr0M7AXPuE642PpaxGhHs1t77cTtieW9hI2K6Gw==" rel="stylesheet" data-href="https://github.githubassets.com/assets/light_high_contrast-f89f23dd3d24.css" /><link data-color-theme="light_tritanopia" crossorigin="anonymous" media="all" integrity="sha512-AQeAx5wHQAXNf0DmkvVlHYwA3f6BkxunWTI0GGaRN57GqD+H9tW8RKIKlopLS0qGaC54seFsPc601GDlqIuuHg==" rel="stylesheet" data-href="https://github.githubassets.com/assets/light_tritanopia-010780c79c07.css" /><link data-color-theme="dark_tritanopia" crossorigin="anonymous" media="all" integrity="sha512-+u5pmgAE0T03d/yI6Ha0NWwz6Pk0W6S6WEfIt8veDVdK8NTjcMbZmQB9XUCkDlrBoAKkABva8HuGJ+SzEpV1Uw==" rel="stylesheet" data-href="https://github.githubassets.com/assets/dark_tritanopia-faee699a0004.css" />
<link crossorigin="anonymous" media="all" integrity="sha512-EAhBCLIJ/pXHG3Y6yQhs9s53SHV80sjJ+yCwlQtfv7LaVkD+VoEuZBZ5betQJFUNj/5qBSfZk5GFtazEDzWLAg==" rel="stylesheet" href="https://github.githubassets.com/assets/primer-10084108b209.css" />
<link crossorigin="anonymous" media="all" integrity="sha512-d9qxvYDCx8mjHvFPT2FYDW0IbQ4NBX40LnnapTFQqQi9tlkpGN2g9gpwd+ZPLGZqQfITM5dtOke5EP7y8FOGTQ==" rel="stylesheet" href="https://github.githubassets.com/assets/global-77dab1bd80c2.css" />
<link crossorigin="anonymous" media="all" integrity="sha512-QVHRvU+lsiBTT0dePas9QeGUp/AUz8nmg5MOU5vTdzbvu8eEamPp51Zk/H9qsm70vBgDWe3fXKUDoxAs3pOe0g==" rel="stylesheet" href="https://github.githubassets.com/assets/github-4151d1bd4fa5.css" />
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-9kIUkROoz3qRLPYpBVPXcAwu2mSRB3l2ykBnEefEK6iqM5RHKPSsZ76/ZXyOC5mGuiFc47XGiwn3pg8E3tLqYg==" src="https://github.githubassets.com/assets/runtime-f642149113a8.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-4ytm+HbTBiWJpHp1HiEdx5ZV6Wms2WGHPLh4+ACDwBgU/ua/ziz0Qk3iPD4m1rBpCLukqjwEemWGl2xyvPnGog==" src="https://github.githubassets.com/assets/environment-e32b66f876d3.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-io+1MvgXPXTw8Kp4eOdNMJl8uGASuw8VfTY5VeIFETaAknimWi8GoxggMEeQ6mq0de4Dest4iIJ/9gUbCo0hgw==" src="https://github.githubassets.com/assets/vendors-node_modules_selector-observer_dist_index_esm_js-8a8fb532f817.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-Es25N4GyPa8Yfp5wpahoe5b2fyPtkRMyR6mKIXyCJC0ocqQazeWvxhGZhx3StRxOfqDfHDR5SS35u/R3Wux6Cg==" src="https://github.githubassets.com/assets/vendors-node_modules_delegated-events_dist_index_js-node_modules_github_details-dialog-elemen-63debe-12cdb93781b2.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-lmiecOIgf+hakg5oKMNM7grVhEDyPoIrT39Px448JJH5PSAaK21PH0Twgyz5O5oi8+dnlLr3Jt8bBCtAcpNdRw==" src="https://github.githubassets.com/assets/vendors-node_modules_github_filter-input-element_dist_index_js-node_modules_github_remote-inp-c7e9ed-96689e70e220.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-y67eNkVaNK4RguUGcHOvIbHFlgf1Qje+LDdjVw2eFuuvBOqta2GePz/CwoLIR/PJhhRAj5RPGxCWoomnimSw6w==" src="https://github.githubassets.com/assets/vendors-node_modules_github_catalyst_lib_index_js-node_modules_github_time-elements_dist_index_js-cbaede36455a.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-DE9GK/TS3Hf/dJfP1GMiyjvsGRnpR4A1eGH64s0Ot7Vy7Tj7/aD1d5EOMWHFWQXlXy/ZSwu5MHInG6RZN31bMA==" src="https://github.githubassets.com/assets/vendors-node_modules_github_file-attachment-element_dist_index_js-node_modules_primer_view-co-52e104-0c4f462bf4d2.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-i0Ha1jdl+Ze1GOoj8XJ4FmsHvIvxukCOi0Om2NK2574NSfisYFHJTigepoBa0Ft+u1d2T9Lc3C60Pn9ma+gAng==" src="https://github.githubassets.com/assets/github-elements-8b41dad63765.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-IkxSyqUlZiwuThbg3rOi8RD6r5e0m9OdtUdc+YAewC823+jpgEMlcP/eIQFjkFOJlq9yZKMKlobrTGIPfBuDEQ==" src="https://github.githubassets.com/assets/element-registry-224c52caa525.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-uo73yUZcm4EicwjSbfxFZcKfjWniOxhLBp+q1n7IFRfutFM6/lzbQMgD0Xrxp7QD1HzqdvrV8UclPhi3mEOyzQ==" src="https://github.githubassets.com/assets/vendors-node_modules_lit-html_lit-html_js-ba8ef7c9465c.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-5XdknqL9iTuaAhbOnKJDHf+5bJReOYDwlz5p2mW+SAVfab4RN6AfIliqtPwheKld40DrhPs47We/mT5nlZq2Sg==" src="https://github.githubassets.com/assets/vendors-node_modules_github_remote-form_dist_index_js-node_modules_github_catalyst_lib_index_-87b1b3-e577649ea2fd.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-0r1nf/rfPz54kyePp4f63bcPxkFo7wyaUZJD/SwIVDK3q0WzurAK9ydOm88tzKtPJm8xWI0Vo25NyCfecwxJ9g==" src="https://github.githubassets.com/assets/vendors-node_modules_github_mini-throttle_dist_index_js-node_modules_github_hotkey_dist_index-9f48bd-d2bd677ffadf.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-VkNE0AbPkr2TU6VW7p0hdWWLXTz4KsVdHZpIaR/Y44T9h5qJ4Td+hpFVZOVbfxiTOJVh7lyd2ICk/CNo4MI+Vw==" src="https://github.githubassets.com/assets/vendors-node_modules_github_paste-markdown_dist_index_esm_js-node_modules_github_quote-select-f71f15-564344d006cf.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-3H2GHBTxx8exTC9xT8LEQcEEEsFBwWEQUM0D9zs5SDtw6JjEZlW0j6JB1GG0/zgLnqcJaPRodIVuEKyDWxjugQ==" src="https://github.githubassets.com/assets/app_assets_modules_github_behaviors_pjax_ts-dc7d861c14f1.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-1VTsfTthjXvPtrjOvr3XUFjwRwpH5AloYdd7+mwF6+/CoUCyh9/ubBqMz7E7Mt87Pn2kihXHOBfRUWg1WZLkXw==" src="https://github.githubassets.com/assets/app_assets_modules_github_behaviors_keyboard-shortcuts-helper_ts-app_assets_modules_github_be-af52ef-d554ec7d3b61.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-NWll0aK8DvxvsFkfTc5M1jKhFioP/Mm0rUSzEJhQZkYIEMS/gRGK3kaKhokckGVFgzmdEdawcVw4SqVHJ8+vGg==" src="https://github.githubassets.com/assets/app_assets_modules_github_behaviors_details_ts-app_assets_modules_github_behaviors_include-fr-a5a4c7-356965d1a2bc.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-3pHFCSyIm9PY6CD8Dlu2uCTdRoBlrdLy4kmwWoQk/7xw9hFIGHYbnS94dSf/zyQAqWCkUNU0Z2DBt5t0tPW9zg==" src="https://github.githubassets.com/assets/behaviors-de91c5092c88.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-rLnbCtiKIpRtm1jgAz913tDImW3g8G+FLRMBIMwrkZ33pO8PMzWDG4m8Zl0uIIs10hCyFr6Dc8s6VDC200S9lg==" src="https://github.githubassets.com/assets/vendors-node_modules_delegated-events_dist_index_js-node_modules_github_catalyst_lib_index_js-01c6c51-acb9db0ad88a.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-paDaHAe8uAMftTo7ooywENAI3NeRIHNk0IxXV2vJxs3L5/F7hiGDPCDCq2YWOgshQV/AyMjc4bb3TzU9o/+BWQ==" src="https://github.githubassets.com/assets/notifications-global-a5a0da1c07bc.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-7D+usKScZ9o6LbSTCUPAPzqQibion+w0hRJ7z5q49c1OgKNOZmuO1GTr7MZRQE1sxG4BT78ZSW97mC8BUOfXIQ==" src="https://github.githubassets.com/assets/vendors-node_modules_github_clipboard-copy-element_dist_index_esm_js-node_modules_github_remo-9d7385-ec3faeb0a49c.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-3o22iDcc4unX7ots5Oy7lxj69diILvwJv2EPBu169NUyDt3jPIAkRNsz/UrN9QBJK6r6b5kSMhTb/pkMz4lwfQ==" src="https://github.githubassets.com/assets/app_assets_modules_github_diffs_blob-lines_ts-app_assets_modules_github_diffs_linkable-line-n-f314c3-de8db688371c.js"></script>
<script crossorigin="anonymous" defer="defer" type="application/javascript" integrity="sha512-D0asfFmKud7L80V75oA7aLwhbK2pgUagGaOwDc6lE12o0V8fzEkp5PzWoOrwr0nB1vnmJrXnYkrW98nBUifJpg==" src="https://github.githubassets.com/assets/gist-0f46ac7c598a.js"></script>
<title>Adding two numbers badly · GitHub</title>
<meta name="request-id" content="FC75:5A4D:57E92D:9372D6:62B5A004" data-pjax-transient="true"/><meta name="html-safe-nonce" content="482e002e44368ff2ba1dc7e3ac935d2fc2f814668fcae346a0c73e5398a23db6" data-pjax-transient="true"/><meta name="visitor-payload" content="eyJyZWZlcnJlciI6Imh0dHBzOi8vZ2lzdC5naXRodWJ1c2VyY29udGVudC5jb20vYmRmaW5zdC81MWUyODFkZDdhZDk2ZjJjMjU5MDM1OWFkNzcwNTQxZiNmaWxlLWFkZHdob2xlbnVtYmVycy1qcy9yYXciLCJyZXF1ZXN0X2lkIjoiRkM3NTo1QTREOjU3RTkyRDo5MzcyRDY6NjJCNUEwMDQiLCJ2aXNpdG9yX2lkIjoiMjI2MzUxMDY3OTMyOTAyMTk1NiIsInJlZ2lvbl9lZGdlIjoiaWFkIiwicmVnaW9uX3JlbmRlciI6ImlhZCJ9" data-pjax-transient="true"/><meta name="visitor-hmac" content="697abf73ffc5de2dff6cef48fac8c362714b18e6afafc656f795be1327ad1f1a" data-pjax-transient="true"/>
<meta name="github-keyboard-shortcuts" content="" data-pjax-transient="true" />
<meta name="selected-link" value="gist_code" data-pjax-transient>
<meta name="google-site-verification" content="c1kuD-K2HIVF635lypcsWPoD4kilo5-jA_wBFyT4uMY">
<meta name="google-site-verification" content="KT5gs8h0wvaagLKAVWq8bbeNwnZZK1r1XQysX3xurLU">
<meta name="google-site-verification" content="ZzhVyEFwb7w3e0-uOTltm8Jsck2F5StVihD0exw2fsA">
<meta name="google-site-verification" content="GXs5KoUUkNCoaAZn7wPN-t01Pywp9M3sEjnt_3_ZWPc">
<meta name="octolytics-url" content="https://collector.github.com/github/collect" />
<meta name="analytics-location" content="/<user-name>/<gist-id>" data-pjax-transient="true" />
<meta name="octolytics-dimension-public" content="true" /><meta name="octolytics-dimension-gist_id" content="107415153" /><meta name="octolytics-dimension-gist_name" content="51e281dd7ad96f2c2590359ad770541f" /><meta name="octolytics-dimension-anonymous" content="false" /><meta name="octolytics-dimension-owner_id" content="8195127" /><meta name="octolytics-dimension-owner_login" content="bdfinst" /><meta name="octolytics-dimension-forked" content="false" />
<meta name="user-login" content="">
<meta name="viewport" content="width=device-width">
<meta name="description" content="Adding two numbers badly. GitHub Gist: instantly share code, notes, and snippets.">
<link rel="search" type="application/opensearchdescription+xml" href="/opensearch-gist.xml" title="Gist">
<link rel="fluid-icon" href="https://gist.github.com/fluidicon.png" title="GitHub">
<meta property="fb:app_id" content="1401488693436528">
<meta name="apple-itunes-app" content="app-id=1477376905" />
<meta name="twitter:thumbnail:src" content="https://github.githubassets.com/img/modules/gists/gist-og-image.png" /><meta name="twitter:site" content="@github" /><meta name="twitter:card" content="summary_large_image" /><meta name="twitter:title" content="Adding two numbers badly" /><meta name="twitter:description" content="Adding two numbers badly. GitHub Gist: instantly share code, notes, and snippets." />
<meta property="og:image" content="https://github.githubassets.com/img/modules/gists/gist-og-image.png" /><meta property="og:thumbnail:alt" content="Adding two numbers badly. GitHub Gist: instantly share code, notes, and snippets." /><meta property="og:site_name" content="Gist" /><meta property="og:type" content="article" /><meta property="og:title" content="Adding two numbers badly" /><meta property="og:url" content="https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f" /><meta property="og:description" content="Adding two numbers badly. GitHub Gist: instantly share code, notes, and snippets." /><meta property="article:author" content="262588213843476" /><meta property="article:publisher" content="262588213843476" />
<link rel="assets" href="https://github.githubassets.com/">
<meta name="hostname" content="gist.github.com">
<meta name="expected-hostname" content="gist.github.com">
<meta name="enabled-features" content="IMAGE_METRIC_TRACKING">
<meta http-equiv="x-pjax-version" content="1233cc4ecf30b1a22963bf1da05b8083562ac7c876fd0dd89aaa03240cf87750" data-turbo-track="reload">
<meta http-equiv="x-pjax-csp-version" content="485d6a5ccbb1eeae9c86b616b4870b531f6f458e8bd5c309c40280dc4f51defb" data-turbo-track="reload">
<meta http-equiv="x-pjax-css-version" content="4b86fabb8e62df07ed1a2106c1c4cb847cbf31bbdf1fc1eae7a0adac45fc08cc" data-turbo-track="reload">
<meta http-equiv="x-pjax-js-version" content="6b8a04c60e96f975d03f9597fbe8ae4d41e671a065954ef1bf05b6a0b17c10fd" data-turbo-track="reload">
<meta name="turbo-cache-control" content="no-preview"></meta>
<link href="/bdfinst.atom" rel="alternate" title="atom" type="application/atom+xml">
<link crossorigin="anonymous" media="all" integrity="sha512-sh2yjS+AxvEdrKln9ht0mBnnVTVeQKatYC0mwWIVYyP/6rzOH6qLj5XypFJ+dAFa2BOCYc0Yhpq9iw4KtVFR0g==" rel="stylesheet" href="https://github.githubassets.com/assets/gist-b21db28d2f80.css" />
<meta name="turbo-body-classes" content="logged-out env-production page-responsive">
<meta name="browser-stats-url" content="https://api.github.com/_private/browser/stats">
<meta name="browser-errors-url" content="https://api.github.com/_private/browser/errors">
<meta name="browser-optimizely-client-errors-url" content="https://api.github.com/_private/browser/optimizely_client/errors">
<link rel="mask-icon" href="https://github.githubassets.com/pinned-octocat.svg" color="#000000">
<link rel="alternate icon" class="js-site-favicon" type="image/png" href="https://github.githubassets.com/favicons/favicon.png">
<link rel="icon" class="js-site-favicon" type="image/svg+xml" href="https://github.githubassets.com/favicons/favicon.svg">
<meta name="theme-color" content="#1e2327">
<meta name="color-scheme" content="light dark" />
</head>
<body class="logged-out env-production page-responsive" style="word-wrap: break-word;">
<div class="position-relative js-header-wrapper ">
<a href="#start-of-content" class="px-2 py-4 color-bg-accent-emphasis color-fg-on-emphasis show-on-focus js-skip-to-content">Skip to content</a>
<span data-view-component="true" class="progress-pjax-loader js-pjax-loader-bar Progress position-fixed width-full">
<span style="width: 0%;" data-view-component="true" class="Progress-item progress-pjax-loader-bar left-0 top-0 color-bg-accent-emphasis"></span>
</span>
<div class="Header js-details-container Details flex-wrap flex-md-nowrap p-responsive" role="banner" >
<div class="Header-item d-none d-md-flex">
<a class="Header-link" data-hotkey="g d" aria-label="Gist Homepage " href="/">
<svg aria-hidden="true" height="24" viewBox="0 0 16 16" version="1.1" width="24" data-view-component="true" class="octicon octicon-mark-github v-align-middle d-inline-block d-md-none">
<path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0016 8c0-4.42-3.58-8-8-8z"></path>
</svg>
<svg aria-hidden="true" height="24" viewBox="0 0 45 16" version="1.1" width="67" data-view-component="true" class="octicon octicon-logo-github v-align-middle d-none d-md-inline-block">
<path fill-rule="evenodd" d="M18.53 12.03h-.02c.009 0 .015.01.024.011h.006l-.01-.01zm.004.011c-.093.001-.327.05-.574.05-.78 0-1.05-.36-1.05-.83V8.13h1.59c.09 0 .16-.08.16-.19v-1.7c0-.09-.08-.17-.16-.17h-1.59V3.96c0-.08-.05-.13-.14-.13h-2.16c-.09 0-.14.05-.14.13v2.17s-1.09.27-1.16.28c-.08.02-.13.09-.13.17v1.36c0 .11.08.19.17.19h1.11v3.28c0 2.44 1.7 2.69 2.86 2.69.53 0 1.17-.17 1.27-.22.06-.02.09-.09.09-.16v-1.5a.177.177 0 00-.146-.18zM42.23 9.84c0-1.81-.73-2.05-1.5-1.97-.6.04-1.08.34-1.08.34v3.52s.49.34 1.22.36c1.03.03 1.36-.34 1.36-2.25zm2.43-.16c0 3.43-1.11 4.41-3.05 4.41-1.64 0-2.52-.83-2.52-.83s-.04.46-.09.52c-.03.06-.08.08-.14.08h-1.48c-.1 0-.19-.08-.19-.17l.02-11.11c0-.09.08-.17.17-.17h2.13c.09 0 .17.08.17.17v3.77s.82-.53 2.02-.53l-.01-.02c1.2 0 2.97.45 2.97 3.88zm-8.72-3.61h-2.1c-.11 0-.17.08-.17.19v5.44s-.55.39-1.3.39-.97-.34-.97-1.09V6.25c0-.09-.08-.17-.17-.17h-2.14c-.09 0-.17.08-.17.17v5.11c0 2.2 1.23 2.75 2.92 2.75 1.39 0 2.52-.77 2.52-.77s.05.39.08.45c.02.05.09.09.16.09h1.34c.11 0 .17-.08.17-.17l.02-7.47c0-.09-.08-.17-.19-.17zm-23.7-.01h-2.13c-.09 0-.17.09-.17.2v7.34c0 .2.13.27.3.27h1.92c.2 0 .25-.09.25-.27V6.23c0-.09-.08-.17-.17-.17zm-1.05-3.38c-.77 0-1.38.61-1.38 1.38 0 .77.61 1.38 1.38 1.38.75 0 1.36-.61 1.36-1.38 0-.77-.61-1.38-1.36-1.38zm16.49-.25h-2.11c-.09 0-.17.08-.17.17v4.09h-3.31V2.6c0-.09-.08-.17-.17-.17h-2.13c-.09 0-.17.08-.17.17v11.11c0 .09.09.17.17.17h2.13c.09 0 .17-.08.17-.17V8.96h3.31l-.02 4.75c0 .09.08.17.17.17h2.13c.09 0 .17-.08.17-.17V2.6c0-.09-.08-.17-.17-.17zM8.81 7.35v5.74c0 .04-.01.11-.06.13 0 0-1.25.89-3.31.89-2.49 0-5.44-.78-5.44-5.92S2.58 1.99 5.1 2c2.18 0 3.06.49 3.2.58.04.05.06.09.06.14L7.94 4.5c0 .09-.09.2-.2.17-.36-.11-.9-.33-2.17-.33-1.47 0-3.05.42-3.05 3.73s1.5 3.7 2.58 3.7c.92 0 1.25-.11 1.25-.11v-2.3H4.88c-.11 0-.19-.08-.19-.17V7.35c0-.09.08-.17.19-.17h3.74c.11 0 .19.08.19.17z"></path>
</svg>
<svg aria-hidden="true" height="24" viewBox="0 0 25 16" version="1.1" width="37" data-view-component="true" class="octicon octicon-logo-gist v-align-middle d-none d-md-inline-block">
<path fill-rule="evenodd" d="M4.7 8.73h2.45v4.02c-.55.27-1.64.34-2.53.34-2.56 0-3.47-2.2-3.47-5.05 0-2.85.91-5.06 3.48-5.06 1.28 0 2.06.23 3.28.73V2.66C7.27 2.33 6.25 2 4.63 2 1.13 2 0 4.69 0 8.03c0 3.34 1.11 6.03 4.63 6.03 1.64 0 2.81-.27 3.59-.64V7.73H4.7v1zm6.39 3.72V6.06h-1.05v6.28c0 1.25.58 1.72 1.72 1.72v-.89c-.48 0-.67-.16-.67-.7v-.02zm.25-8.72c0-.44-.33-.78-.78-.78s-.77.34-.77.78.33.78.77.78.78-.34.78-.78zm4.34 5.69c-1.5-.13-1.78-.48-1.78-1.17 0-.77.33-1.34 1.88-1.34 1.05 0 1.66.16 2.27.36v-.94c-.69-.3-1.52-.39-2.25-.39-2.2 0-2.92 1.2-2.92 2.31 0 1.08.47 1.88 2.73 2.08 1.55.13 1.77.63 1.77 1.34 0 .73-.44 1.42-2.06 1.42-1.11 0-1.86-.19-2.33-.36v.94c.5.2 1.58.39 2.33.39 2.38 0 3.14-1.2 3.14-2.41 0-1.28-.53-2.03-2.75-2.23h-.03zm8.58-2.47v-.86h-2.42v-2.5l-1.08.31v2.11l-1.56.44v.48h1.56v5c0 1.53 1.19 2.13 2.5 2.13.19 0 .52-.02.69-.05v-.89c-.19.03-.41.03-.61.03-.97 0-1.5-.39-1.5-1.34V6.94h2.42v.02-.01z"></path>
</svg>
</a>
</div>
<div class="Header-item d-md-none">
<button aria-label="Toggle navigation" aria-expanded="false" type="button" data-view-component="true" class="Header-link js-details-target btn-link"> <svg aria-hidden="true" height="24" viewBox="0 0 16 16" version="1.1" width="24" data-view-component="true" class="octicon octicon-three-bars">
<path fill-rule="evenodd" d="M1 2.75A.75.75 0 011.75 2h12.5a.75.75 0 110 1.5H1.75A.75.75 0 011 2.75zm0 5A.75.75 0 011.75 7h12.5a.75.75 0 110 1.5H1.75A.75.75 0 011 7.75zM1.75 12a.75.75 0 100 1.5h12.5a.75.75 0 100-1.5H1.75z"></path>
</svg>
</button> </div>
<div class="Header-item Header-item--full js-site-search flex-column flex-md-row width-full flex-order-2 flex-md-order-none mr-0 mr-md-3 mt-3 mt-md-0 Details-content--hidden-not-important d-md-flex">
<div class="header-search flex-self-stretch flex-md-self-auto mr-0 mr-md-3 mb-3 mb-md-0">
<!-- '"` --><!-- </textarea></xmp> --></option></form><form class="position-relative js-quicksearch-form" role="search" aria-label="Site" data-turbo="false" action="/search" accept-charset="UTF-8" method="get">
<div class="header-search-wrapper form-control input-sm js-chromeless-input-container">
<input type="text"
class="form-control input-sm js-site-search-focus header-search-input"
data-hotkey="s,/"
name="q"
aria-label="Search"
placeholder="Search…"
autocorrect="off"
autocomplete="off"
autocapitalize="off">
</div>
</form></div>
<nav aria-label="Global" class="d-flex flex-column flex-md-row flex-self-stretch flex-md-self-auto">
<a class="Header-link mr-0 mr-md-3 py-2 py-md-0 border-top border-md-top-0 border-white-fade" data-ga-click="Header, go to all gists, text:all gists" href="/discover">All gists</a>
<a class="Header-link mr-0 mr-md-3 py-2 py-md-0 border-top border-md-top-0 border-white-fade" data-ga-click="Header, go to GitHub, text:Back to GitHub" href="https://github.com">Back to GitHub</a>
<a class="Header-link d-block d-md-none mr-0 mr-md-3 py-2 py-md-0 border-top border-md-top-0 border-white-fade" data-ga-click="Header, sign in" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist header","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="f7b345f75fbc3f75d48e49b9c24023a79cd4a63dc63c42874f7b729e346b2282" href="https://gist.github.com/auth/github?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">
Sign in
</a>
<a class="Header-link d-block d-md-none mr-0 mr-md-3 py-2 py-md-0 border-top border-md-top-0 border-white-fade" data-ga-click="Header, sign up" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist header","repository_id":null,"auth_type":"SIGN_UP","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="78cc466708732ab6b09c4650ed14a2f2767b5b61546c1253b092de4b8fd8d380" href="/join?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f&source=header-gist">
Sign up
</a></nav>
</div>
<div class="Header-item Header-item--full flex-justify-center d-md-none position-relative">
<a class="Header-link" data-hotkey="g d" aria-label="Gist Homepage " href="/">
<svg aria-hidden="true" height="24" viewBox="0 0 16 16" version="1.1" width="24" data-view-component="true" class="octicon octicon-mark-github v-align-middle d-inline-block d-md-none">
<path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0016 8c0-4.42-3.58-8-8-8z"></path>
</svg>
<svg aria-hidden="true" height="24" viewBox="0 0 45 16" version="1.1" width="67" data-view-component="true" class="octicon octicon-logo-github v-align-middle d-none d-md-inline-block">
<path fill-rule="evenodd" d="M18.53 12.03h-.02c.009 0 .015.01.024.011h.006l-.01-.01zm.004.011c-.093.001-.327.05-.574.05-.78 0-1.05-.36-1.05-.83V8.13h1.59c.09 0 .16-.08.16-.19v-1.7c0-.09-.08-.17-.16-.17h-1.59V3.96c0-.08-.05-.13-.14-.13h-2.16c-.09 0-.14.05-.14.13v2.17s-1.09.27-1.16.28c-.08.02-.13.09-.13.17v1.36c0 .11.08.19.17.19h1.11v3.28c0 2.44 1.7 2.69 2.86 2.69.53 0 1.17-.17 1.27-.22.06-.02.09-.09.09-.16v-1.5a.177.177 0 00-.146-.18zM42.23 9.84c0-1.81-.73-2.05-1.5-1.97-.6.04-1.08.34-1.08.34v3.52s.49.34 1.22.36c1.03.03 1.36-.34 1.36-2.25zm2.43-.16c0 3.43-1.11 4.41-3.05 4.41-1.64 0-2.52-.83-2.52-.83s-.04.46-.09.52c-.03.06-.08.08-.14.08h-1.48c-.1 0-.19-.08-.19-.17l.02-11.11c0-.09.08-.17.17-.17h2.13c.09 0 .17.08.17.17v3.77s.82-.53 2.02-.53l-.01-.02c1.2 0 2.97.45 2.97 3.88zm-8.72-3.61h-2.1c-.11 0-.17.08-.17.19v5.44s-.55.39-1.3.39-.97-.34-.97-1.09V6.25c0-.09-.08-.17-.17-.17h-2.14c-.09 0-.17.08-.17.17v5.11c0 2.2 1.23 2.75 2.92 2.75 1.39 0 2.52-.77 2.52-.77s.05.39.08.45c.02.05.09.09.16.09h1.34c.11 0 .17-.08.17-.17l.02-7.47c0-.09-.08-.17-.19-.17zm-23.7-.01h-2.13c-.09 0-.17.09-.17.2v7.34c0 .2.13.27.3.27h1.92c.2 0 .25-.09.25-.27V6.23c0-.09-.08-.17-.17-.17zm-1.05-3.38c-.77 0-1.38.61-1.38 1.38 0 .77.61 1.38 1.38 1.38.75 0 1.36-.61 1.36-1.38 0-.77-.61-1.38-1.36-1.38zm16.49-.25h-2.11c-.09 0-.17.08-.17.17v4.09h-3.31V2.6c0-.09-.08-.17-.17-.17h-2.13c-.09 0-.17.08-.17.17v11.11c0 .09.09.17.17.17h2.13c.09 0 .17-.08.17-.17V8.96h3.31l-.02 4.75c0 .09.08.17.17.17h2.13c.09 0 .17-.08.17-.17V2.6c0-.09-.08-.17-.17-.17zM8.81 7.35v5.74c0 .04-.01.11-.06.13 0 0-1.25.89-3.31.89-2.49 0-5.44-.78-5.44-5.92S2.58 1.99 5.1 2c2.18 0 3.06.49 3.2.58.04.05.06.09.06.14L7.94 4.5c0 .09-.09.2-.2.17-.36-.11-.9-.33-2.17-.33-1.47 0-3.05.42-3.05 3.73s1.5 3.7 2.58 3.7c.92 0 1.25-.11 1.25-.11v-2.3H4.88c-.11 0-.19-.08-.19-.17V7.35c0-.09.08-.17.19-.17h3.74c.11 0 .19.08.19.17z"></path>
</svg>
<svg aria-hidden="true" height="24" viewBox="0 0 25 16" version="1.1" width="37" data-view-component="true" class="octicon octicon-logo-gist v-align-middle d-none d-md-inline-block">
<path fill-rule="evenodd" d="M4.7 8.73h2.45v4.02c-.55.27-1.64.34-2.53.34-2.56 0-3.47-2.2-3.47-5.05 0-2.85.91-5.06 3.48-5.06 1.28 0 2.06.23 3.28.73V2.66C7.27 2.33 6.25 2 4.63 2 1.13 2 0 4.69 0 8.03c0 3.34 1.11 6.03 4.63 6.03 1.64 0 2.81-.27 3.59-.64V7.73H4.7v1zm6.39 3.72V6.06h-1.05v6.28c0 1.25.58 1.72 1.72 1.72v-.89c-.48 0-.67-.16-.67-.7v-.02zm.25-8.72c0-.44-.33-.78-.78-.78s-.77.34-.77.78.33.78.77.78.78-.34.78-.78zm4.34 5.69c-1.5-.13-1.78-.48-1.78-1.17 0-.77.33-1.34 1.88-1.34 1.05 0 1.66.16 2.27.36v-.94c-.69-.3-1.52-.39-2.25-.39-2.2 0-2.92 1.2-2.92 2.31 0 1.08.47 1.88 2.73 2.08 1.55.13 1.77.63 1.77 1.34 0 .73-.44 1.42-2.06 1.42-1.11 0-1.86-.19-2.33-.36v.94c.5.2 1.58.39 2.33.39 2.38 0 3.14-1.2 3.14-2.41 0-1.28-.53-2.03-2.75-2.23h-.03zm8.58-2.47v-.86h-2.42v-2.5l-1.08.31v2.11l-1.56.44v.48h1.56v5c0 1.53 1.19 2.13 2.5 2.13.19 0 .52-.02.69-.05v-.89c-.19.03-.41.03-.61.03-.97 0-1.5-.39-1.5-1.34V6.94h2.42v.02-.01z"></path>
</svg>
</a>
</div>
<div class="Header-item f4 mr-0" role="navigation">
<a class="HeaderMenu-link no-underline mr-3" data-ga-click="Header, sign in" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist header","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="f7b345f75fbc3f75d48e49b9c24023a79cd4a63dc63c42874f7b729e346b2282" href="https://gist.github.com/auth/github?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">
Sign in
</a> <a class="HeaderMenu-link d-inline-block no-underline border color-border-default rounded px-2 py-1" data-ga-click="Header, sign up" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist header","repository_id":null,"auth_type":"SIGN_UP","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="78cc466708732ab6b09c4650ed14a2f2767b5b61546c1253b092de4b8fd8d380" href="/join?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f&source=header-gist">
Sign up
</a> </div>
</div>
</div>
<div id="start-of-content" class="show-on-focus"></div>
<div data-pjax-replace id="js-flash-container" data-turbo-replace>
<template class="js-flash-template">
<div class="flash flash-full {{ className }}">
<div class="px-2" >
<button class="flash-close js-flash-close" type="button" aria-label="Dismiss this message">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-x">
<path fill-rule="evenodd" d="M3.72 3.72a.75.75 0 011.06 0L8 6.94l3.22-3.22a.75.75 0 111.06 1.06L9.06 8l3.22 3.22a.75.75 0 11-1.06 1.06L8 9.06l-3.22 3.22a.75.75 0 01-1.06-1.06L6.94 8 3.72 4.78a.75.75 0 010-1.06z"></path>
</svg>
</button>
<div>{{ message }}</div>
</div>
</div>
</template>
</div>
<include-fragment class="js-notification-shelf-include-fragment" data-base-src="https://github.com/notifications/beta/shelf"></include-fragment>
<div
class="application-main "
data-commit-hovercards-enabled
data-discussion-hovercards-enabled
data-issue-and-pr-hovercards-enabled
>
<div itemscope itemtype="http://schema.org/Code">
<main id="gist-pjax-container" data-pjax-container>
<div class="gist-detail-intro gist-banner pb-3">
<div class="text-center container-lg px-3">
<p class="lead">
Instantly share code, notes, and snippets.
</p>
</div>
</div>
<div class="gisthead pagehead pb-0 pt-3 mb-4">
<div class="px-0">
<div class="mb-3 d-flex px-3 px-md-3 px-lg-5">
<div class="flex-auto min-width-0 width-fit mr-3">
<div class="d-flex">
<div class="d-none d-md-block">
<a class="mr-2 flex-shrink-0" data-hovercard-type="user" data-hovercard-url="/users/bdfinst/hovercard" data-octo-click="hovercard-link-click" data-octo-dimensions="link_type:self" href="/bdfinst"><img class="avatar avatar-user" src="https://avatars.githubusercontent.com/u/8195127?s=64&v=4" width="32" height="32" alt="@bdfinst" /></a>
</div>
<div class="d-flex flex-column width-full">
<div class="d-flex flex-row width-full">
<h1 class="wb-break-word f3 text-normal mb-md-0 mb-1">
<span class="author"><a data-hovercard-type="user" data-hovercard-url="/users/bdfinst/hovercard" data-octo-click="hovercard-link-click" data-octo-dimensions="link_type:self" href="/bdfinst">bdfinst</a></span><!--
--><span class="mx-1 color-fg-muted">/</span><!--
--><strong itemprop="name" class="css-truncate-target mr-1" style="max-width: 410px"><a href="/bdfinst/51e281dd7ad96f2c2590359ad770541f">addWholeNumbers.js</a></strong>
</h1>
</div>
<div class="note m-0">
Created <time-ago datetime="2021-01-16T14:12:39Z" data-view-component="true" class="no-wrap">Jan 16, 2021</time-ago>
</div>
</div>
</div>
</div>
<ul class="d-md-flex d-none pagehead-actions float-none">
<li>
<a class="btn btn-sm btn-with-count tooltipped tooltipped-n" aria-label="You must be signed in to star a gist" rel="nofollow" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist star button","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="36237ef14caa5b7ffa0d040bcc142af41a2b014f1cc9ee00ee5f7930f96e8187" href="/login?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-star">
<path fill-rule="evenodd" d="M8 .25a.75.75 0 01.673.418l1.882 3.815 4.21.612a.75.75 0 01.416 1.279l-3.046 2.97.719 4.192a.75.75 0 01-1.088.791L8 12.347l-3.766 1.98a.75.75 0 01-1.088-.79l.72-4.194L.818 6.374a.75.75 0 01.416-1.28l4.21-.611L7.327.668A.75.75 0 018 .25zm0 2.445L6.615 5.5a.75.75 0 01-.564.41l-3.097.45 2.24 2.184a.75.75 0 01.216.664l-.528 3.084 2.769-1.456a.75.75 0 01.698 0l2.77 1.456-.53-3.084a.75.75 0 01.216-.664l2.24-2.183-3.096-.45a.75.75 0 01-.564-.41L8 2.694v.001z"></path>
</svg>
Star
</a>
<a class="social-count" aria-label="0 users starred this gist" href="/bdfinst/51e281dd7ad96f2c2590359ad770541f/stargazers">
0
</a>
</li>
<li>
<a class="btn btn-sm btn-with-count tooltipped tooltipped-n" aria-label="You must be signed in to fork a gist" rel="nofollow" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist fork button","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="a76eb0451de5b3da159b02ceffa12340bd697b98026101b07e2d13457034c9f5" href="/login?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-repo-forked">
<path fill-rule="evenodd" d="M5 3.25a.75.75 0 11-1.5 0 .75.75 0 011.5 0zm0 2.122a2.25 2.25 0 10-1.5 0v.878A2.25 2.25 0 005.75 8.5h1.5v2.128a2.251 2.251 0 101.5 0V8.5h1.5a2.25 2.25 0 002.25-2.25v-.878a2.25 2.25 0 10-1.5 0v.878a.75.75 0 01-.75.75h-4.5A.75.75 0 015 6.25v-.878zm3.75 7.378a.75.75 0 11-1.5 0 .75.75 0 011.5 0zm3-8.75a.75.75 0 100-1.5.75.75 0 000 1.5z"></path>
</svg>
Fork
</a> <span class="social-count">0</span>
</li>
</ul>
</div>
<div class="d-block d-md-none px-3 px-md-3 px-lg-5 mb-3">
<a class="btn btn-sm btn-block tooltipped tooltipped-n" aria-label="You must be signed in to star a gist" rel="nofollow" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"gist star button","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="36237ef14caa5b7ffa0d040bcc142af41a2b014f1cc9ee00ee5f7930f96e8187" href="/login?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-star">
<path fill-rule="evenodd" d="M8 .25a.75.75 0 01.673.418l1.882 3.815 4.21.612a.75.75 0 01.416 1.279l-3.046 2.97.719 4.192a.75.75 0 01-1.088.791L8 12.347l-3.766 1.98a.75.75 0 01-1.088-.79l.72-4.194L.818 6.374a.75.75 0 01.416-1.28l4.21-.611L7.327.668A.75.75 0 018 .25zm0 2.445L6.615 5.5a.75.75 0 01-.564.41l-3.097.45 2.24 2.184a.75.75 0 01.216.664l-.528 3.084 2.769-1.456a.75.75 0 01.698 0l2.77 1.456-.53-3.084a.75.75 0 01.216-.664l2.24-2.183-3.096-.45a.75.75 0 01-.564-.41L8 2.694v.001z"></path>
</svg>
Star
</a>
</div>
<div class="d-flex flex-md-row flex-column px-0 pr-md-3 px-lg-5">
<div class="flex-md-order-1 flex-order-2 flex-auto">
<nav class="UnderlineNav box-shadow-none px-3 px-lg-0 "
aria-label="Gist"
data-pjax="#gist-pjax-container">
<div class="UnderlineNav-body">
<a class="js-selected-navigation-item selected UnderlineNav-item" data-pjax="true" data-hotkey="g c" aria-current="page" data-selected-links="gist_code /bdfinst/51e281dd7ad96f2c2590359ad770541f" href="/bdfinst/51e281dd7ad96f2c2590359ad770541f">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-code UnderlineNav-octicon">
<path fill-rule="evenodd" d="M4.72 3.22a.75.75 0 011.06 1.06L2.06 8l3.72 3.72a.75.75 0 11-1.06 1.06L.47 8.53a.75.75 0 010-1.06l4.25-4.25zm6.56 0a.75.75 0 10-1.06 1.06L13.94 8l-3.72 3.72a.75.75 0 101.06 1.06l4.25-4.25a.75.75 0 000-1.06l-4.25-4.25z"></path>
</svg>
Code
</a>
<a class="js-selected-navigation-item UnderlineNav-item" data-pjax="true" data-hotkey="g r" data-selected-links="gist_revisions /bdfinst/51e281dd7ad96f2c2590359ad770541f/revisions" href="/bdfinst/51e281dd7ad96f2c2590359ad770541f/revisions">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-git-commit">
<path fill-rule="evenodd" d="M10.5 7.75a2.5 2.5 0 11-5 0 2.5 2.5 0 015 0zm1.43.75a4.002 4.002 0 01-7.86 0H.75a.75.75 0 110-1.5h3.32a4.001 4.001 0 017.86 0h3.32a.75.75 0 110 1.5h-3.32z"></path>
</svg>
Revisions
<span title="1" data-view-component="true" class="Counter hx_reponav_item_counter">1</span>
</a>
</div>
</nav>
</div>
<div class="d-md-flex d-none flex-items-center flex-md-order-2 flex-order-1 file-navigation-options" data-multiple>
<div class="d-lg-table d-none">
<div class="file-navigation-option v-align-middle">
<div class="d-md-flex d-none">
<div class="input-group">
<div class="input-group-button">
<details class="details-reset details-overlay select-menu">
<summary data-ga-click="Repository, clone Embed, location:repo overview" data-view-component="true" class="select-menu-button btn-sm btn"> <span data-menu-button>Embed</span>
</summary> <details-menu
class="select-menu-modal position-absolute"
data-menu-input="gist-share-url"
style="z-index: 99;" aria-label="Clone options">
<div class="select-menu-header">
<span class="select-menu-title">What would you like to do?</span>
</div>
<div class="select-menu-list">
<button name="button" type="button" class="select-menu-item width-full" aria-checked="true" role="menuitemradio" value="<script src="https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f.js"></script>" data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"EMBED","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="d4de374b2ae38e0fd1f9f5ca0ec51c79bbc57c545a881c25ee09f35c52e302a5">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-check select-menu-item-icon">
<path fill-rule="evenodd" d="M13.78 4.22a.75.75 0 010 1.06l-7.25 7.25a.75.75 0 01-1.06 0L2.22 9.28a.75.75 0 011.06-1.06L6 10.94l6.72-6.72a.75.75 0 011.06 0z"></path>
</svg>
<div class="select-menu-item-text">
<span class="select-menu-item-heading" data-menu-button-text>
Embed
</span>
<span class="description">
Embed this gist in your website.
</span>
</div>
</button> <button name="button" type="button" class="select-menu-item width-full" aria-checked="false" role="menuitemradio" value="https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f" data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"SHARE","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="8370db36b63d1192dd7e7ead77a3ab17ccccd36973255ad0f51a105372300719">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-check select-menu-item-icon">
<path fill-rule="evenodd" d="M13.78 4.22a.75.75 0 010 1.06l-7.25 7.25a.75.75 0 01-1.06 0L2.22 9.28a.75.75 0 011.06-1.06L6 10.94l6.72-6.72a.75.75 0 011.06 0z"></path>
</svg>
<div class="select-menu-item-text">
<span class="select-menu-item-heading" data-menu-button-text>
Share
</span>
<span class="description">
Copy sharable link for this gist.
</span>
</div>
</button> <button name="button" type="button" class="select-menu-item width-full" aria-checked="false" role="menuitemradio" value="https://gist.github.com/51e281dd7ad96f2c2590359ad770541f.git" data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"USE_HTTPS","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="bb5cbd72d0536677b1ffb7abd5ef971a501ae0e3d043cdc841bd2ce6961e9356">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-check select-menu-item-icon">
<path fill-rule="evenodd" d="M13.78 4.22a.75.75 0 010 1.06l-7.25 7.25a.75.75 0 01-1.06 0L2.22 9.28a.75.75 0 011.06-1.06L6 10.94l6.72-6.72a.75.75 0 011.06 0z"></path>
</svg>
<div class="select-menu-item-text">
<span class="select-menu-item-heading" data-menu-button-text>
Clone via
HTTPS
</span>
<span class="description">
Clone with Git or checkout with SVN using the repository's web address.
</span>
</div>
</button> </div>
<div class="select-menu-list">
<a role="link" class="select-menu-item select-menu-action" href="https://docs.github.com/articles/which-remote-url-should-i-use" target="_blank">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-question select-menu-item-icon">
<path fill-rule="evenodd" d="M8 1.5a6.5 6.5 0 100 13 6.5 6.5 0 000-13zM0 8a8 8 0 1116 0A8 8 0 010 8zm9 3a1 1 0 11-2 0 1 1 0 012 0zM6.92 6.085c.081-.16.19-.299.34-.398.145-.097.371-.187.74-.187.28 0 .553.087.738.225A.613.613 0 019 6.25c0 .177-.04.264-.077.318a.956.956 0 01-.277.245c-.076.051-.158.1-.258.161l-.007.004a7.728 7.728 0 00-.313.195 2.416 2.416 0 00-.692.661.75.75 0 001.248.832.956.956 0 01.276-.245 6.3 6.3 0 01.26-.16l.006-.004c.093-.057.204-.123.313-.195.222-.149.487-.355.692-.662.214-.32.329-.702.329-1.15 0-.76-.36-1.348-.863-1.725A2.76 2.76 0 008 4c-.631 0-1.155.16-1.572.438-.413.276-.68.638-.849.977a.75.75 0 101.342.67z"></path>
</svg>
<div class="select-menu-item-text">
Learn more about clone URLs
</div>
</a>
</div>
</details-menu>
</details>
</div>
<input
id="gist-share-url"
type="text"
data-autoselect
class="form-control input-monospace input-sm"
value="<script src="https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f.js"></script>"
aria-label="Clone this repository at <script src="https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f.js"></script>"
readonly>
<div class="input-group-button">
<clipboard-copy for="gist-share-url" aria-label="Copy to clipboard" class="btn btn-sm zeroclipboard-button" data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"COPY_URL","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="1ece61d9bc63f783e60d58ab523362803599fde57bbb515665ebfb2627f78e45"><svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-copy">
<path fill-rule="evenodd" d="M0 6.75C0 5.784.784 5 1.75 5h1.5a.75.75 0 010 1.5h-1.5a.25.25 0 00-.25.25v7.5c0 .138.112.25.25.25h7.5a.25.25 0 00.25-.25v-1.5a.75.75 0 011.5 0v1.5A1.75 1.75 0 019.25 16h-7.5A1.75 1.75 0 010 14.25v-7.5z"></path><path fill-rule="evenodd" d="M5 1.75C5 .784 5.784 0 6.75 0h7.5C15.216 0 16 .784 16 1.75v7.5A1.75 1.75 0 0114.25 11h-7.5A1.75 1.75 0 015 9.25v-7.5zm1.75-.25a.25.25 0 00-.25.25v7.5c0 .138.112.25.25.25h7.5a.25.25 0 00.25-.25v-7.5a.25.25 0 00-.25-.25h-7.5z"></path>
</svg></clipboard-copy>
</div>
</div>
</div>
</div>
</div>
<div class="ml-2 file-navigation-option">
<a class="btn btn-sm tooltipped tooltipped-s tooltipped-multiline js-remove-unless-platform" data-platforms="windows,mac" aria-label="Save bdfinst/51e281dd7ad96f2c2590359ad770541f to your computer and use it in GitHub Desktop." data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"OPEN_IN_DESKTOP","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="662230b09481d5cc56c934b5f3057be12bbfc82d6f60ed2a5d8ede9dfacf47c9" href="https://desktop.github.com"><svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-desktop-download">
<path d="M4.927 5.427l2.896 2.896a.25.25 0 00.354 0l2.896-2.896A.25.25 0 0010.896 5H8.75V.75a.75.75 0 10-1.5 0V5H5.104a.25.25 0 00-.177.427z"></path><path d="M1.573 2.573a.25.25 0 00-.073.177v7.5a.25.25 0 00.25.25h12.5a.25.25 0 00.25-.25v-7.5a.25.25 0 00-.25-.25h-3a.75.75 0 110-1.5h3A1.75 1.75 0 0116 2.75v7.5A1.75 1.75 0 0114.25 12h-3.727c.099 1.041.52 1.872 1.292 2.757A.75.75 0 0111.25 16h-6.5a.75.75 0 01-.565-1.243c.772-.885 1.192-1.716 1.292-2.757H1.75A1.75 1.75 0 010 10.25v-7.5A1.75 1.75 0 011.75 1h3a.75.75 0 010 1.5h-3a.25.25 0 00-.177.073zM6.982 12a5.72 5.72 0 01-.765 2.5h3.566a5.72 5.72 0 01-.765-2.5H6.982z"></path>
</svg></a>
</div>
<div class="ml-2">
<a class="btn btn-sm" rel="nofollow" data-hydro-click="{"event_type":"clone_or_download.click","payload":{"feature_clicked":"DOWNLOAD_ZIP","git_repository_type":"GIST","gist_id":107415153,"originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="45dc0a4bee9878029bd0e991b52ba5590b40b4c29c7c9b400c83ba9b9d693407" data-ga-click="Gist, download zip, location:gist overview" href="/bdfinst/51e281dd7ad96f2c2590359ad770541f/archive/7962860f9ed312c0de521b3347fb4e5dddec8750.zip">Download ZIP</a>
</div>
</div>
</div>
</div>
</div>
<div class="container-lg px-3">
<div class="repository-content gist-content" >
<div>
<div itemprop="about">
Adding two numbers badly
</div>
<div class="js-gist-file-update-container js-task-list-container file-box">
<div id="file-addwholenumbers-js" class="file my-2">
<div class="file-header d-flex flex-md-items-center flex-items-start">
<div class="file-actions flex-order-2 pt-0">
<a href="/bdfinst/51e281dd7ad96f2c2590359ad770541f/raw/7962860f9ed312c0de521b3347fb4e5dddec8750/addWholeNumbers.js" data-view-component="true" class="btn-sm btn"> Raw
</a>
</div>
<div class="file-info pr-4 d-flex flex-md-items-center flex-items-start flex-order-1 flex-auto">
<span class="mr-1">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-code-square color-fg-muted">
<path fill-rule="evenodd" d="M1.75 1.5a.25.25 0 00-.25.25v12.5c0 .138.112.25.25.25h12.5a.25.25 0 00.25-.25V1.75a.25.25 0 00-.25-.25H1.75zM0 1.75C0 .784.784 0 1.75 0h12.5C15.216 0 16 .784 16 1.75v12.5A1.75 1.75 0 0114.25 16H1.75A1.75 1.75 0 010 14.25V1.75zm9.22 3.72a.75.75 0 000 1.06L10.69 8 9.22 9.47a.75.75 0 101.06 1.06l2-2a.75.75 0 000-1.06l-2-2a.75.75 0 00-1.06 0zM6.78 6.53a.75.75 0 00-1.06-1.06l-2 2a.75.75 0 000 1.06l2 2a.75.75 0 101.06-1.06L5.31 8l1.47-1.47z"></path>
</svg>
</span>
<a class="wb-break-all" href="#file-addwholenumbers-js">
<strong class="user-select-contain gist-blob-name css-truncate-target">
addWholeNumbers.js
</strong>
</a>
</div>
</div>
<div itemprop="text" class="Box-body p-0 blob-wrapper data type-javascript gist-border-0">
<div class="js-check-bidi js-blob-code-container blob-code-content">
<template class="js-file-alert-template">
<div data-view-component="true" class="flash flash-warn flash-full d-flex flex-items-center">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
<path fill-rule="evenodd" d="M8.22 1.754a.25.25 0 00-.44 0L1.698 13.132a.25.25 0 00.22.368h12.164a.25.25 0 00.22-.368L8.22 1.754zm-1.763-.707c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0114.082 15H1.918a1.75 1.75 0 01-1.543-2.575L6.457 1.047zM9 11a1 1 0 11-2 0 1 1 0 012 0zm-.25-5.25a.75.75 0 00-1.5 0v2.5a.75.75 0 001.5 0v-2.5z"></path>
</svg>
<span>
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
<a href="https://github.co/hiddenchars" target="_blank">Learn more about bidirectional Unicode characters</a>
</span>
<div data-view-component="true" class="flash-action"> <a href="{{ revealButtonHref }}" data-view-component="true" class="btn-sm btn"> Show hidden characters
</a>
</div>
</div></template>
<template class="js-line-alert-template">
<span aria-label="This line has hidden Unicode characters" data-view-component="true" class="line-alert tooltipped tooltipped-e">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
<path fill-rule="evenodd" d="M8.22 1.754a.25.25 0 00-.44 0L1.698 13.132a.25.25 0 00.22.368h12.164a.25.25 0 00.22-.368L8.22 1.754zm-1.763-.707c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0114.082 15H1.918a1.75 1.75 0 01-1.543-2.575L6.457 1.047zM9 11a1 1 0 11-2 0 1 1 0 012 0zm-.25-5.25a.75.75 0 00-1.5 0v2.5a.75.75 0 001.5 0v-2.5z"></path>
</svg>
</span></template>
<table class="highlight tab-size js-file-line-container js-code-nav-container js-tagsearch-file" data-tab-size="8" data-paste-markdown-skip data-tagsearch-lang="JavaScript" data-tagsearch-path="addWholeNumbers.js">
<tr>
<td id="file-addwholenumbers-js-L1" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="1"></td>
<td id="file-addwholenumbers-js-LC1" class="blob-code blob-code-inner js-file-line"><span class=pl-k>function</span> <span class=pl-en>addWholeNumbers</span><span class=pl-kos>(</span><span class=pl-s1>a</span><span class=pl-kos>,</span> <span class=pl-s1>b</span><span class=pl-kos>)</span> <span class=pl-kos>{</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L2" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="2"></td>
<td id="file-addwholenumbers-js-LC2" class="blob-code blob-code-inner js-file-line"> <span class=pl-k>if</span> <span class=pl-kos>(</span><span class=pl-s1>a</span> <span class=pl-c1>%</span> <span class=pl-c1>1</span> <span class=pl-c1>===</span> <span class=pl-c1>0</span> <span class=pl-c1>&&</span> <span class=pl-s1>b</span> <span class=pl-c1>%</span> <span class=pl-c1>1</span> <span class=pl-c1>===</span> <span class=pl-c1>0</span><span class=pl-kos>)</span> <span class=pl-kos>{</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L3" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="3"></td>
<td id="file-addwholenumbers-js-LC3" class="blob-code blob-code-inner js-file-line"> <span class=pl-k>return</span> <span class=pl-s1>a</span> <span class=pl-c1>+</span> <span class=pl-s1>b</span><span class=pl-kos>;</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L4" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="4"></td>
<td id="file-addwholenumbers-js-LC4" class="blob-code blob-code-inner js-file-line"> <span class=pl-kos>}</span> <span class=pl-k>else</span> <span class=pl-kos>{</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L5" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="5"></td>
<td id="file-addwholenumbers-js-LC5" class="blob-code blob-code-inner js-file-line"> <span class=pl-k>return</span> <span class=pl-v>NaN</span><span class=pl-kos>;</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L6" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="6"></td>
<td id="file-addwholenumbers-js-LC6" class="blob-code blob-code-inner js-file-line"> <span class=pl-kos>}</span></td>
</tr>
<tr>
<td id="file-addwholenumbers-js-L7" class="blob-num js-line-number js-code-nav-line-number js-blob-rnum" data-line-number="7"></td>
<td id="file-addwholenumbers-js-LC7" class="blob-code blob-code-inner js-file-line"><span class=pl-kos>}</span></td>
</tr>
</table>
</div>
</div>
</div>
</div>
<a name="comments"></a>
<div class="js-quote-selection-container" data-quote-markdown=".js-comment-body">
<div class="js-discussion "
>
<div class="ml-md-6 pl-md-3 ml-0 pl-0">
<!-- Rendered timeline since 2021-01-16 06:12:39 -->
<div id="partial-timeline-marker"
class="js-timeline-marker js-updatable-content"
data-last-modified="Sat, 16 Jan 2021 14:12:39 GMT"
>
</div>
</div>
<div class="discussion-timeline-actions">
<div data-view-component="true" class="flash flash-warn mt-3">
<a rel="nofollow" class="btn btn-primary" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"signed out comment","repository_id":null,"auth_type":"SIGN_UP","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="f0bb5a1fdd3c27d5886fb3315841d197252cb9d6dc179295f83ee8ec3425b386" href="/join?source=comment-gist">Sign up for free</a>
<strong>to join this conversation on GitHub</strong>.
Already have an account?
<a rel="nofollow" data-hydro-click="{"event_type":"authentication.click","payload":{"location_in_page":"signed out comment","repository_id":null,"auth_type":"LOG_IN","originating_url":"https://gist.github.com/bdfinst/51e281dd7ad96f2c2590359ad770541f","user_id":null}}" data-hydro-click-hmac="93a90ab89f91ac9057cf3e95eacf2e0363313ef0bac23ecbf4026158355be804" data-test-selector="comments-sign-in-link" href="/login?return_to=https%3A%2F%2Fgist.github.com%2Fbdfinst%2F51e281dd7ad96f2c2590359ad770541f">Sign in to comment</a>
</div>
</div>
</div>
</div>
</div>
</div>
</div><!-- /.container -->
</main>
</div>
</div>
<footer class="footer width-full container-lg p-responsive" role="contentinfo">
<div class="position-relative d-flex flex-items-center pb-2 f6 color-fg-muted border-top color-border-muted flex-column-reverse flex-lg-row flex-wrap flex-lg-nowrap mt-6 pt-6">
<ul class="list-style-none d-flex flex-wrap col-0 col-lg-2 flex-justify-start flex-lg-justify-between mb-2 mb-lg-0">
<li class="mt-2 mt-lg-0 d-flex flex-items-center">
<a aria-label="Homepage" title="GitHub" class="footer-octicon mr-2" href="https://github.com">
<svg aria-hidden="true" height="24" viewBox="0 0 16 16" version="1.1" width="24" data-view-component="true" class="octicon octicon-mark-github">
<path fill-rule="evenodd" d="M8 0C3.58 0 0 3.58 0 8c0 3.54 2.29 6.53 5.47 7.59.4.07.55-.17.55-.38 0-.19-.01-.82-.01-1.49-2.01.37-2.53-.49-2.69-.94-.09-.23-.48-.94-.82-1.13-.28-.15-.68-.52-.01-.53.63-.01 1.08.58 1.23.82.72 1.21 1.87.87 2.33.66.07-.52.28-.87.51-1.07-1.78-.2-3.64-.89-3.64-3.95 0-.87.31-1.59.82-2.15-.08-.2-.36-1.02.08-2.12 0 0 .67-.21 2.2.82.64-.18 1.32-.27 2-.27.68 0 1.36.09 2 .27 1.53-1.04 2.2-.82 2.2-.82.44 1.1.16 1.92.08 2.12.51.56.82 1.27.82 2.15 0 3.07-1.87 3.75-3.65 3.95.29.25.54.73.54 1.48 0 1.07-.01 1.93-.01 2.2 0 .21.15.46.55.38A8.013 8.013 0 0016 8c0-4.42-3.58-8-8-8z"></path>
</svg>
</a> <span>
© 2022 GitHub, Inc.
</span>
</li>
</ul>
<ul class="list-style-none d-flex flex-wrap col-12 col-lg-8 flex-justify-center flex-lg-justify-between mb-2 mb-lg-0">
<li class="mr-3 mr-lg-0"><a href="https://docs.github.com/en/github/site-policy/github-terms-of-service" data-analytics-event="{"category":"Footer","action":"go to terms","label":"text:terms"}">Terms</a></li>
<li class="mr-3 mr-lg-0"><a href="https://docs.github.com/en/github/site-policy/github-privacy-statement" data-analytics-event="{"category":"Footer","action":"go to privacy","label":"text:privacy"}">Privacy</a></li>
<li class="mr-3 mr-lg-0"><a data-analytics-event="{"category":"Footer","action":"go to security","label":"text:security"}" href="https://github.com/security">Security</a></li>
<li class="mr-3 mr-lg-0"><a href="https://www.githubstatus.com/" data-analytics-event="{"category":"Footer","action":"go to status","label":"text:status"}">Status</a></li>
<li class="mr-3 mr-lg-0"><a data-ga-click="Footer, go to help, text:Docs" href="https://docs.github.com">Docs</a></li>
<li class="mr-3 mr-lg-0"><a href="https://support.github.com?tags=dotcom-footer" data-analytics-event="{"category":"Footer","action":"go to contact","label":"text:contact"}">Contact GitHub</a></li>
<li class="mr-3 mr-lg-0"><a href="https://github.com/pricing" data-analytics-event="{"category":"Footer","action":"go to Pricing","label":"text:Pricing"}">Pricing</a></li>
<li class="mr-3 mr-lg-0"><a href="https://docs.github.com" data-analytics-event="{"category":"Footer","action":"go to api","label":"text:api"}">API</a></li>
<li class="mr-3 mr-lg-0"><a href="https://services.github.com" data-analytics-event="{"category":"Footer","action":"go to training","label":"text:training"}">Training</a></li>
<li class="mr-3 mr-lg-0"><a href="https://github.blog" data-analytics-event="{"category":"Footer","action":"go to blog","label":"text:blog"}">Blog</a></li>
<li><a data-ga-click="Footer, go to about, text:about" href="https://github.com/about">About</a></li>
</ul>
</div>
<div class="d-flex flex-justify-center pb-6">
<span class="f6 color-fg-muted"></span>
</div>
</footer>
<div id="ajax-error-message" class="ajax-error-message flash flash-error" hidden>
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
<path fill-rule="evenodd" d="M8.22 1.754a.25.25 0 00-.44 0L1.698 13.132a.25.25 0 00.22.368h12.164a.25.25 0 00.22-.368L8.22 1.754zm-1.763-.707c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0114.082 15H1.918a1.75 1.75 0 01-1.543-2.575L6.457 1.047zM9 11a1 1 0 11-2 0 1 1 0 012 0zm-.25-5.25a.75.75 0 00-1.5 0v2.5a.75.75 0 001.5 0v-2.5z"></path>
</svg>
<button type="button" class="flash-close js-ajax-error-dismiss" aria-label="Dismiss error">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-x">
<path fill-rule="evenodd" d="M3.72 3.72a.75.75 0 011.06 0L8 6.94l3.22-3.22a.75.75 0 111.06 1.06L9.06 8l3.22 3.22a.75.75 0 11-1.06 1.06L8 9.06l-3.22 3.22a.75.75 0 01-1.06-1.06L6.94 8 3.72 4.78a.75.75 0 010-1.06z"></path>
</svg>
</button>
You can't perform that action at this time.
</div>
<div class="js-stale-session-flash flash flash-warn flash-banner" hidden
>
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
<path fill-rule="evenodd" d="M8.22 1.754a.25.25 0 00-.44 0L1.698 13.132a.25.25 0 00.22.368h12.164a.25.25 0 00.22-.368L8.22 1.754zm-1.763-.707c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0114.082 15H1.918a1.75 1.75 0 01-1.543-2.575L6.457 1.047zM9 11a1 1 0 11-2 0 1 1 0 012 0zm-.25-5.25a.75.75 0 00-1.5 0v2.5a.75.75 0 001.5 0v-2.5z"></path>
</svg>
<span class="js-stale-session-flash-signed-in" hidden>You signed in with another tab or window. <a href="">Reload</a> to refresh your session.</span>
<span class="js-stale-session-flash-signed-out" hidden>You signed out in another tab or window. <a href="">Reload</a> to refresh your session.</span>
</div>
<template id="site-details-dialog">
<details class="details-reset details-overlay details-overlay-dark lh-default color-fg-default hx_rsm" open>
<summary role="button" aria-label="Close dialog"></summary>
<details-dialog class="Box Box--overlay d-flex flex-column anim-fade-in fast hx_rsm-dialog hx_rsm-modal">
<button class="Box-btn-octicon m-0 btn-octicon position-absolute right-0 top-0" type="button" aria-label="Close dialog" data-close-dialog>
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-x">
<path fill-rule="evenodd" d="M3.72 3.72a.75.75 0 011.06 0L8 6.94l3.22-3.22a.75.75 0 111.06 1.06L9.06 8l3.22 3.22a.75.75 0 11-1.06 1.06L8 9.06l-3.22 3.22a.75.75 0 01-1.06-1.06L6.94 8 3.72 4.78a.75.75 0 010-1.06z"></path>
</svg>
</button>
<div class="octocat-spinner my-6 js-details-dialog-spinner"></div>
</details-dialog>
</details>
</template>
<div class="Popover js-hovercard-content position-absolute" style="display: none; outline: none;" tabindex="0">
<div class="Popover-message Popover-message--bottom-left Popover-message--large Box color-shadow-large" style="width:360px;">
</div>
</div>
<template id="snippet-clipboard-copy-button">
<div class="zeroclipboard-container position-absolute right-0 top-0">
<clipboard-copy aria-label="Copy" class="ClipboardButton btn js-clipboard-copy m-2 p-0 tooltipped-no-delay" data-copy-feedback="Copied!" data-tooltip-direction="w">
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-copy js-clipboard-copy-icon m-2">
<path fill-rule="evenodd" d="M0 6.75C0 5.784.784 5 1.75 5h1.5a.75.75 0 010 1.5h-1.5a.25.25 0 00-.25.25v7.5c0 .138.112.25.25.25h7.5a.25.25 0 00.25-.25v-1.5a.75.75 0 011.5 0v1.5A1.75 1.75 0 019.25 16h-7.5A1.75 1.75 0 010 14.25v-7.5z"></path><path fill-rule="evenodd" d="M5 1.75C5 .784 5.784 0 6.75 0h7.5C15.216 0 16 .784 16 1.75v7.5A1.75 1.75 0 0114.25 11h-7.5A1.75 1.75 0 015 9.25v-7.5zm1.75-.25a.25.25 0 00-.25.25v7.5c0 .138.112.25.25.25h7.5a.25.25 0 00.25-.25v-7.5a.25.25 0 00-.25-.25h-7.5z"></path>
</svg>
<svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-check js-clipboard-check-icon color-fg-success d-none m-2">
<path fill-rule="evenodd" d="M13.78 4.22a.75.75 0 010 1.06l-7.25 7.25a.75.75 0 01-1.06 0L2.22 9.28a.75.75 0 011.06-1.06L6 10.94l6.72-6.72a.75.75 0 011.06 0z"></path>
</svg>
</clipboard-copy>
</div>
</template>
</body>
</html>
So I have a function that will check both inputs to verify that they are evenly divisible by 1. If they are not, then it returns NaN. Since alpha characters are also not divisible by 1, those will be trapped too. Naturally, we have tests for this because I am also told I need over 90% test coverage. Let’s run the coverage report!
code-coverage-ex (main ✔) » npm run coverage
Adding two whole numbers
✓ should return the sum of two whole numbers
✓ should return NaN if one number is not a whole number
2 passing (5ms)
--------------------|---------|----------|---------|---------|
File | % Stmts | % Branch | % Funcs | % Lines |
--------------------|---------|----------|---------|---------|
All files | 100 | 100 | 100 | 100 |
addWholeNumbers.js | 100 | 100 | 100 | 100 |
--------------------|---------|----------|---------|---------|
There we go, 100% coverage for every statement, code branch, and function. The gold standard of quality.
I even have a nice report for the product owner and my manager.

