Schrödinger's Pipeline
3 minute read
In the lifecycle of most applications there comes a time when they will go into maintenance mode where changes become very infrequent. This is even more common for utility services that are simple, but business-critical to multiple products. There is one thing that should never be skipped, a well-constructed delivery pipeline that fully exercises the application to verify it won’t break production. Having this in place means that future developers, even when they are us, have a clear path to deploy new changes with low risk. In fact, that pipeline and the effectiveness and efficiency of the quality gates should be the primary product for any team delivering business-critical applications and that pipeline must always be green or any changes to that code are just undeliverable waste.
When we are developing the application initially, there is a flurry of change. If we are doing CD correctly, those changes are verifying the pipeline is green daily. Later on, fewer changes are required as focus shifts to another domain in the product. What’s the impact of this?
Several years ago, a group of us were exploring the techniques of continuous delivery, we focused on pipeline construction, development practices, testing, and the metrics of delivery to see how we were progressing. We were doing this with a combination of existing legacy applications and greenfield development focused on exposing legacy logic and improving the user experience. This was a multi-team effort with a few of the teams also uncovering CD good practices to share with the broader organization. As the development effort evolved, one of the teams created a NodeJS API to wrap legacy ESQL/C code to expose the 20+-year-old core logic to the application being written by my team. There were many hard-won lessons. We even independently invented service virtualization to bypass the need for a 4-hour process to set up test data for an End-to-End test. After the API was stable, the focus moved elsewhere with no API changes required for several months. However, time passes quickly outside of the pipeline.
One day, a new feature required an API change. It was estimated that the new change would be ready for production in less than 2 days. My team’s application would be ready to use it later that week. Since we had a solid contract change process we were able to work in parallel based on mocks. However, when the API team’s first code change triggered their pipeline, they got a nasty shock. One of their core dependency libraries had been blacklisted for critical security vulnerabilities and the next available version introduced a breaking change. Major refactoring was required to upgrade the library before that simple change could be applied. A 1 to 2-day task stretched for a couple of weeks.
After the changes were finished, we had a CD post mortem. What happened? What can we do to prevent that from disrupting the flow of delivery in the future? The remediation plan we came up with was quite simple. We decided it’s not enough to trigger a build when the trunk changes, so we created scheduled jobs to build every pipeline weekly. There’s very little risk in deploying code that hasn’t changed to verify the pipeline is still green. Risk and uncertainty increase the longer the duration between builds.
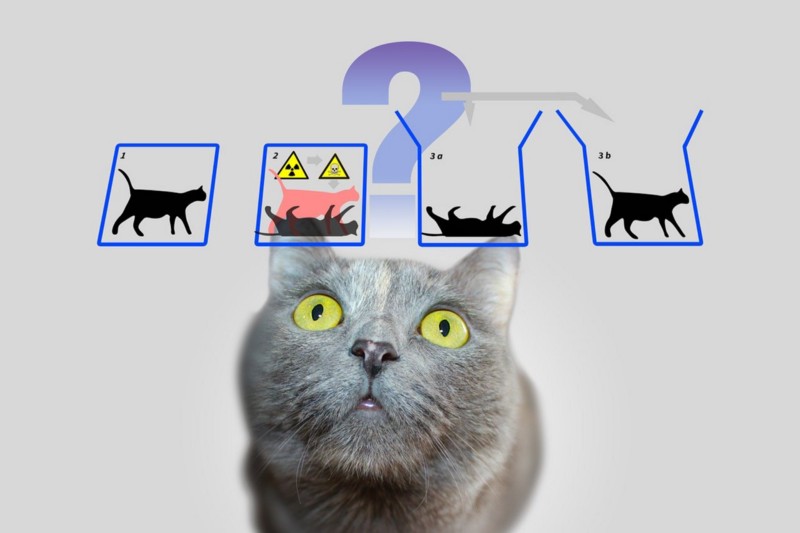
Every delivery pipeline is focused on reducing risk. Any uncertainty in the pipeline must be aggressively weeded out. Long dormant pipelines are exactly like Schrödinger’s cat. They might be red and they might be green. Until they run and report the results, they are in the superposition of both red and green (brown?). Exercise them to collapse the function.
Written on May 31, 2020 by Bryan Finster.
Originally published on Medium