I’m done and ready to hand this off to whoever will be doing support for me. I’m a developer, after all, support is someone else’s problem.
Later that month, my change is delivered to production and customers start using my 100% covered code to add products to their shopping carts. Random quantity issues begin occurring and customers are getting angry about overcharges and massive over-shipment of products. Weird. We have really high code coverage. What went wrong?
Let’s log the output from the function
2 + 2 = 4
2.1 + 2 = NaN
A + 2 = NaN
2 + 2 = 22
So, the first three runs look great. What happened to the last run? Let’s look at the code.
console.log(`2 + 2 = ${addWholeNumbers(2, 2)}`)
console.log(`2.1 + 2 = ${addWholeNumbers(2.1, 2)}`)
console.log(`A + 2 = ${addWholeNumbers("A", 2)}`)
console.log(`2 + 2 = ${addWholeNumbers("2", 2)}`)
Hang on. That last run should have returned NaN too. We tested for strings
const expect = require("chai").expect
const addWholeNumbers = require("../addWholeNumbers")
describe("Adding two whole numbers", () => {
it("should return the sum of two whole numbers", () => {
expect(addWholeNumbers(2, 2)).to.be.not.NaN
})
it("should return NaN if one number is not a whole number", () => {
expect(addWholeNumbers(1.1, 2)).to.be.NaN
expect(addWholeNumbers("A", 2)).to.be.NaN
})
})
The tests above test very little that is meaningful to ensure the function works correctly. It was written to meet the goal of high code coverage. The customers didn’t care about that goal. The goal they cared about was that the function worked as intended. JavaScript is a very friendly language for rapid development. It typecasts for you. 2 + 2 = 4 but the + operator is also the string concatenation operator so "2" + 2 = "22". Also, numbers in a string can have number operators used on them so the modulus operator in the function to verify a whole number will typecast a numeric string as well. This is an easy mistake that could be caught in a review of the tests if the size of the code review is small enough. All we need to do is add a test for this problem.
The scenario above assumes the best intentions but nieve testing skills. We can fix this by focusing on the actual goal, “we are confident we are meeting the customer’s needs” and then teaching people how to test.
Let’s cover another scenario that I’ve personally witnessed as an outcome of “you must have 90% code coverage!”. I was code reviewing some old code one day. Reviewing tests is really the first priority anyone should have. I came across something terrifying. The code had very high coverage and was completely untested. Using the function above as an example, the tests were similar to this:
it('Should add two whole numbers' () => {
addWholeNumbers(2, 2)
addWholeNumbers(1.1, 0)
})
This test will also report 100% code coverage. It doesn’t actually run any tests. If you are judging a team on code coverage, how many of your tests look like this?
Testing is what professional software developers do. Pro’s have pride in their work and want to deliver working solutions to business problems. However, everyone will adapt to the environment they are placed in or they will choose to move to another environment. If developers are pushed to meet dates and push out features as fast as possible, quality processes are squeezed out. If they are then told to improve code coverage, code coverage will go up. The only thing scarier than untested code is code tested with tests you don’t trust.
What is the value of code coverage reporting? To find untested code that should be tested. There should never be a “code converge goal”. Instead, we should focus on what the customer needs and use an actual quality process: reduce the size of changes, focus on improving the quality signal from the pipeline, and deliver changes rapidly to find out if our fully tested application is tested using bad assumptions.
Only our users can define quality. A test is only our prediction of what they think. Deliver so you can test the test.
Written on January 16, 2021 by Bryan Finster.
Originally published on Medium
Measuring to Fail

Are you leading teams and want to make sure they are productive? There are many ways to do that. Many are doing it incorrectly.
It seems like I’m always talking about metrics. When I was first exploring how to grow continuous delivery as a team capability, I needed to find ways to find out we were doing it correctly. I mostly did it wrong at the start, but I sought out better information and then tried to verify if it was better.
Continuous delivery is not using Jenkins to automate build and deploy and hoping things don’t break. CD is the process of optimizing the flow to delivery, from request to the end-user, to improve quality feedback, continuously improve security and quality gates, and get user feedback a rapidly as possible. To know if you’re doing this well you need to understand metrics. However, even if you aren’t focusing on CD you need to understand how to measure because you cannot improve what you cannot measure.
Measuring Productivity
A common question is, “how productive are we?”. There are many ways to measure productivity, so let’s start with the bad ones.
Utilization
I had a conversation recently with a friend who told me their manager wanted to measure the utilization of the team to make sure they were fully utilized. In fact, the manager’s opinion was that if the teams weren’t sometimes failing to meet their commitments, they probably weren’t working hard enough. This attitude is something I hear frequently from many companies. I even hear it from manufacturing companies. That’s just astounding to me. No one in manufacturing would want 100% utilization of the assembly line. However, let’s ponder this in terms most engineering managers should understand.
This is a highway

This is a fully utilized highway

If you had a high-value delivery to get to your customer, which would you prefer to use?
Committed vs Completed
We want to make sure that teams are “meeting their commitments”. They promised they could deliver and we need to hold them accountable, right? So let’s focus on how much they failed to deliver. In the past five sprints, the team committed to 100 story points and delivered, on average, 50 story points. They really must not be very productive, right? So we will use this ratio to make them do better. Look! it worked! It just 1 sprint that lazy team decided to meet their commitments! they doubled their velocity! How’d they do that? We need all teams doing that?
They could reduce their commitment and inflate the story points or they could skip quality processes. We definitely want to encourage that because the metrics look better. Now everyone is happy but the customer.
Doing it better
Productivity is our ability to deliver what the customer needs and to continuously improve our ability to be more efficient and more effective at doing that in a sustainable way that reduces neither the health of the code nor the health of the team. We need to measure the things the customer cares about so we can make them happy. If the customer is unhappy, it really doesn’t matter how management feels about the metrics they are using. What does the customer care about? They want to reliably receive quality work when they need it. We can measure delivery frequency, change fail rates, bug reports, customer feedback, and team feedback. Productivity is not about how many features we can deliver. It can be more productive to deliver less because we are delivering the right features instead of racing to produce things that no one wants. Remember, activity is not work. If you add energy to an inefficient system, you mostly generate heat, not work. That is only valuable if the customer is cold.
Written on January 14, 2021 by Bryan Finster.
Originally published on Medium
2020
Holiday Special

Ah, holiday traditions. Christmas carols, Black Friday, Cyber Monday, fruit cake, egg nog, and change feeze. It’s that time of year again where companies everywhere stop allowing production changes. Let’s chat about this.

Change freeze, if you’re not aware, is the process of only allowing emergency patches to be deployed. This doesn’t mean that work stops on coding features. It means that features being coded are held until after the freeze and then delivered.
Another concept to consider is inventory, one of the main wastes in Lean. In a supply chain, you control your inventory. You want just enough to buffer against demand, but you would really like to have the information to allow Just In Time flow of product with little or no inventory. In software supply chains, we do not create inventory (user stories, code changes) unless there is already demand, so we have the ability to have minimal user story inventory and no code change inventory because we can design a system to flow high-quality changes to production as soon as they are created.
In software, inventory is riskier than in a physical supply chain. No two software changes are ever the same. This means that quality cannot be assured before delivery. We can validate we didn’t break previous changes, but we can only hope the current change is correct. This means we need feedback on every change from the end-user to find out. The larger the changeset, the more risk there is that we have problems.

So, back to change freeze. The teams are still building features, but their quality signal has been terminated. Yes, they are still testing (your team tests, right?) but they can only test for known poor quality. As the code inventory increases, the number of unknown defects also increases. When the freeze lifts, a giant batch inventory is converted to support calls.
So, why follow this tradition do this every year? Lack of confidence. The level of confidence that breaking changes can be prevented is too low. We can either accept this and perform the yearly ritual or try something else to reduce risk. I suggest two solutions.
- This year, spend the holidays looking at your system of delivery. Identify the things that you aren’t confident in and put an improvement process in place to gain confidence. Remove variance caused by manual processes and improve test efficiency and effectiveness. Make. Things. Better.
- If a disciplined improvement process seems like too much work, just give the development teams a paid vacation so that no more defects are generated without the ability to detect them. It’s just less risky.
If you have some other ideas for risk mitigation in software delivery, DM me on LinkedIn. Let’s make things better for everyone.
Written on October 23, 2020 by Bryan Finster.
Originally published on Medium
The Only Metric That Matters

I’ve been a software engineer for a while. When I had the opportunity several years ago to help uncover the core practices needed for continuous delivery, one of the things we needed to know was how to measure the outcomes. There are a bunch of things you CAN measure and some of them are even useful, but I want to propose just one metric to rule them all.
I’m a photographer. I’m also a major fan of fighter aircraft. The engineering required to balance controllability, survivability, maneuverability, etc. Plus, they are just pretty. A few years ago I had the opportunity to visit Nellis AFB in Las Vegas with a friend who’s a retired Lt. Colonel. We were there to visit the Thunderbirds museum and tour some other cool things. I highly recommend the “Petting Zoo” where they keep captured Eastern Bloc hardware. It’s fun sitting in a Constant Peg MiG.

This wasn’t an airshow that was open to the public. This was a Tuesday. Our group of five and a grandfather and his grandson were the only people there not working.

If you’ve not seen the Thunderbirds before, you should. They clearly demonstrate the outcomes of teams focused on missions they believe in.

This is the ground crew. These are the people who get it done. Each of these planes is owned by small teams and all of the teams are here. The airman on the right in a standard uniform is being evaluated. He joined the team to see how it works so he and they can see if he’s a fit. What you’re seeing here is the ground crew cheering the two pilots coming out for a practice mission, the same way they do at airshows. You see, they don’t go to an airshow and do airshow things and then do something else at home. They are always practicing for the mission. They perform the same tasks the same way every day so they can identify and resolve the unexpected quickly and also always know what the rest of the team will do.

This is the Thunderbirds’ commanding officer. Notice the names of the ground crew on the aircraft. That is the team that owns that aircraft. They let him use it.

…and it broke.
When they attempted to deploy TB1, there was an error. They had impressive MTTR. After about 10 minutes of triage, they decided that the required fix would delay things too long, so they spun up the standby aircraft. They know things will break. Failure is a promise. They practice for it. No one was blamed for the failure because failure is a consequence of trying to excel. Because they practice for it instead of trying to prevent it, it took 10 minutes to deploy a fix instead of hours or days of intensive checks to make sure nothing can break. The outcome?

They deployed him in Thunderbird 6.
So what was my takeaway? How does this relate to measuring high performing software development teams? That ground crew knew the mission. They believed in the mission. They had each others’ backs to perform the mission. The “new guy” was part of the team, not sidelined. They aren’t measured by the number of bolts turned. They are measured by mission readiness. The leading indicator for me of mission readiness is ownership of the mission. Ownership means they have the tools and skills they need to accomplish the mission, the ability to make things better, and responsibility for the outcomes.
For me, there is exactly one measurement that I can look at to get insights into the health of the product and the product team.

Pride
If you want to lead or be part of a team like this, check out my other articles in the “5 Minute DevOps” series. Together we can make every team the team we want to be part of.
Written on October 22, 2020 by Bryan Finster.
Originally published on Medium
Testing 101

Continuous delivery is a way of working to reduce cost and waste, not just build/deploy automation. For CD to be effective, we must identify and fix poor quality as early in the process as possible, never let poor quality flow downstream, and do this efficiently and quickly. Central to this is the discipline of continuous integration. CI requires that you have very high confidence that code is working before it is checked in and that those check-ins are happening at least daily, and tested on the trunk with the CI server. This requires efficient and effective testing as a core activity by everyone on the team. However, getting started can be daunting. There’s so much conflicting information available, much of it bad. People new to testing can get overwhelmed by the amount of information out there and tend to expect it to be complicated. There is also no common language for testing patterns. Ask three people what an “integration test” is and you’ll get four answers.
The reality is that testing isn’t that hard, it’s just code written for a different purpose. All that’s required is to pick some good source material, remember a few guidelines, understand the goals, and practice writing tests.
Good Sources
These are good places to start:
Now that we have some references that don’t suck, let’s hit the high points.
Some terms
- White-box testing: Testing the implementation. Inside out.
- Black-box testing: Testing the behavior. Outside in.
These are relative to what you’re testing, the system under test (SUT). If you’re testing a complicated function to verify it’s working correctly by sending inputs and asserting the output is as expected, then it’s a black-box test. If you are testing a workflow through a service relying only on tests that validate each method, you are white-box testing and have a very brittle test architecture that will make refactoring toilsome.
Goals
- We want to be confident that we can deploy this change without breaking something. This is very much different from 100% certainty. The level of confidence required is based on risk.
- We want most (80% — 90%) of that confidence before we push that change to version control. This means we build tests that can run locally, off-network, and quickly.
Not Goals
- **Code coverage.**Do not make code coverage a goal. Code coverage is an outcome of good practice, not an indicator that good practice exists. High code coverage with crappy tests is worse than low coverage you trust. At least with low coverage, you KNOW what’s not tested. Crappy tests hide that information from you. Use code coverage reports to find what really needs to be tested or to find dead code, but don’t fall for the vanity metric.
- **Comprehensive system tests.**Requiringa full system test for every deploy is an indicator of poor application or test architecture. This isn’t to say that End-to-End tests aren’t useful, but they should be minimal. Creating one of these monsters isn’t an achievement. It’s just money that could have been better spent on more efficient tests.
Good Practices
- Make the test fail before you make it pass. Writing tests that cannot fail is a pretty common error. Don’t suffer from misplaced confidence. This still bites me sometimes. Some would say I’m advocating TDD. Yes, I’m advocating TDD. It reduces rework to make code testable and speeds the next feature. Stop debating religious wars and test first unless you have no need to ever change the application again.
- Prefer black-box testing. Test WHAT is happening, not HOW it’s happening. It may be useful to use white-box tests as temporary scaffolding while you make a change, but refactor them to black-box or you will tightly couple the tests to the implementation. You should be able to freely refactor code without changes to tests. If you can’t, fix your test architecture.
- Prefer testing workflows instead of using lots of unit tests. Fowler calls these “sociable unit tests”. Kent Dodds calls this “integration testing” where you integrate several units into a workflow, but do not cross network interfaces. I recommend this article on it: Write tests. Not too many. Mostly integration. — Kent C. Dodds
- Don’t over-test. If your SUT depends on other components, make sure your test does not test the behavior of the other component. If you have behavior tested at a lower level, don’t retest that behavior with a test with a larger scope. Two tests testing the same thing means both need maintaining and one is probably wrong.
- Don’t under test. Unit tests are not enough. Full system tests used as the primary form of testing cannot fully traverse all of the paths without excessive cost.
- Record/replay testing tools are heroin. They are the Dark Side. Easier, quicker, more seductive. They are good for exactly one use-case, baselining behavior of untested legacy code while you refactor and test correctly. They do not replace proper testing and will become a constraint.
- Use TDD.TDD is a design tool that results in cleaner code and better tests and is the best way to get good at testing quickly. You’ll spend less time in maintenance mode if you learn this discipline. You can rant and rave all you want about religious wars, but you’ll still be spending more effort on the same outcomes if you assume it’s BS.
- Terminate flakiness with extreme prejudice. Flaky tests that randomly fail will corrupt your quality feedback while also costing time and money. Don’t be afraid to deactivate them and write better replacements. Some tests inherently tend to be flaky. Tests that require a database or another external component are an example. Minimize their use and keep the flaky tests out of your CD pipelines.
- Don’t use humans for robot work. There is one use case for manual testing, testing anything not based on rules. Exploratory testing is a prime example. We need evil human brains to think outside the box and explore what might break that we didn’t consider. If humans are using a script to test they are being used as really slow, expensive, and unrepeatable robots.
- Don’t assume the requirements are correct. This is one of the main reasons for CD, to get a small change to the end-user to find out how wrong we are. Therefore, a test written to meet the requirements can still be wrong. Start with defining the requirements with declarative, testable acceptance criteria, then test the tests by getting user feedback for small changes ASAP. The faster you can do this, the less money you will burn being wrong.
This is just the start and really only focused on the basics needed for CI. The book “xUnit Test Patterns” is nearly 900 pages long and doesn’t cover everything. There are many other kinds of tests that might be required: contract, performance, resilience, usability, accessibility, etc. If you’re trying to do CD, dig into testing. If you say you’re doing CD and aren’t focused on efficient and effective detection of poor quality early in the flow, are you sure you’re doing CD?
Written on October 17, 2020 by Bryan Finster.
Originally published on Medium
When to Resolve Tech Debt
If you don’t follow Dave Farley, co-author of Continuous Delivery, you’re missing out. In a recent conversation about the challenges of refactoring legacy code, one of the responses talked about when to resolve tech debt.
The problem isn’t how to schedule tech debt, it’s making it clear what tech debt is. After that, when to resolve it should be obvious
In The Unicorn Project, Gene Kim refers to tech debt as “complexity debt”; things in the software or environment that increase the complexity of operations and/or new changes. Experienced software developers can see tech debt as soon as they look at the code. However, it’s hard to translate what that looks like to others.
This is tech debt:

Now, a quick question: the next item on the backlog is scrambled eggs. The eggs are immediately available. How long will it take you to scramble 2 eggs? This is otherwise a simple task. There are known good practices with very low complexity until you walk into this kitchen to get it done.
The image above is the result of all of the focus being delivering a single meal instead of repeatedly producing meals. It was done in an amateur kitchen by people who do not cook for a living.
This is a professional kitchen:

The team is organized to produce a continuous flow of quality. This includes prepping, cooking, and cleaning in a continuous process to meet the customers’ needs. They never have conversations about waiting to clean the kitchen until after everyone is fed because they know doing that would increase complexity that would first slow, and then stop delivery as the quality degraded to unusable levels. Quality and complexity are tightly coupled.
Professional cooks keep the cooking area clean to enable quality, reduce complexity, and to make the next delivery easy to produce. So do professional developers. If you are a developer who does not clean up after yourself, please start. If you are managing development teams and tell them to leave cleaning up for later instead of making it part of every delivery, ask yourself which kitchen you’d like a meal from.
Written on August 15, 2020 by Bryan Finster.
Originally published on Medium
Organizing for Failure

I recently saw a documentary on the history of the Ford Edsel. There were so many lessons on the UX research, design, manufacturing, and marketing of Ford’s new brand that apply to developing any product. I suggest everyone look into it. Since I only have 5 minutes we’re going to focus on Ford’s quality process for the Edsel.
In 1958, Ford started to manufacture the Edsel. Since this was an entirely new make, they didn’t yet have an assembly line for it. So, they shared the line with other Ford passenger cars. The Edsel wasn’t just new bodywork. It had a new engine and more complicated assembly with many innovative, and complicated, options. To accommodate the expected sales, they modified the line so that every eighth car was an Edsel. This, of course, lead to constant context switching on the assembly line. Also, since the car was named for Henry Ford’s son, the previous chairman for whom the United Auto Workers had no love lost, there were occasional “assembly challenges”. However, Ford had a well defined QA process that would keep the line moving.
Ford’s QA process made sure that dealers got only the best Ford could deliver.
- As each car rolled off the line, it went through road tests and quality inspection and was given a quality score.
- All of the quality scores for the day’s production were averaged and if the average daily quality score met the minimum, the cars were shipped to the dealerships.
Since Edsel’s represented 1/8th of production and their quality scores were averaged in with the other 7/8ths, cars often shipped to dealerships with major issues to be resolved. This process worked fine for Ford until Toyota began disrupting the market.
The Toyota production system was created to reduce costs and increase quality so that they could compete. Core to the TPS is the reduction of waste by minimizing batch size, inspecting quality at every step, and preventing poor quality from moving to the next step. They made quality concurrent with manufacturing. This proved highly effective for increasing market share and allowing them to rapidly pivot to market needs. The Toyota system is something other manufacturers have worked to emulate for more than 50 years.
Ford’s quality process sounded AWFULLY familiar to my experiences in the past delivering software.
- Develop features, often with shifting priorities and pressure to meet deadlines for the scheduled release.
- Throw it over the wall to the testing team who logs defects
- A go/no-go decision is made on the large batch of changes based on the criticality of the defects.
- If the minimum quality is reached to ship, then the release goes to the customers and an operations team fixes the defects based on customer complaints.
This process hasn’t been a viable business model for manufacturing for more than 50 years and yet it’s all too common in software development.
A friend of mine told me that his organization’s QA team had built out a framework to make it easy for developers to fully test every change on their desktop. They were teaching teams TDD and BDD and were moving quality checks as close to the source of defect creation as possible. They were focusing also on the speed of feedback. A developer could get quality feedback from a fully integrated test in less than 3 minutes. They were taking Toyota’s lessons to heart and rapidly improving the teams’ abilities to deliver.
My friend also told me that one of the development managers in his organization is pushing back on the whole idea. “Why are we wasting time on this? Why are we asking developers to test? We have a testing team.” Attitudes like this hurt the bottom line.
Is your organization executing an actual continuous delivery development process with small, tested changes and rapid quality feedback to the developers? If not, when will you finally catch up to where manufacturing disruptors were over 60 years ago? Software is eating the world, but only for those who can move from artisanal development to modern software delivery.
Written on June 22, 2020 by Bryan Finster.
Originally published on Medium
Forking, Branching, or Mainline?

A frequent conversation I have is about branching patterns. Legacy development was all about long-lived branches to develop complete features followed by code freeze and merge hell. With continuous delivery, this changes. CD requires continuous integration and CI requires some form of trunk-based development with either mainline development or short feature branches. Which is the best pattern?
Mainline?
In mainline development, changes are made directly to the trunk. Zero branching. When people first hear of TBD, they frequently envision mainline. Mainline can be an effective process but it requires some things to be safe.
- Mature quality gates and team quality process
- Pair programming for instant code review
In regulated environments, this is typically discouraged as it makes code review unverifiable.
Fork or Branch?
The debate I most often hear is branching vs. forking. On teams who are “doing CD” meaning “we have an automated deploy process”, it’s very common for forking to be preferred because “that’s what open source does!” That’s true. untrusted contributors use forks in open source. It’s also very process-intensive, which is why teams actually executing with CD don’t do that.
A fork is a private copy of the source code. The flow is that I make a fork of the code, make changes, and then submit a complete change back to the core team for code review and eventual rejection or approval. While the fork exists, there is no visibility to the work that I’m doing. Open source uses this process because the number of people who start to contribute is much smaller than the number of people who finish a contribution. Since the forks are private, they do not clutter up the source tree of the main project with noise.
A branch is a copy of the code that is visible to the core team. It allows anyone on the core team to see the current changes and the progress of the work.
For CD to function, the team must be executing CI and that requires a high level of team communication. Additionally, a product team is responsible as a team for delivering changes. The individuals on the team do not have sole responsibility. Since forks are private to the individual developer, forks put the entire team at risk of not delivering.
- The team cannot see the progress of change
- The team has no way of finishing the change if the developer is unavailable.
When designing processes, pessimism is a very useful skill. “What can go wrong with this?” I used to joke that forking code within a product team put the team at risk because “what if someone gets hit by a bus?” I don’t joke about this anymore because of a team that had to re-create the work of a teammate who was involved in a fatal accident. The world is uncertain. Plan for it.
So, fork or branch? We should branch for all work the team is expected to deliver. Forks are for experiments or non-critical external contributions that have no priority. Open source is a model for open source problems, not for the problems of product team development and daily delivery.
Written on May 31, 2020 by Bryan Finster.
Originally published on Medium
Schrödinger's Pipeline
In the lifecycle of most applications there comes a time when they will go into maintenance mode where changes become very infrequent. This is even more common for utility services that are simple, but business-critical to multiple products. There is one thing that should never be skipped, a well-constructed delivery pipeline that fully exercises the application to verify it won’t break production. Having this in place means that future developers, even when they are us, have a clear path to deploy new changes with low risk. In fact, that pipeline and the effectiveness and efficiency of the quality gates should be the primary product for any team delivering business-critical applications and that pipeline must always be green or any changes to that code are just undeliverable waste.
When we are developing the application initially, there is a flurry of change. If we are doing CD correctly, those changes are verifying the pipeline is green daily. Later on, fewer changes are required as focus shifts to another domain in the product. What’s the impact of this?
Several years ago, a group of us were exploring the techniques of continuous delivery, we focused on pipeline construction, development practices, testing, and the metrics of delivery to see how we were progressing. We were doing this with a combination of existing legacy applications and greenfield development focused on exposing legacy logic and improving the user experience. This was a multi-team effort with a few of the teams also uncovering CD good practices to share with the broader organization. As the development effort evolved, one of the teams created a NodeJS API to wrap legacy ESQL/C code to expose the 20+-year-old core logic to the application being written by my team. There were many hard-won lessons. We even independently invented service virtualization to bypass the need for a 4-hour process to set up test data for an End-to-End test. After the API was stable, the focus moved elsewhere with no API changes required for several months. However, time passes quickly outside of the pipeline.
One day, a new feature required an API change. It was estimated that the new change would be ready for production in less than 2 days. My team’s application would be ready to use it later that week. Since we had a solid contract change process we were able to work in parallel based on mocks. However, when the API team’s first code change triggered their pipeline, they got a nasty shock. One of their core dependency libraries had been blacklisted for critical security vulnerabilities and the next available version introduced a breaking change. Major refactoring was required to upgrade the library before that simple change could be applied. A 1 to 2-day task stretched for a couple of weeks.
After the changes were finished, we had a CD post mortem. What happened? What can we do to prevent that from disrupting the flow of delivery in the future? The remediation plan we came up with was quite simple. We decided it’s not enough to trigger a build when the trunk changes, so we created scheduled jobs to build every pipeline weekly. There’s very little risk in deploying code that hasn’t changed to verify the pipeline is still green. Risk and uncertainty increase the longer the duration between builds.
Every delivery pipeline is focused on reducing risk. Any uncertainty in the pipeline must be aggressively weeded out. Long dormant pipelines are exactly like Schrödinger’s cat. They might be red and they might be green. Until they run and report the results, they are in the superposition of both red and green (brown?). Exercise them to collapse the function.
Written on May 31, 2020 by Bryan Finster.
Originally published on Medium
You Can't Measure Quality

“We want our teams to be more efficient and deliver higher quality!”
“We sure do, how will we measure it?”
The typical response is to apply a thin veneer of seemingly appropriate metrics, add a maturity model or two, and hope things get better. Whenever I hear of someone using code coverage to increase quality or using an “Agile maturity model” to improve team efficiency I know they need help. On the bright side, if you focus on the quality and drive down cycle times, then you get efficiency for free
First, let’s define some terms.
- Quality: Something the consumer finds useful.
- Efficiency: The ratio of the useful output in a process to the total resources expended.
- Cycle Time: The total time from the beginning to the end of a process.
Quality isn’t an abstract concept that can be predicted in isolation. Quality is the consumer finding the outcomes to be useful. Cycle time is how long it takes us to find out there are quality issues. By reducing the cycle time to get quality feedback, we reduce waste in the process and get efficiency for free.
You cannot measure quality. You can only measure the fact that poor quality exists. Does the consumer use your work? Are problems reported with your work?

This the 2017 MacBook Pro, Apple’s flagship laptop, until they started listening to their consumers again. I was waiting for this to come out in 2017 because I needed a new personal laptop. After it’s release, I went to the store, tried it out, and bought a refurbished 2016 model because the new one lacked quality. The keyboard lacked tactile feedback, it didn’t have the ESC key that all devs users use constantly, it didn’t have the ports I use when I travel for photography (dongles get lost in camera bags), and the touchpad is too big. I still use a mid-2014 for work and will until it dies or I can be assured I can get the new one with a better keyboard and an ESC key.
One of the basic behaviors required to establish a quality process is to establish a repeatable process to detect quality issues as rapidly as possible. In software, this is done using continuous delivery. Our first priority is to establish and maintain the ability to deliver to the consumer to find out how wrong we were. Our next priority is to deliver a small change and see if it’s we have quality problems and then continuously improve our ability to detect and prevent them in the future. The end-user isn’t the only consumer though. Every step in the process should reject poor quality.
We need to improve our tests
Code coverage is a terrible indicator of test quality. Code coverage reports how much code is exercised by test code while having nothing useful to say about the quality of those tests. We measure test quality by how ineffective the tests are from preventing defects from moving downstream. If we want to improve test quality, then we need to track the cycle time from commit to defect detection, Mean Time To Detect. The worst case is that they are found in production and that we deliver to production at the glacial pace of once a week or longer. The best case is that they are detected as soon as they are created using a mature CI process. So, we fix this by delivering more frequently (to reduce the number of defects per delivery) and we methodically measure and perform root cause analysis on defects to identify where the test suite can be improved to alert the developer much sooner. By methodically reducing the cycle time between defect creation and defect detection, testing quality improves. Tests will never prevent defects from occurring though and it’s critical we keep the cycle time from commit to delivery low to reduce the number and severity of production defects. Doing this reduces costs and improves efficiency.
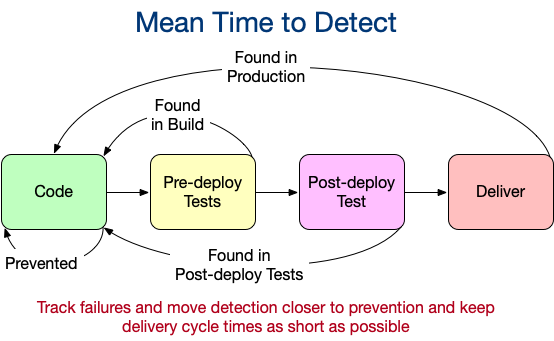
We need good user stories
When I first had “Agile” inflicted upon me I was told that “Agile maturity” included having user stories with acceptance criteria and fewer than 13 story points. I am reasonably sure I’m not the only one who had “Agile” inflicted upon them by someone who was qualified because they passed a test after a 2-day class. So we created stories and they had bullet-pointed acceptance criteria but somehow things didn’t get better. We had a good “maturity score” though. Agile development isn’t a process, it’s an outcome. We were measuring processes, not the delivery. When I got on a team that was working towards continuous integration (master always deployable, changes integrate to master multiple times a day) we discovered it wasn’t enough to have a bullet-pointed list created by a product owner. “Good” acceptance criteria can’t be measured, but bad is easy to measure. How often is work blocked due to a lack of understanding? How often do developers ask for clarification? How often are code reviews rejected because of disagreements over functionality? Worst, how often are defects found in production and then re-classified as “enhancements” because what was delivered matched the bullet points? To improve this, we must improve the process of delivering acceptance criteria to the consumer of the acceptance criteria; the developer. BDD is an excellent process for this, BTW. We also need to track the cycle time to go from the story (the ask) to acceptance criteria (the goal) that the team fully understands and knows how to test. If I cannot test it, I cannot execute CI, and I can’t deliver with agility. If we reduce the time it takes to do this, then we also reduce the cost.
There are many steps required to go from idea to delivery. Each of those steps must be a quality gate. Each step needs to have entry acceptance criteria that can trigger the rejection of poor quality work from the previous step. Measure the reject rates, how long it took to find the issue, and how much it cost and your quality and efficiency will improve. Quality cannot be known in isolation. It can only be derived from the feedback from the consumer of your service or product. You don’t want to find out after working for a month that you have poor quality because your end-user refuses to use the work.
Written on May 14, 2020 by Bryan Finster.
Originally published on Medium
Standardizing to Scale

Scaling improvement is the siren song of every enterprise. Once we have a team that is able to deliver the outcomes we are looking for, the obvious next step is to define those best practices for the rest of the teams. Then scaling is just a shake and bake exercise.
All we need to do now is to make all other teams work the way the successful team works:
- All teams will have the same sprint cadence
- All teams will have the same size story points (note: if using days for points, call them days. Points aren’t a measure of time.)
- All teams will use the same tech stack
- All teams will use the same quality process
- etc.
Success!
There are some problems with this approach though. It assumes all teams are solving the same problem with the same architecture and have the same skill levels. It also does some very destructive things:
- Leadership is responsible for quality instead of the teams
- Teams must ask permission to improve quality.
- All teams are constrained to the outcomes of the lowest-performing team.
That isn’t a good thing because leadership is usually the last to know about poor quality and usually because of customer feedback. If a team needs to ask permission to improve quality, they probably won’t. The teams with people who know better ways to deliver will have more turnover as those developers find less frustrating places of employment where they are respected as engineers. None of these are good for the bottom line.
Now what?
We still need all of the teams to improve and improvement isn’t just some random thing that accidentally happens. There must be a methodology to it. Instead of dictating the process, we need to use balanced metrics and ownership.
Metrics
- How frequently is code integrating into the trunk? This is a KPI for clear requirements and small coding tasks that are well understood by the team. This reduces guessing and defects.
- What is the build cycle time between code commit and code deployed to production? This is a KPI for the efficiency of the testing process. A test suite has two primary goals: notify the developer of any defect as soon as possible and allow the developer to quickly locate and fix the defect. This gives the best opportunity for the developer to learn how to not create that defect in the future. Prevention is much cheaper than detection and repair. Long cycle times here indicate poor test architecture that will reduce the team’s ability to improve development.
- Where are defects found in the build? Are most defects found in environments closer to production or, worse, in production? This is a KPI for the effectiveness of the test suite. Tests should be optimized to quickly detect defects as close to the source as possible.
Ownership
One of the practices people always talk about at conferences is “self-organized teams”. The thing people tend to leave out is that those self-organized teams become chaos without clearly defined goals and expectations. Self-organized teams have total ownership of their product. They are responsible for how it is built and feel the consequences of building it the wrong way. They eat their own dog food. Ownership can be destroyed by either telling them how to work or by outsourcing production support to another team. If they lack full ownership, the quality will always suffer.
Next Steps
Scaling quality comes from disciplined development, ownership, and practice. When we work with teams, we focus on the discipline of continuous integration. Each developer integrates fully tested, backward compatible code to the trunk at least once a day. If we can’t, why can’t we? Solve that problem and the next and the next. We make them responsible for the outcomes, and we reduce the batch size of everything so that things happen more frequently. We integrate rapidly because it improves the feedback loop. Give teams the freedom to find better ways that align with the goals, demand excellence, and get out of their way. They will deliver.
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on. Feedback is always welcome.
Written on March 9, 2020 by Bryan Finster.
Originally published on Medium
DevOps Darwinism
As organizations attempt to transform, they often focus on tooling or hiring “transformation consultants” as a silver bullet. However, tools are a small fraction of the problem and training teams to Scrum usually results in small, low-quality, waterfall projects. Organizations tend to struggle for some very common, simple, and difficult to fix reasons. If you are not getting the outcomes you wanted or expected, look around. Are you seeing these?
Tl; dr
Delivering value better to the end-user is not a problem that can be solved by hiring “smarter” developers or having teams use a new methodology. Improving value delivery requires the entire system to change.
Things aren’t improving because your organization isn’t configured for the improvement you want. What will you fix first?
Issues that Impact Team Evolution
The teams in the organization are organisms that have evolved to survive in the current working environment. The issues you see are not team failures; they are the behaviors that the teams have found that give them the best chance to thrive in your organization, even as the organization falls behind. Consider this while designing an improvement plan.
Poor Quality
Quality never comes from “just do it right the first time”. Quality is the outcome of having a clean quality signal that identifies poor quality as early as possible and by continuously improving every area where quality issues can occur. In software development, the main quality signals come form quality checks in the delivery process and customer feedback. The main quality issues come from humans modifying code. Since quality is the key enabler to availability and speed to market, we need to change our environment to improve the quality signal.
For decades, organizations have tried force quality at the end by assigning test teams to manually test or create test automation to inspect completed work. In fact, most universities don’t even include testing as part of any degree that includes software development. Testing is often seen as a lower-level position for failed developers. Would you buy a car where the only quality check was to drive it around the parking lot after assembly to make sure it didn’t instantly fall apart? How would that company identify the source of the inevitable issues? To resolve this, the team delivering the solution needs to put building a stable quality signal as their highest priority. We automate delivery to remove variation in the process. We build out tests to verify we have not broken working features. We relentlessly eliminate random test failures. We design every test with the idea of getting rapid notification of the failure as close to the source of the failure as possible.
Another issue is organizations offloading product support to support teams. This adds another filter to the quality signal that hides the pain of poor quality from the source of poor quality. Quality doesn’t come from trying harder. Quality comes from ownership of the solution and by feeling the consequences of poor quality.
Change the incentives. Teams must be given quality ownership. This does not mean punishing people for defects. This means making sure that engineers get rapid feedback on quality issues, have the authority to make the quality better, and are responsible for the consequences of poor quality by having direct support responsibility. This will require training and a focus on test design by everyone. Invest in the teams and they will deliver.
Knowing What to Build
Software delivery is a system. Coding is a small portion of that system. Knowing what to code, and what not to, is a critical activity that many teams skip because it “takes too much time”. It’s common to see “Agile” execution of the waterfall process of someone writing down requirements and handing them to developers to code. Water-scrum-fall. When the organization believes that we must “optimize for developer productivity” by making sure developers are coding as much as possible, then quality suffers. Breaking down work to the detail required for an effective quality process needs the whole team. This is the first chance the team has to implement its quality process:
- Do we understand how to measure the success of this feature?
- Do we know everything we need to know about how it’s expected to behave?
- Do we understand and have a plan for all dependencies, met or not?
- Is this the right thing to build into our product?
- Have we finalized the exact behaviors to prevent gold plating?
- Do we know how to verify the behaviors with tests?
All of these answers must be affirmative before work can start and only the team can answer these questions. If someone pushes the team to start work before these checks pass, who is at fault for the poor outcomes?
If teams are incentivized by tasks completed instead of value delivered, then the quality will suffer. To change the behavior from order taking to quality ownership, the team must be rewarded for outcomes, not output.
Large Batch Sizes
Large changes are risky, slow to deliver value, and delay quality signal. Most organizations unintentionally encourage large changes by having heavy approval processes, multiple handoffs, or project planning habits that think in terms of “done” instead of the next delivery of value. Teams react to these by batching up changes.
It is better to deliver many small things than one big explosion. How small is small enough? Any work that cannot be broken down into units that a single developer can deliver in a couple of days will not meet the standard for “small enough”. There will be hidden unknowns and assumptions that will reduce quality. Yes, it is an additional upfront effort. However, the entire system of delivery is improved. Everyone understands the work, everyone can help deliver it, and if any single team member becomes unavailable for any reason the work is only slightly impacted. Also, small changes begin to flow to the end-user rapidly enough to answer the most critical questions as cheaply as possible: Are we building the right thing? Can we verify quality?
The problem with small changes are they require an organizational shift in thinking. The entire system of delivery needs to be reviewed to remove cost and waste that incentivize large changes. Are there feedback delays from external team handoffs? Are we handling dependency management with code or with added process? Also, the developers need to understand that no feature is ever complete, so waiting to deliver complete features is wasteful.
Fixing the problems takes planning. Make sure you understand your delivery pipeline. Measure how long it takes to go from commit to production. Make sure you have a solid quality signal and then begin reducing the time between when work begins and when value is delivered. As you set the next improvement targets on this cycle time, you’ll uncover additional hidden waste either in the delivery pipeline, the development process, or upstream in how requirements are refined. Execute an improvement plan to fix the issues and change the environment to an expectation of continuous integration and small units of work.
Misaligned Incentives
A common anti-pattern is to attempt to measure a person’s productivity by the number of features they finish. Developers are problem solvers. If you give them the problem of “how can I make my productivity metric look good?”, they will do that at the expense of helping the team deliver value. Of course, since the delivered value is not being measured, it’s not important. Sure, the product is poor quality and the organization is failing, but I’m a rock star because of my output. I probably have a support team handling the defects anyway because support “reduces developer productivity”. My survival instinct tells me to avoid any work not related to my task so the new team members are on their own and I’ll avoid code review or just give it a passing glance. Those things make me “less productive”.
Quality comes from discussing issues and ideas. Value is delivered faster by teams collaborating. The team should be rewarded for the outcomes of their product and have the ability to improve those outcomes without being told to do so or asking permission. If I finish coding a task and submit it for code review, new work should be the last thing on my mind. There are probably other code reviews that need to be done; we are doing continuous integration after all. Someone on the team may be scratching their head or deep in thought about their work, how can I help them? What about that doubt I had about our tests? I should go try to break things in the application to see if I’m right. Continuous exploration to find new defects before the user discovers them helps to keep me sleeping at night. Nothing else to do? What‘s the next priority?
This working agreement leads to less code written and better outcomes. It’s our product. We are proud of it. We want it to be good. We want the user to embrace it. We build quality and deliver value, as a team, rapidly.
Culture Challenges
Team culture is incredibly important. Teams of heroes who are competing against each other for promotion deliver solutions that require heroism. Team members who fear obsolescence will hoard knowledge to become “indispensable”. Senior developers who desire respect over outcomes will demand to be the arbiter of good code and final reviewer of all change. None of these behaviors protect business goals.
A team is a group of individuals who all share a common goal, respect each other, and support each other to reach those goals. Team members elevate and help each other, they do not compete. However, it’s very common to see HR or leadership behaviors that are unintentionally designed to destroy this culture. Heroes awarded for handing the major outage. Comparing team members based on tasks completed. Some even use lines of code as a measure of productivity. This deep misunderstanding of teamwork is frankly shocking. If you recognize these anti-patterns, the environment must be changed,
Leadership Should Lead

“All of you need to change!” The problem is that the entire organization, including leadership, must change to support the outcomes. When change is focused only on the teams then the best case will be minor local optimization of a few interested teams who happen to be organized correctly. If your goal is to improve the ability of your organization to deliver, it’s not enough to say buzz-words and ask why nothing improves. You must study what is required to help the teams achieve those goals. You need to understand what current issues in the environment of your organization are causing the teams to work the way they are. You need to systematically change that environment to get the outcomes you want. This takes work. Get out in front. Dig in. Lead the change.
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on Feedback is always welcome.
Written on March 4, 2020 by Bryan Finster.
Originally published on Medium
2019
Liters Are Not a Unit of Distance

One of the most common pain points to anyone moving to modern delivery is, “how do we know we are doing it correctly?” I’d suggest setting measurable goals and frequently verifying if what we are doing is approaching those goals. However, people just starting out with too much new to learn will frequently grab metrics they think they understand and use them in ways that details the goals. This is not an exhaustive list, but they come up frequently.
Velocity
Measuring team productivity by the number of story points delivered each sprint.
Velocity doesn’t measure productivity. Velocity is a measure of the average capacity of the team so that the team can give planning guidance. It’s also exceptionally poorly named.
- Story points are an abstraction to attempt to mitigate how poorly humans are at estimating work. Over time, the team finds that “this kind of work is about this big” and story points stabilize. Smaller work, things that take a day or two, can be estimated in time but only with a team that is practiced at doing that work as a team. This is covered in more detail in In You Don’t Need Story Points.
- Velocity is an average of the number of story points the team has completed in past iterations.
“Given we have completed X story points on average and that we have work that is smaller than X * 80% (or so), then we can predict we’ll probably finish this work in the next iteration unless there are unexpected complications.”

If you ask a team to increase their velocity, they will. Story points will inflate. Some misguided leaders will attempt to standardize the size of a story point. That’s not possible. All they do is translate story points to time and create a math problem for everyone to solve for every story. If you want to do this, just use time. The problem is still there though. If we measure velocity as the number of estimated hours or days delivered in an iteration, then estimates get inflated to show improvement over time.
Productivity is measured by how frequently we can delivery stable changes that deliver value to the end-user.
Agile Maturity Scores
Team Agile Maturity Scores aren’t a thing. That’s a fake metric sold by “Agile” money mills. You don’t observe “maturity” and you never mature. You inspect and adapt. The faster you can deliver, the more you can inspect, and the faster you adapt. There are no defined processes in agile development. There are known good practices that teams should be aware of and adopt as they see fit to improve their ability to deliver. Teams should review and compare their practices to the principles of the Manifesto.
Agile Adoption Rate
This can only be measured by outcomes: delivery frequency, lead time to change, mean time to recover, and change fail rate. Those outcomes show how agile you are. There are surveys some “Agile Transformation” companies use to measure this. Based on those survey’s most teams will be industry leaders in Agile in only weeks or a few months. If someone hands you a maturity survey, find a better source.
We should set improvement goals over time and educate everyone on known good practices that help them reach those goals. Those practices only become their own if they choose them. If told how to work, they do will adopt and they have no route to improve. This is why most “agile transformations” fail. The core culture required is not adopted. “Command and control” is incompatible with improvement. Toyota learned this 50 years ago.
Initiative Milestones
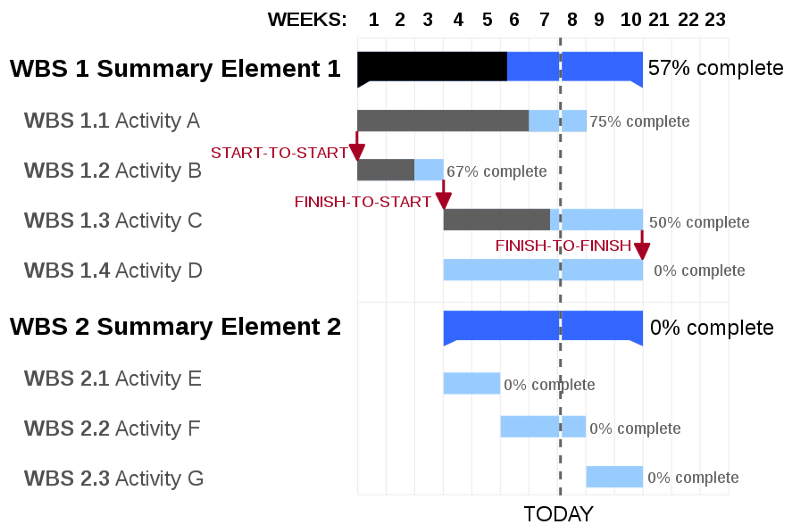
This assumes the initiatives will meet the goals. It’s a blind march to “we did what we said we’d do” without considering feedback on if we should be doing it at all. Instead, we should set product value delivery goals and metrics. “We will reduce the time spent doing X by 50% if we deliver this next feature”. Then reward achieving that. Even more important, reward the behavior of recognizing when that isn’t happening and changing course to a better outcome.
Agile Maturity
This is what agile delivery looks like, the continuous delivery of value to the end-user. The faster a product can close this loop, the higher the quality and the lower the total cost of ownership. Helping the team widen their pipeline by removing waste increases their ability to deliver. Planning deliverables for the next year with set milestones makes this ability almost irrelevant. That legacy process removes learning and improving from the plan.
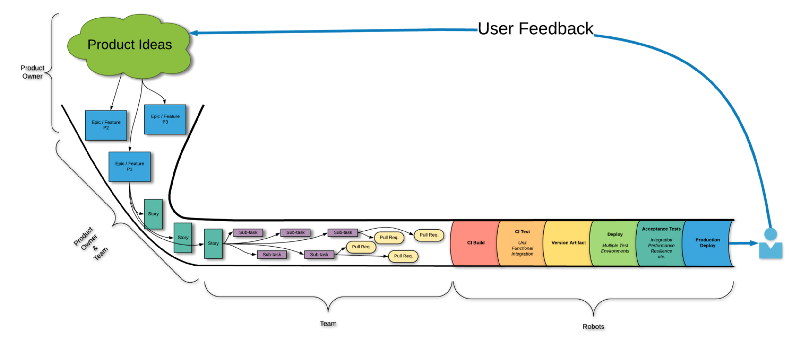
Measuring correctly is key and metrics must be used wisely or even the right metrics can be destructive. Measure in offsetting groups to prevent gaming. One of the exercises I do is look at metrics and use my software testing brain against them. “What can go wrong? How can I break this? How can I game this to look good?” Then I tell people.
Go forth and use meters for distance. Liters are for volume.
Written on August 16, 2019 by Bryan Finster.
Originally published on Medium
Engineering Culture Change with CI
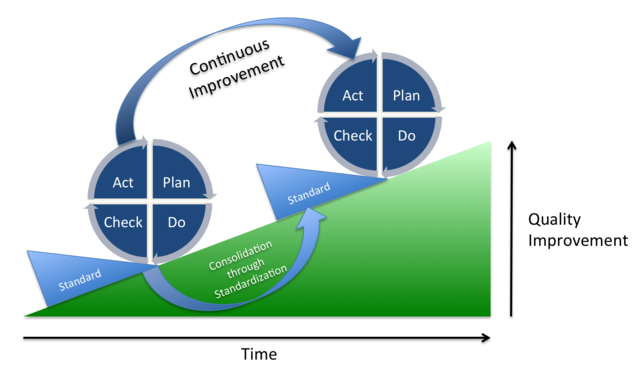
So, you hired an “Agile Transformation” consulting company to advise executive leadership and you’re “Agile” now. Leadership attended a week-long class on “Agile”, and teams took a two-day class about Scrum being The Way. The new methodology with story points, daily standup, and sprints now reigns, but outcomes haven’t changed. Next, you talk about the “agile mindset” while Scrum Masters report monthly on how much “velocity” has increased. At the team level, the labels have changed, but the processes are the same. Possibly there is less design, but you don’t design solutions in “Agile”. They just “emerge”, right?
What went wrong? Marketing and the desire for silver bullets overtook goals and outcomes. You saw a framework that was popular and bought it without understanding the underlying principles. However, frameworks are solutions that worked for someone else in their context, not yours, and no drive-by “transformation” will result in anything except loss of revenue, frustration, and low satisfaction from both customers and employees. For real change to happen, it needs to be ingrained into the culture. Culture and mindset change requires behavior change. At the team level, we do this with constructive constraints and rapid feedback.
“Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.”
That’s our goal: the continuous delivery of valuable software is our highest priority. That’s the outcome we are after, continuous delivery; CI/CD. We can measure that outcome, apply the correct constraints, and move the culture.
Not Buzzwords
Continuous integration and continuous delivery have measurable outcomes, they aren’t buzzwords. I often hear people use “CI/CD” when they mean build tool automation and don’t even get me started on “DevOps”.
“We’ve created a DevOps team to implement CI/CD pipelines and manage the releases. We’re DevOps now!”

How many of you just cringed?
Continuous integration is behavior, not Jenkins, CircleCI, Travis, or any other tool. CI is how we apply these tools and CI is the key to transforming teams. However, to be effective, we need to be explicit about CI definitions and how we measure our ability to execute.
Ubiquitous Language
Each developer submits tested, backwards compatible changes that are Integrated to the trunk at least once daily.
This definition creates constructive constraints and rapidly uncovers cultural, technical, and process challenges. Asking continuously, “Why can’t we do this?” drives the improvement conversation. The common challenges are basic but take discipline to solve.
- Workflow isn’t managed correctly with too many things in progress, lack of prioritization, and lack of teamwork to drive things to completion.
- Work hasn’t been refined to the detail required to deliver it.
- Testing is manual, requires handoffs to a testing team, or just doesn’t exist.
All of these impact quality and delivery speed. To fix them, we start with some simple improvements.
Establish Policies
Explicit policies are important for keeping everyone aligned. Keep them concise, clear, and always visible. Policies stored on a file share do not exist. Print them and post them.
CI Working Agreement
A working agreement focused on CI highlights the real priority, sustainable delivery of decreasing batch size with high quality and rapid development feedback.
- Fixing a broken build is the team’s highest priority because we cannot fix production with a broken build.
- The team will not go home while the build is broken because it puts production at risk.
- We do not blame team members for broken builds. The team is responsible for hardening the build process against breaks so the team broke the build.
- All branches originate from the trunk and are deleted in less than 24 hours
- All changes must include all relevant tests and may not break existing tests
- Changes are not required to be “feature complete”
- Helping the team complete work in progress is more important than starting new work
- No work may begin before it meets our “definition of ready”
This will not happen on day one. The team should be asking daily, “what’s the main reason we cannot do this?” and apply fixes until they can.
Definition of Ready
For any step, there must be exit criteria to prevent rejection from downstream steps. For refining work, it must be clear enough to prevent questions, guessing about what requirements mean, or gold plating during development.
- Acceptance criteria aligned with the value are agreed to and understood by the team and business
- Dependencies documented and solutions in place to allow delivery without them
- Any required research / training is complete
- Interface contract changes documented
- Component functional tests defined
With these policies in place, the team can begin removing other roadblocks.
Visualize Metrics
Until you know where you are, you cannot chart a path. Metrics are meaningless unless they are always visible. We use Hygieia to monitor CI outcomes, before that, we built Graphana views. No matter what method you choose, current metrics must be kept visible to everyone.
- How frequently are pull requests integrated into the trunk?
- What’s the average branch age?
- How long does it take to fix broken builds?
- How stable is the build?
- Is the build taking too long?
- How many tests are running and is that number increasing?
Track them, gamify them, make them better, and understand the goal is continuous improvement. Metrics are indicators, not goals.
Clear Impediments
Now the real work of changing habits begins. Habits change when previous habits no longer deliver value. When there is no pressure to integrate more frequently, re-refining work in progress doesn’t cause much pain. Integrating code once a week or longer with multi-hour code reviews and regular merge conflicts seems normal and acceptable. With our new drive to deliver code to the trunk daily, things must change.
Improve Refining
Improperly refined work has cascading impacts on quality outcomes. If work isn’t refined to the level of testable acceptance criteria, then there are too many uncertainties, and delivery pressure results in guesswork during development. This impact proper testing since poorly refined work drives developers into a constant “proof of concept” mindset with exploratory coding as the primary flow. It’s very common to see retry loops in a value stream map after development has started where developers are waiting on clarification. This, in turn, incentivizes increased WIP as they pick up new work while they wait and additional delivery delays as they context switch back or just park the original work until the lower priority WIP is completed.
Behavior Driven Development is an important tool for changing the culture and improving outcomes. BDD focuses on collaborating with all stakeholders to uncover the real business needs. Outcomes are owned by all of the stakeholders, not just the developers. We don’t finger point, we problem solve and focus on improvement. We also learn together that we’d rather fail small.
Simplicity — the art of maximizing the amount of work not done — is essential.
BDD gives us declarative, unambiguous acceptance criteria that can be tested. Now we have feature-level functional tests that decompose into component-level functional tests easily identifiable contract changes. We have a much higher level of confidence for what the business wants because they helped us define it and own the outcomes. We also know what NOT to develop since anything we develop beyond what we agreed to is a defect.
With a hard definition of done and clear delivery goals, we can easily swarm the work as a team. Which services will be impacted? Will new services be required? How can we collaborate to deliver those changes as a team?
Improve Testing Process
CI/CD is a quality process, not build automation. In a previous “5 Minute DevOps”, I spoke about the layers of tests required to execute CI/CD correctly. To add to that, two quotes from one of my favorite books.
“It’s interesting to note that having automated tests primarily created and maintained either by QA or an outsourced party is not correlated with IT performance. "
“Automated unit and acceptance tests should be run against every commit to version control to give developers fast feedback on their changes. Developers should be able to run all automated tests on their workstations in order to triage and fix defects.”
Excerpts From: Nicole Forsgren PhD, Jez Humble & Gene Kim. “Accelerate.”
Real CI requires that testing primarily happens before code commit. It also means that manual testing and/or handoffs to a “testing team” now are breaking us. We cannot meet our goals that way. Habits must change.
Since the team defined how the feature will work to a testable level during refining, all that’s required is to implement the tests. Instead of struggling to come up with what to test, developers can spend time designing HOW to most efficiently test against the goal. This results in more downstream improvement.
- Code reviews improve. There is no need to code review for functionality, that’s what tests are for. Code review can focus on readability and verifying that the tests match what was agreed to as a team. The tests validate the new functionality and protect that behavior on every subsequent build. As we reduce the time between merges, changes are smaller and code review is more effective and can be completed in minutes instead of hours.
- The increased confidence that we can make changes without breaking existing features makes development faster. We sleep better at night because we know we can triage and fix things faster at 3:00 am without risking breaking things even more.
- Test suites are less likely to become spaghetti code because we need our tests to run quickly. Test code is code and requires constant design and refactoring. The need for rapid test results helps this happen. Michael Nygard once told me that he created a test that would fail the test suite if it ran for longer than 15 minutes to force the refactoring of the tests. Brilliant.
Workflow Management
Individuals don’t win in business, teams do.
— Sam Walton
Imagine a football team where everyone was measured only by how often they scored. Everyone will be focused on getting the ball, scoring, and being a hero instead of helping the teammate who has the ball. The same happens on a development team.
Have you seen a team where everyone has assigned tasks instead of pulling work or where individuals are measured based on how many tasks they complete? With everyone focused on their task list or making themselves appear to be heroes, they aren’t focused on helping to deliver the next value item. You’ll see this in long wait times on pull requests, cherry-picking low-priority, easy-to-complete work, or increased work in progress. They look busy, but value delivery is minimal.
The teamwork expectations and time box constraints in the CI working agreement along with leadership understanding how to incentivize better outcomes result in lower lead time and increased throughput. The team only looks less busy.
Only Outcomes Matter
Working software is the primary measure of progress.
The customers only care about how quickly they can see value from the next feature. As development leaders, the goal is to help the teams find better ways to deliver value and to align the process in ways that encourage this. CI is an effective way to do this if the correct policies are in place. It provides easily measurable outcomes that allow rapid feedback for any improvement experiment. Because of the level of teamwork required to execute at a high level, it’s also an effective way for a new team to more quickly evolve from “forming” to “performing”. We’ve witnessed this repeatedly.
One note to this: Teams grow and learn as organisms. Team members are not LEGOs. Adding or removing anyone from a team reduces the team’s effectiveness. Team change should be done carefully and infrequently unless improved outcomes aren’t a goal.
Excuses
Some may assert that CI works quite well using an “integration branch” or GitFlow, that integrating every week or once a sprint is fine, or that only complete work should be integrated, I’ve heard all of those excuses before. I’ve also failed that way. Real CI drives real results. Culture changes because the underlying behaviors change. The reverse is never true. Don’t allow a lack of knowledge, lack of testing, or fear to prevent improvement. Fix the problems.
Written on August 5, 2019, by Bryan Finster.
Originally published on Medium
Removing Drama from Delivery

Has this ever happened to you or have you ever seen a support request like this?
“We’re trying to deploy a K8S cluster to our server, but it can’t reach our vLAN network. We’ve opened an incident with the NOC but we can’t solve this issue. We’d like to solve this problem by end of today. if it can’t we’ll be behind schedule and won’t release our new system as planned.
I’d really appreciate if someone could help us.”

Order of Operations
2 x 5 + 3 = 16…
Doing things in the wrong order leads to the wrong answer.
Large projects fail or are challenged because we focus on things in the wrong sequence and not constantly verifying the results. One of the goals of continuous delivery is to make sure the order of operations is correct.
1. Understand the value to be delivered
Developers cannot deliver quality if we don’t understand the value and goals. Context matters.
2. Build and deploy the first feature, “Hello world”
Deploy first. If you cannot deploy, then you cannot deliver the expected value and anything you cannot deploy is unfinished work waste. Even if what you build is entirely correct, if no one can use it or it’s delivered late, it’s still wrong. My first deliverable for any new UI or service is a health-check endpoint returning a simple object or a single line of HTML. Typically, lyrics from “Still Alive”.
3. Build and deploy the next Minimum Viable Feature
In a recent discussion, I explained that services should be deployed to production as soon as any non-breaking changes were available. The challenge back was that “the customer can’t use it yet”. That’s true, but we now have more confidence that it’s not going to immediately break anything when it’s complete enough to use.
Our focus is always stability and hardening the pipeline. We use new features to do that, but we need to keep those features as minimal as possible. Not only does this limit our blast radius when it fails, but it minimizes waste. If the customer asks for something and we deliver towards that goal in small pieces, there comes a point where the customer may be delighted with less than they thought they needed originally or they discover that was the wrong thing to ask for in the first place. In either case, we discover that with the least cost possible.
4. Adjust
It’ll be wrong. We make mistakes in what we ask for, how we define it, and how we implement it. So, we should aim to be minimally wrong. Deploy to production, check against the expected value, and do it again. The faster and smaller we can do this, the more confidence we have in the results.
5. GOTO 3
Picking up the Pieces Sucks
It’s too late to help someone when they’ve already driven off the cliff and are now desperate to find a way to get their months of hard work delivered. All we can do is pick up the pieces and help them understand what went wrong. Keep reminding people about the order of operations, because they may race to the deadline and get 16, but 30 delivers value.
Written on July 5, 2019 by Bryan Finster.
Originally published on Medium
Effective Testing

Protecting the Business
Developer-driven software testing is not new. Studies show that high-performing organizations depend on tests written by developers instead of handing off to external teams of “Test Automators”. Many vendors sell The One Test Tool to Rule Them All and promise to take the thought out of testing. I’ve seen repeated demos of tools with slick UIs designed to dazzle those with budget control that promise to make testing so easy that even external contractors with no context can do it. I’ve been told that only unit tests are the responsibility of the development team. I have even heard that for developer productivity testing should be given to testing teams because, “developers have better things to do and aren’t qualified to test anyway”. Wow!
These misguided beliefs put the business at risk. Customers do not care about anything but outcomes and the data is on the side of better outcomes coming from DevOps principles and the practices of CI/CD. Tools don’t solve that. Skilled, professional developers using effective tools do.
CI/CD == Test
For anyone wishing to master CI/CD, there are few areas of study more important than the effective use of metrics and testing.
The entire point of a CD pipeline is to safely deliver value continuously to our end users. Code must prove to the pipeline that it is worthy of delivery and the pipeline’s job is to prevent that delivery unless worth is proved and as fast as possible. To enable this, a product team should have the following priorities:
- Build and harden the CD pipeline.
- Keep the pipeline green. If there is a broken build, drop everything and fix it. If you cannot ship, nothing else you are working on matters anyway. Make sure that change can be delivered on demand to protect the ability to fix production without heroics.
- When (not if) a defect penetrates, harden the pipeline further by designing additional efficient tests for that defect.
- Write features and ship them daily to continuously test our ability to fix production with minimal MTTR.
- Get feedback about the status of the changes as fast as possible.
CI/CD is not tools. It’s how we USE the tools. If you are claiming to execute a CD process, then the following are true.
- All tests for any code change are implemented and verified before code is committed in version control. Test Driven Development is a good idea. Test DURING Development is a non-negotiable.
- There is only a single path to production for any code change, no matter how critical. We always use our emergency process and we always test the same way.
- Tests version with the code.
- Test may not be deactivated for an emergency.
- While there may be a button to push to deliver to production, there are no other manual stage gates, human intervention, or handoffs to external teams once code has passed code review.
If the above are not true, it doesn’t matter how well you can script Jenkins or how much you pay a testing team. You will never attain sustainable quality and you will be risking the business during every change, especially during an emergency.
The secret to CD is the right mindset: it’s always an emergency. We architect the pipeline to standardize work and remove manual touch points because at 3:00am when a dumpster fire is raging in production, VP’s are breathing down are necks, and we are operating on coffee and terror, we don’t want to forget steps in our “hotfix process”. We only use our standard process. It’s already a nightmare, so let’s not make it worse by cowboying changes in, ok?
All of the above have implications to how we architect our test plan.
Building a Resilient Test Plan
Your test suite needs to be hardened against the realities of the chaotic world. In a fantasy testing world, networks never have latency, external dependencies are always up and always stable, and the teams who own those dependencies never deploy breaking API changes without versioning. It’s fine to assume everything will work perfectly, until it’s an emergency and your assumptions are sadly mistaken. You MUST trust your tests. You must not accept random failures in your tests. Your critical path pipeline tests must work even when everything around you is falling apart.
The Table Stakes: Solid Unit Tests
Unit tests are absolutely the foundation. They are also where most developers stop. While unit tests are crucial, they need to be used for the correct purpose; black box testing of complicated, isolated units of code. Typically, we are talking about classes, methods, or functions at this level. For architecting a Continuous Delivery test suite, we want it to be fast and efficient. We want to target testing at risky behaviors. 100% code coverage is neither reasonable nor efficient. There’s no purpose in testing things like getter and setter methods unless they are doing something interesting. Testing Java’s ability to assign data to a variable isn’t useful unless we are developing the JVM. There are libraries full of good information on patterns and anti-patterns for unit testing. A favorite is xUnit Test Patterns. It’s a massive tome on proper testing and common anti-patterns that I highly recommend.
Meeting the Business Goals: Functional Tests
Unit testing will give a good view of how individual units will perform, but most applications are implementing some business flow. Testing that core business domain logic is critical and unit tests are ineffective at that. Many teams will jump immediately to End-to-End testing to solve this, but those are unstable (flakey test anti-pattern) and cannot effectively test all of the logic branches.
A better approach is using functional tests that independently test each business feature.
“Given I have £20 in the bank When I ask the cash machine for £20 Then it should give me £20 And debit my account.”
Excerpt From:Liz Keogh. “Behaviour-Driven Development.”
Here we have a single business feature that can be implemented by an account service. This takes no special tools to implement, only the thought process of “I need to test this flow”. Just like a good unit test, each functional test should be focused, be able to run in parallel, and should not directly integrate ouside the scope of the test.
Being a Good API Citizen: API Contract Tests
Communication interfaces are where most defects occur. It’s obvious then that we should prioritize testing those interfaces even before implementing the behavior behind them. This is where contract testing and contact driven development become important.
There are many poor ways of documenting API contracts, but only one correct way: contract tests and contract mocks documented and tested by the provider. A contract test in its basic form is a simple unit test of the shape of the contract.
Here’s a simple example:
404: Not Found
Playing Well With Others: Integration Tests
Contract tests give you a level of confidence during CI builds that you’ve not broken a contract or broken how you consume one but since they are mocked, they require another layer of test to validate the mocks.
Many people will use “Integration Test” to refer to the activity of testing business flows through several components, and End-to-End tests. Others use it to refer to the functional test I mentioned above. In the references I mention below, they will refer to integration testing as the act of verifying communication paths between components; a shallow test where the consumer asks, “Can I understand the response from my dependency?” The test should not attempt to test the behavior of the dependency, only that the response is understandable.
Integration tests have a weakness that architects of CD pipelines need to understand: they are flakey. You cannot promise that the dependency will be available when the CD flow executes. If that dependency is not available, it’s still your team’s responsibility to deliver. Remember the rules of CD above. You are not allowed to bypass tests to deliver. So, we have a conflict. How do we design a solution?
Step 1: Service Virtualization. Using Wiremock, Mountebank, or other related tools we can virtually integrate. These tools can act as proxies for actual dependencies and the better ones can replicate latency and handle more than just HTTP. In addition, they reduce the need for the test data management that is required for all but the simplest integration tests. Data is the hardest thing to handle in a test, so avoid it.
Step 2: Scheduled integration tests. When direct integration testing is needed, run it on a schedule outside the standard flow. Build alerts to tell you when it breaks and follow up on the causes for the breaks. If the dependency is unstable, keep track of how so you can rapidly detect when it’s their instability vs. a breaking change they made or a problem with your virtual integration tests that needs addressing.
Using this method, you can reduce much of the flakiness of typical integration testing as well as repeatedly and quickly test for complex scenarios that cannot effectively be tested with less refined methods.
Verifying User Journeys: End-to-End Test
End-to-End testing tests for a flow of information and behavior across multiple components. Beware of vendors selling record and replay testing tools that purport to take the load off of the developer by simply testing the entire system this way. However…
The main problem with Recorded Tests is the level of granularity they record. Most commercial tools record actions at the user interface (UI) element level, which results in Fragile Tests
Excerpt From: Gerard Meszaros. “xUnit Test Patterns: Refactoring Test Code**
End-to-End tests are not a substitution for properly layered tests. They lack the granularity and data control required for effective testing. A proper E2E test will be focused on a few happy path flows to verify a user journey through the application. Expanding the scope of an E2E into the domains better covered by other test layers results in the slow and unreliable tests. This is made worse if the responsibility is handed off to an external test team.
What Didn’t We Test?
Exploratory testing is needed to discover the things that we didn’t think of to test. We’ll never think of everything, so it’s important to have people on the team who are skilled at breaking things and continuously trying to break things so that tests for those breaks can be added. Yes, this is manual exploration but it’s not acceptance testing. If you use a checklist, you’re doing it wrong.
Will it Really Operate?
Load testing and performance testing shouldn’t be things left to the end. You should be standing those up and executing them continuously. There’s nothing worse than believing everything is fine and then failing when someone tries to use it. Operational stability is your first feature, not an afterthought.
Entropy Happens
- What if that critical dependency isn’t available?
- What happens if it sends you garbage?
- Cloud provider reboots for an upgrade or has an outage?
- Excessive latency?
- Coronal Mass Ejection?
The world is a messy place. Resiliency testing verifies that you can handle the mess in the best way possible. Design for graceful degradation of service and then test for it.
Testing Ain’t Easy
Proper testing takes the right mindset and at least as much design as production code. It takes a curious, sometimes evil, mind and the ability to ponder “what if?” Proper test engineers don’t test code for you; they help you test better. Tests should be fast, efficient, and should fully document the behavior of your application because tests are the only reliable documentation. If you aren’t confident in your ability to test every layer, study it. It’s not an added extra that delays delivery. It’s the job.
If you’re a professional developer and student of your craft, here’s more references for deeper learning:
- Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations
- Continuous Delivery
- Practical Test Pyramid
- xUnit Test Patterns
- Charting a path to software resiliency
If you found this helpful, it’s part of a larger5 Minute DevOps seriesI’ve been working on Feedback is always welcome.
Written on June 18, 2019 by Bryan Finster.
Originally published on Medium
GitFlow Best Practices
I was asked recently about the best practice for using GitFlow with continuous integration. For those who do not know, this is GitFlow:
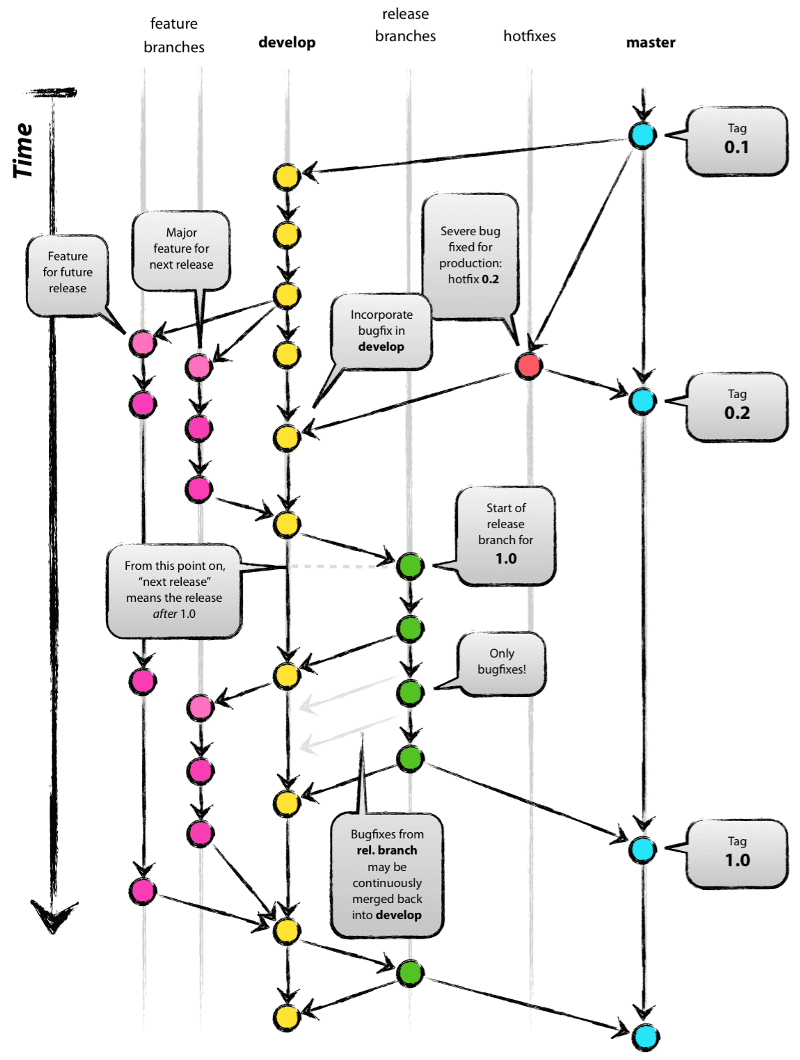
There is no CI good practice that includes GitFlow. For continuous integration to meet the definition, these are the good practices:
- Developers must implement all tests before they commit code. This is a non-negotiable and I will not work with developers who refuse to test. Professionals deliver working, tested code. Script kiddies don’t test.
- Stand up CI automation and trigger builds for every pull request so that bad changes can be rejected.
- Ensure that all tests are executed and linting and static code analysis is done for every PR.
- Implement CI practices. All developers branch from the trunk, make changes, and submit PRs back to the trunk. The branches are removed in less than 24 hours.
You’re now doing Trunk Based Development. Welcome to your CI/CD journey!
The complexity of the CI automation will depend on how poorly the application is architected and the size of the development team. Monoliths with poor sub-domain boundaries will require much more complicated test design and test execution will take much longer. Evolve The architecture into independent, loosely coupled sub-domains to improve delivery speed, reduce testing overhead, and improve stability, resilience, and scalability.
GitFlow does not increase quality or value delivery. It delays quality signal feedback to the developers, incentivizes manual processes, and is incredibly wasteful of time and resources. No modern development uses it.
Some developers have a religion built around GitFlow because it reduces typing (no feature flags needed, no branch by abstraction cleanup, etc.) and they don’t track their levels of re-work, lost changes, or conflict resolution. In 2010, GitFlow felt good. We could keep Master “clean”. That was almost a decade ago. Testing was still mostly manual. We were still on Java 6. NodeJS was barely a thing. Time to modernize. We don’t keep Master clean with added process. We keep it clean with automation.
Other examples:
Update March 2020: I asked the author of GitFlow if he could clarify the use cases to stop the GitFlow whack-a-mole and he very helpfully did so, Please thank him.
**Update September 2021:**A friend recently joined Atlassian and I asked if he could get them to update their GitFlow docs. They did.
Written on April 6, 2019 by Bryan Finster.
Originally published on Medium
Designing Product Teams
What does a product team really looks like? You’ll hear lots of DevOps-y buzz words: “T-shaped people”, “cross-functional”, or “Two Pizza Team”. So, what is a viable product team and what are some common team anti-patterns?
First, a personal irritant of mine.
<rant>
Please stop saying "DevOps team." DevOps isn't a job. If you have a "DevOps team" doing release management or support
for you, spend time educating people on flow, feedback, and learning.
</rant>
Now that we’ve cleared that up, a product team has a few recognizable traits:
Cross-functional:
The team contains the skills and tools to allow them to build, deploy, monitor, and operate their portion of a product until the day when it is turned off. Team members have no individual responsibility for components, instead they pull work from the backlog in priority sequence. The team is not dependent on any outside dependencies, either technical, informational, or process, to deploy their product. If there are hand-offs then quality is reduced, MTTR will be too high, and the team will not feel the pride in ownership required for quality outcomes.
Anti-pattern: Release management team
Having another team responsible for deploying code prevents the product team from committing to deliverables and increases MTTR. It also makes release challenges opaque and prevents the team from improving their delivery flow effectively.
Anti-pattern: External QA
Outsourcing testing reduces quality and delays delivery. QA should be inherent in the team and should assist developers with test suite design to enable feedback from CI builds in less than 10 minutes.
Sole Source Ownership
The team has sole ownership and commit access to their repositories. This does not imply that the repositories should be private. Repositories should be openly readable unless there is a security risk. Teams need veto power over any change made by an outside contributor to make sure those changes meet the team’s standard of quality. Quality is owned by the team. Larger products should be divided among teams in a way that allows each team to have sole quality responsibility.
Anti-pattern: Shared source repositories
Everyone who has the ability to modify a repository directly is the de-factoteam. If that team is broken up into smaller “teams”, then process and communication drag will impact quality and the ability to deliver with agility. CI will not function and quality standards will be impossible to enforce. Delivery is delayed as process overhead increases in a failed attempt to overcome this structural problem.
Co-located in Time
The team works a schedule that enables them to effectively collaborate. They need not be co-located physically, but they must have enough overlap in working hours to allow a sustainable continuous integration process. Paul Hammant has an excellent article on evaluating your CI process. As the amount of overlapping working hours decreases, the communications lag between team members effectively silos the team. Team members will naturally divide into sub-teams who can collaborate together to deliver. Remote teams should be in frequent contact to avoid this fragmentation. The team needs to stabilize around working hours that support CI and protect value delivery.
Anti-pattern: Teams siloed in time
CI is the core of continuous delivery and requires a high degree of collaboration. The feedback loops needed to move value from idea to production must be as rapid as possible. If a team is divided in time in a way that they cannot effectively communicate instantly for a majority of their day, they become de-facto separate teams. These “teams” do not have sole quality ownership and delivery times will be extended as the “teams” adjust by adding process overhead that allows both “teams” to review the code. Over time, the sub-team cultures evolve independently and impact code review cycle time. Innersourcing processes can mitigate the quality issues by making only one of the teams a contributor instead of owners, but there is an increase in process overhead.
Responsible
The team has primary support responsibility. There are only two groups related to any product who care about the quality of that product, the end users and the product team who wakes up when things break. A high performing product team will ensure that their application has the resiliency, instrumentation, and alerting required to detect pending failure before the end user detects it.
Anti-pattern: Grenade Driven Development
Project teams require support teams to hand the project off to. Project teams are ephemeral. This type of development practice where code is developed and “thrown over the wall” for another team to support is destructive to the product and to the morale of the victim team. Product teams, by definition, have operational responsibility. They may not be the first people called, but only they can approve changes to their code. It’s up to them to make sure Operations has the information needed to alert the team effectively.
If the above principles are not true, it’s not a product team. It’s merely a “Pandemonium of Developers”.
Other considerations
Having a cross-functional, co-located, responsible team with ownership is a good start, but it’s only part of the problem. To keep deliverables fast, cheap, and high quality, it’s important to minimize inter-team dependencies. Teams need to deliver independently in any sequence. This takes planning before we form a team. What is our desired architecture? Which functional domain will each team be responsible for? Things become more complicated here because, like many other things in application design, “it depends”. It also requires technical skills from the team with a focus on API management, Contract Driven Development, and an understanding of effective feature toggles.
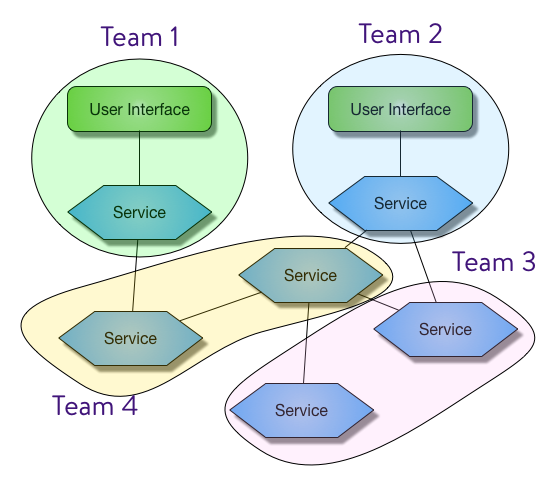
Functional Domain
Domain Driven Design isn’t just a good idea, it’s an excellent way to align teams. As we decompose a product into sub-domains or as more functional domains emerge, we should be deliberate about assigning those capabilities. Things that should be tightly coupled should be assigned to the same team. Things that should be loosely coupled should be separated. If I’m using a back end for front end pattern, the UI and the service should absolutely be on the same team. Otherwise, the dependency drag for implementing any change will result in glacial delivery. If I also need the capability of tracking account transactions, I can easily assign that to another team and allow them to develop that solution independently. In that case, we assign the capability based on capacity planning.
Desired Architecture
The impact of placing two capabilities on one team is that they will tend to become entangled. That can be as simple as becoming a single deployable or as complicated as functionality drifting across interface boundaries. If the capabilities are closely related, this can be an advantage. Combining them into fewer deployable artifacts can result in less operational overhead. Microservices aren’t always the answer (avoid Conference Driven Development). However, if the capabilities are unrelated and things start to merge, you’ll need to invest in marinara before you tackle refactoring the resulting spaghetti.
Vertical or Horizontal?
“Do we create a UI team and one or more service teams? Do we divide the UI across teams?”
Take a look at your wireframes. Are there discrete functional domains represented in the UI? A component for showing stock prices, one for showing account balances, and another for scheduling bill payments? Those can easily be developed in functional pillars and developed and deployed independently. Aligning teams to a business domain instead of the tech stack removes hard dependencies to feature delivery and allows the teams to become truly full-stack. Not only do the know the full technical stack, but they also own the entire problem they are solving. They know the business stack.
This isn’t always possible and it does sometimes make sense to have a UI team, but that should be a fallback position. Better outcomes come from a team who is expert in their business domain.
Is it really a team?
Product teams deliver quality. They care about their team, their product, and their ability to meet the needs of the customer. Random assemblages of developers taking orders do not. It falls to technical leaders to know the difference and to optimize teams for delivering business value. Grow your product teams. They are a strategic business asset that are required to compete in the current market. Happy developers with tight collaboration who are experts in their problem space can work miracles. “Development resources” do not.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author! ⬇
Written on February 7, 2019 by Bryan Finster.
Originally published on Medium
You Don't Need Story Points
In my last 5 Minute DevOps, I attempted to define user stories in a testable way. Real developers should test, after all. Now that we have a story, how do we communicate when it can ship?
We have a long history of attempting to communicate the uncertainty of outcomes to non-technical stakeholders. We speak in delivery probabilities, not certainty. It can be frustrating to those who don’t understand, but software development is not cookie cutter and managing expectations is key when uncertainty is high.
T-shirt sizing, ideal days, and story points have all been used in an attempt to communicate how complicated or complex something is and our certainty of the date range we can deliver on. However, the issue they all share is that they leave much to interpretation. This in turn leads to hope creep as stakeholders start planning optimistic dates.
Story points are particularly troublesome. Teams just starting out will equate story points to hours or days. External stakeholders will do the same. Managers will try to “normalize” story points to compare teams’ relative productivity with their velocity, a staggeringly poor metric. In the end, no one sees any real value.
So, what is a story point really? It’s a statement of relative size and complexity compared to a task the team understands and can estimate. You cannot “normalize” them because no two teams have the same knowledge or experience. The bigger the story point size, the less certain and more complex. Uncertainty also isn’t linear. We use the Fibonacci sequence because it increases with the square of the number.
That clear? Good. Now forget it because no value is delivered by continuously improving how we “point” or by spending time in meetings voting on how many story points something is. Time is much better spent in extracting the real requirements by decomposing the work into tasks that can be delivered tomorrow.
One of the key practices of DevOps is decreasing batch size. Not only does this accelerate value delivery, but also reduces the blast radius when we get things wrong. Small change == small risk.
Paul Hammant argues that most stories should be sliced to one day. If you cannot, then you have the wrong people, wrong tech stack, wrong architecture, or just poor story slicing skills. In my experience, all stories can be sliced to less than three days. Any estimate becomes shaky after two. The benefits to clarity of purpose, speed to market, and predictable delivery demand that we aim for small stories.
We’ve seen good results following this process. Small stories make requirements clear, deliver predictably, and resist gold plating, scope creep, and sunk cost fallacy. If we agree that a story can be delivered in two days, on day three we know there’s a problem we need to swarm. If a story is 5 “story points” it’s probably at least a week’s work and we’ll find out in the middle of week two that it’s late, if we are lucky.
Forget story points.
A skilled team can slice stories so that everything is a “1” or a “2”. At that point, all we need do is agree as a team a story can be done in that time range and track the throughput of cards. Anything else is focused on ceremony instead delivery.
If you are using story points, you need to focus less on getting better at “pointing” and focus more on what really delivers value. Decompose work and ship it.
Next time: Are You a Professional Developer?
Written on January 31, 2019 by Bryan Finster.
Originally published on Medium
What's a User Story?
What is Pragmatic DevOps? It’s just a catchy way of saying we deliver with Minimum Viable Process using lean techniques to drive waste out of the system. If it helps us deliver and support our product, it’s good. If not, we remove it.
One of the bigger problems we’ve seen in many companies moving to agile development is the fact that the people leading the change are typically not currently developers. Many took classes on “Agile” to become “Certified”, but the real world examples people need to translate their current processes to delivering with more agility rarely come from books. How many of the signatories of the Manifesto for Agile Software Development are certified?
Have you heard variations of discussions like this? I have.
Dev: “What’s a user story”
Certified Agile Coach: “It meets INVEST, obviously. Also, it has a persona and a value statement.”
Dev: “Invest?”
CAC: “Independent, Negotiable, Valuable, Estimable, Small, and Testable”
Dev: “OK, so the business won’t use anything until it’s all done, so the entire application is a user story?”
CAC: “Well, no. It’s smaller than that, obviously!'
Dev: “Well, I can’t negotiate anything smaller and it has no value otherwise so..”
And so on, until the contract runs out and the Certified Coach collects their fee and starts their next contract. Right after that comes the “story point” conversation.
The outcome of this is teams sitting in meetings parsing words and coming up with “As a developer, I want a database, so that the application can store data” and then arguing how to estimate it.

As a practitioner of Pragmatic DevOps, testable definitions are required to effectively onboard developers who are new to continuous delivery. To meet the goals of CI/CD and to deliver predictably, we need to deliver tiny batches of work that we can demonstrate and get feedback on. It’s also very important that we are able to effectively communicate using ubiquitous language that all stakeholders understand. In that vein, we use the following definitions when helping teams and external stakeholders understand Features, Stories, and Tasks.
Feature: A complete behavior that implements a new business process and consists of one or more user stories. If your feature is too big, then you risk delaying a change that could add value immediately, so keep the features as small as makes sense.
User Story: The smallest change that will result in behavior change observable by the user and consists of one or more tasks. If the change is not observable, it cannot be demonstrated. If it cannot be demonstrated, there’s no feedback loop and you cannot adjust with agility.
Task: The smallest independently deployable change. Examples: configuration change, new test, new tested function, table change, etc. A task may or may not implement observable change, but it is always independent of other changes. If a task cannot be deployed without another task, then change priorities or learn how to use feature flags.
Keeping the language simple and minimizing the ways definitions can be interpreted is key to effective skills training. We recommend starting a glossary and testing the definitions. If they create confusion, refactor them.
Coming next: You Don’t Need Story Points!
Written on January 11, 2019 by Bryan Finster.
Originally published on Medium
2018
Building Team Maturity Using Continuous Delivery
Using Delivery Constraints to Drive Improvement

Accelerating delivery is a key strategic initiative for any company wishing to remain relevant with today’s rate of change. When teams start the journey from “artisanal development” to continuous delivery, they rarely understand the level of improvement they will achieve when they reach daily delivery and beyond. Maturity doesn’t come from waiting, it comes from doing. Consider this journey. Where are you on it?
Quarterly (or longer) Delivery

We can do this with any process, even Waterfall or ad hoc. At the end of the quarter we discover how much of that delivery was unneeded, misunderstood, or of such poor quality that we plan for support impact as part of the roadmap. Generally, heroics are needed to recover or we extend the roadmap and explain “that’s how software development works” to our customers. Using “Agile Methodology” becomes a way to update management in two week increments so they can report if we are trending “green”, but there is minimal value being delivered from “Agile”.
Monthly Delivery

To gain more trust from our customers, we decide to deliver monthly. As we do this, we discover that our “stories” are actually one or more complete features in “story format” that do not meet INVEST. We measure cycle timesand focus on reducing those to less than a week. That requires us to focus on the core value of every feature, drive out “gold plating”, and defer features that aren’t the highest priority. We start having more conversations with the customers about their goals, become more knowledgeable about the business, and bring them closer to the team.
We find that split attention and multi-tasking are slowing things down. Even though “we do Scrum”, we implement WIP limits on a physical kanban board to focus the team’s efforts on finishing things. This encourages teamwork to finish high value items instead of ensuring everyone is assigned tasks.
Metrics show the estimates are wildly inaccurate on anything but tiny items, so we start complexity estimation to identify stories that require more breakdown to remove uncertainty.
Handing off to the QA department for test automation or manual testing has been adding lag. Deliverables slip and heroics are required to meet commitments. Quality flowing into QA is so low that reported defects keep putting delivery at risk. We start researching “driving test left” and realize that extending coding time to include proper developer testing reduces overall delivery time due to faster test execution, less spaghetti code, and higher quality. We learn to optimize for the system and not locally for the developer. We begin focusing on unit testing and integration testing written during development.
Our code reviews are another pain point. formal code review meetings or requiring the tech lead to review all code adds process overhead that encourages larger changes. When we look at the process we find that proper testing and static code analysis with a very light review for testing behavior and readability is more than enough.
Weekly Delivery

After getting our cadence down to monthly, we are starting to see some improvement, but we are still not getting timely feedback on features and it takes months to get a new request through the process. Not only does this make us appear unresponsive to business needs, but priorities constantly shift and sprint plans are often disrupted. In addition, production defects are typically weeks old and require extended triage. We decide shorter cycle times might allow us to more cleanly shift as priorities change. We also predict it will take less time to find root cause due to the smaller change size.
During retrospective we list items that we think may be slowing things down:
- Every install has required a change approval process and that process is taking a team member several hours of work spread across several days while they chase down approvals from several levels of management.
- We’ve been using long running feature branches to isolate changes and integrating to an intermediate branch for additional testing before we release. We decided before that GitFlow was the safest way to work, but it’s taking significant manual effort to execute relative to a trunk-based flow. This is encouraging long integration cycles which is making each code review so big that things are easily missed.
- Many of our stories are requiring additional requests for information which is impacting test development.
- Our integration testing is taking too long and changes need to be sequenced to keep those tests from breaking.
- Our End-to-End testing is taking significant team capacity to execute and to keep current. In addition, there are changes happening fast enough that the End-to-End automators are struggling to keep it current.
To resolve the change approval overhead, we work with management to identify the value they are trying to achieve. They believe that they can identify bad changes with the process, but when we show them data of changes they approved that caused impact and point out that they were too far removed to make effective reviewers, we agree that we can automate a “change notification” process and that the team will use the extra time to find new ways to automate defect identification before production.
With feature flags and expanded developer testing, we can move to Trunk Based Development and we update our working agreement to integrate feature branches to the trunk every few days. This is our first step to real continuous integration and we start dreading code review less. This highlights some other issues with our stories though. They are still too big and many have dependencies on other stories. We keep working to drive the size down and make sure they represent a very small request and response from a user. Our goal is no story requiring more than 3 days to complete.
To address uncertainty for story implementation, we decide to use BDD to uncover requirements and aid in story breakdown and estimation.
Testing effort is becoming apparent as well. It’s taking too long to find integration issues and the End-to-End testing is really hurting our capacity. To address these, we start implementingcontract tests to back up the integration testing. We also re-design our integration testing to focus on communication between pairs of components instead of the overall behavior of two or more components, since that’s just another End-to-End test. For our End-to-End tests, we focus on value we are wanting to achieve. We start to identify what we are trying to discover with E2E and find that a majority of that can be done with component functional testing. That would allow developers to build and execute those tests before committing code and to get feedback instantly instead of waiting for the build to find issues. Adding the BDD process to story refining makes this much easier to do. We begin reducing our E2E footprint.
Daily Delivery

We’ve seen some real improvement moving to weekly delivery. It’s taking much less lead time to get features from idea to production. We’ve even started predicting and measuring value delivered, our first steps to hypothesis driven development. We have a test suite that gives us confidence and it’s giving us feedback from the pipeline in less than an hour from the time code reaches the trunk. We still have some extra process required for resolving production issues and our MTTR, the time from a production issue occurring until a fix is applied, is more than 2 hours.
During retro, we identify some things impacting our MTTR:
- If we can reduce our build and test time, it will take us less cycle time to apply a fix.
- Smaller changes make it even easier to locate issues early, but our three-day story size means many changes are still pretty big.
Examining our architecture, we see many opportunities to break things up into smaller components. Not only will that make each one faster to build and test, but it will enhance or horizontal scaling and reusability. With our improved monitoring, contract testing and integration testing maturity, we can begin dealing with more moving parts. However, the first step is more test optimization. When we look at the metrics, our integration testing is fragile when we integrate with external dependencies. It’s also requiring complicated data setup when executing a PUT, POST, or DELETE test.
To resolve the testing constraint, we bring in service virtualization tools. We start with internal services as a proof of concept and then sell the value to other teams we depend on. This accelerates testing in the build considerably by removing the risk of service unavailability and removing the complexity of the test data management.
To take advantage of this speed and accelerate value delivery, we start focusing on driving most story sizes down to one day of effort. Not only does this drive even more focus to the core value of the story, but the business starts seeing usable value even faster. This speed of delivery expands the trust and partnership with the business to new levels and they begin running small feature experiments instead of trying to dump everything into a single batch of change.
The results are what we expected. Our MTTR drops significantly. Not only is breaking change easier to locate, but it’s easier to reason about because smaller, tested changes result in more concise code. Build times are reduced and we no longer need to have a risky snowflake process for fixes or wake up other teams when their components are unavailable for integration testing when we are trying to verify and deploy a defect fix.
Daily Delivery per Developer
We have high morale. We’ve seen that we can make significant improvements to our quality of life though disciplined improvement of our delivery cadence. Production impact is way down and we are running experiments to find better tools or architecture patterns to make our product easier to deliver. Everyone on the team understands the expectation that every change is destined for production and needs to be solid before commit. We are making suggestions to the business for new features we think the customers will enjoy and the business is prioritizing those. Our integration testing is virtualized. Contract breaks are found seconds after they happen during coding. We’ve been expanding our use of feature flags so that we can activate features on demand after they’ve been deployed. We have boring, drama free installs. Removing the authorization in the pipeline, we enable continuous deployment.
Common excuses for not executing CI/CD
“We don’t need to release features every day”
Standardized daily deployment isn’t about feature delivery. Features are a tertiary priority. The primary reason for daily deployment is that it provides a safe way to deliver production impacting fixes. How many times have you attempted to repair production only to have that repair cause additional impact? In my career, I’ve seen it countless times. Root cause for the additional impact is typically nonstandard process and bypassing quality for the sake of speed. That’s never an appropriate action. Having a standardized, automated, and fast way to verify a code change and deploy it without human touch protects our business when minutes count. It isolates defects to the only thing humans should do; committing code to version control.
“We aren’t mature enough”
Maturity doesn’t come from time, it comes from practice. You don’t “become” mature at Scrum, Kanban, or CI; you get better at them. If you don’t start, you won’t get better. If you don’t have an improvement goal, you won’t get better. Driving down delivery cadence builds high performing, high morale teams. A high performing team who are experts of their domain and have the discipline to automate everything possible and focus on improvement is a strategic asset. How many do you have? How many do you want? Having worked on one, would you volunteer to go back to a team that cannot deliver as quickly? You don’t need, or even want, teams of “rock stars”. You have the people who can do this on your teams now. Give them the tools, training, goals, and freedom. Let them run!
Reducing delivery cadence is the driver of maturity, not something that mature teams decide to do.
Written on July 22, 2018 by Bryan Finster.
Originally published on Medium
The Cost of Ignoring UX

In 2018, I’m a relatively recent convert to the need for team members who drive UX, the user’s experience. I often hear people confuse “User Experience” with “User Interface”. UX is much more than that. The UI could be a work of art, but if the user feels that the response time to get information is too long, that’s a UX failure. If it takes too many key presses or mouse clicks to navigate, that’s a UX issue. If the behavior changes in confusing ways, bad UX. Not paying attention to UX details can easily contribute to lost sales and declining profits.
As a proud Texan, I’m a lifelong Dr. Pepper drinker. In an emergency, I’ll resort to Coke. The piles of 20oz bottle that fuel me at work are a testament to my dedication. Recently, one of our soda fountain machines, the one vending Dr. Pepper, was replaced with a new touch screen version with exciting flavor choices. It’s modern, and fun, but there are UX challenges.
Old machine:
- Place the glass under the nozzle and dispense.
If the foam begins to exceed the capacity of the cup, stop dispensing, wait, and resume. Easy. Intuitive. Exactly one action to achieve my goal, a full cup of refreshing Dr Pepper.
New machine:
- Click to close the notice that there are new flavors.
- Select diet or regular. (Diet)
- Select Dr. Pepper.
- Place the glass under the nozzle and dispense.
Four steps. If the foam gets too high and you wait, the machine resets and you must start over again to finish topping off the cup. Next to the machine is an older machine that vends Coke with the older user interface.
I now drink Coke in the cafeteria.
Making things harder, adding friction, inserting steps, or slowing things down changes behavior even faster than doing the opposite. People take the path of least resistance and once you lose them it’s very difficult to get them back.
When designing any product, the consumer should always be foremost in our minds:
- how can I make this appear fast and engaging with minimal friction for the user?
- If a dependency fails, how do I degrade in a way that’s least likely to result in lost sales or alienated users?
- Are we paying attention to every keypress and mouse click?
- Are important pieces of information obvious and easy to find?
- Is there too much information?
- Too little?
Details matter.
Put yourself in the place of the end user. Eat your own dog food. Be critical and remember your competition. Be the customer or they may not be yours.
Written on July 12, 2018 by Bryan Finster.
Originally published on Medium